Fast Scraper
Pricing
$5.00/month + usage
Fast Scraper
Fast Scraper is a blazingly fast web scraper powered by Rust on the backend. It allows you to scrape static HTML pages extremely quickly while using only <128 MB of memory. With this scraper, you can maximize the efficiency of your credits on Apify.
Pricing
$5.00/month + usage
Rating
0.0
(0)
Developer
Daniel Herman
Maintained by CommunityActor stats
3
Bookmarked
5
Total users
1
Monthly active users
2 years ago
Last modified
Categories
Share
What is Fast Scraper?
Fast Scraper is a blazingly fast web scraper powered by Rust on the backend. It allows you to scrape static HTML pages extremely quickly while using only 128 MB of memory. With this scraper, you can maximize the efficiency of your credits on Apify.
Why Choose Fast Scraper Over Cheerio?
Fast Scraper is blazing fast and will save you money. 🚀🚀🚀
Cheerio is powered by Node.js, meaning all the heavy lifting is done by JavaScript. JavaScript was never meant to be used as a scraper in the first place. It's similar to creating a rollercoaster game in an Excel sheet. 📉 📉 📉
How much will scraping with Fast Scraper will cost you?
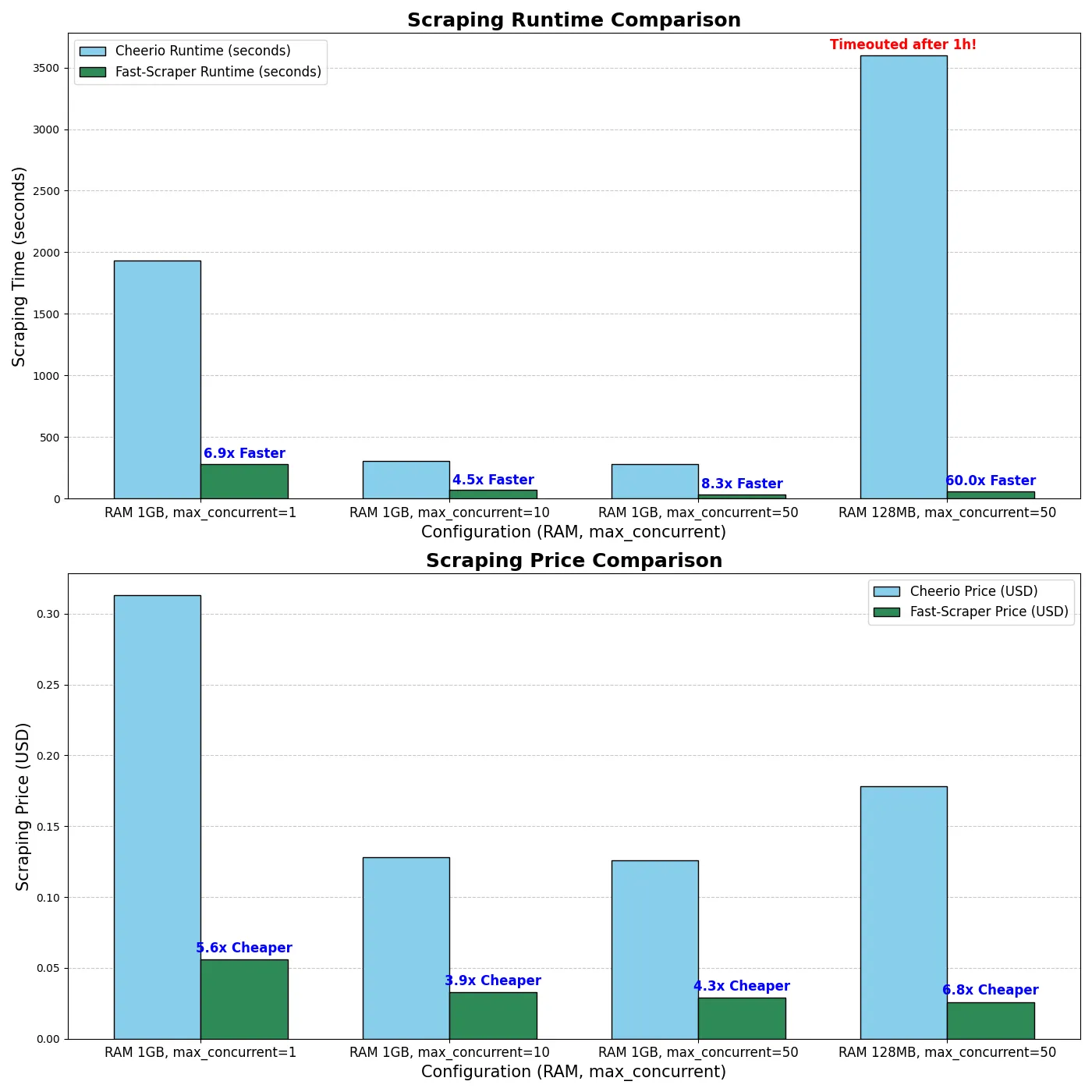
I did a benchmark where I scraped with max_concurency=50, 128 MB RAM and 1000 (52MB) csfd.cz pages the whole page and it cost me 0.026 USD and ran for 60 s. So it is very cheap. That would make roughly 38 500 (2GB) scraped websites for $1.
How much cheaper and faster?
Here is a comparison performed on 1,000 csfd.cz pages. The entire static HTML was scraped and stored in storage. With Cheerio, using 128 MB of RAM, the process timed out after 3,600 seconds because the scraper actor required more RAM. On the other hand, Fast Scraper only needed an average of 33.2 MB of RAM and 0.88% CPU usage. It's extremely light and fast. At this moment, the bottleneck is probably Docker itself.
Input parameters
Example of an input
Breaking Down the Configuration
- Requests: You'll list multiple web pages to be scraped. Each web page entry (request) will need the following:
- url: The URL of the web page to scrape.
- id (optional): Unique identifier for the request.
- extract (optional): List of fields to extract from the page. Each field will have a:
- field_name: A name to identify the extracted data.
- selector: CSS selector to pinpoint the HTML element containing the data.
- extract_type: Type of extraction (Text, HTML, or an attribute like class).
- Headers (optional): You can set additional HTTP headers globally or for individual requests. Global headers will be replaced with the request headers.
- Example Global Header: { "Accept": "application/json" }
- Example Request-specific Header: { "Accept-Language": "en-US" }
- User-Agent (optional): Specify the user-agent string your scraper will use globally or for individual requests. Global user agent will be replaced with the request user agent. This helps mimic different web browsers.
- Advanced Options (optional):
- force_cloud: Whether to force the scraper to run in a cloud environment.
- push_data_size: Max size of data chunks to push. Smaller value will ensure that you can offload the data into storage in smaller chunks.
- max_concurrency: Max number of concurrent requests.
- max_request_retries: Number of retries if a request fails.
- max_request_retry_timeout_ms: Max time to wait before retrying a request.
- request_retry_wait_ms: Waiting time between retries.
Example of Output
Your feedback
I am always working on improving the performance of my Actors. So if you’ve got any technical feedback for Fast Scraper or simply found a bug, please create an issue on the Actor’s Issues tab in Apify Console.


