Lafeltrinelli Product Search Scraper
Pricing
$20.00/month + usage
Lafeltrinelli Product Search Scraper
Comprehensive data extraction tool for LaFeltrinelli.it, Italy's largest online bookstore. Scrape product details, pricing, categories, and availability data from books, music, movies, and cultural products. Perfect for market research, price monitoring, and competitive analysis in the market.
Pricing
$20.00/month + usage
Rating
0.0
(0)
Developer
ecomscrape
Maintained by CommunityActor stats
0
Bookmarked
3
Total users
1
Monthly active users
8 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
LaFeltrinelli.it Scraper: Extract Italian Book Data Efficiently
Understanding LaFeltrinelli.it and Why Data Extraction Matters
LaFeltrinelli.it is the online platform of Italy's most iconic bookstore chain, offering an extensive catalog of books, music, movies, games, and cultural products since 1998. As one of the leading e-commerce platforms in Italy's arts and entertainment sector, LaFeltrinelli represents a valuable data source for businesses, researchers, and analysts interested in the Italian publishing market, consumer trends, and pricing strategies.
The need to extract data from LaFeltrinelli.it stems from several critical business requirements. Publishers and distributors need to monitor how their products are positioned and priced across the Italian market. Market researchers require comprehensive data to understand reading trends, genre popularity, and seasonal variations in book sales. Price comparison services need accurate, up-to-date information to serve Italian consumers effectively. Additionally, inventory managers and retail analysts can benefit from tracking availability patterns and delivery options across different product categories.
Manual data collection from such a vast catalog is impractical and time-consuming. The LaFeltrinelli.it Product Search Scraper automates this process, enabling efficient extraction of structured data from product listings, search results, and category pages.
LaFeltrinelli.it Scraper: Comprehensive Overview
The LaFeltrinelli.it Product Search Scraper is a specialized data extraction tool designed to collect detailed product information from the platform's search results and category pages. This scraper handles the complexities of modern e-commerce websites, including dynamic content loading, pagination, and anti-bot protections, to deliver reliable and comprehensive datasets.
Key Strengths and Advantages:
The scraper excels at handling large-scale data extraction operations with built-in retry mechanisms and proxy support to ensure high success rates. It processes multiple URL patterns simultaneously, from specific search queries to broad category pages, making it versatile for different research needs. The tool captures over 25 distinct data fields per product, providing granular insights into pricing, categorization, authorship, availability, and promotional information.
The scraper is particularly valuable for businesses operating in competitive intelligence, providing real-time market data that can inform pricing strategies and inventory decisions. Academic researchers studying Italian literature trends, publishing patterns, or consumer behavior will find the comprehensive author and category data especially useful. E-commerce businesses can leverage the discount and pricing information to optimize their own marketplace strategies.
Ideal Users:
Market research firms analyzing the Italian retail sector, publishers and distributors tracking product performance, price comparison platforms serving Italian consumers, data analysts studying e-commerce trends, and academic researchers investigating cultural consumption patterns will all benefit from this tool.
Input Configuration Explained
Example url 2: https://www.lafeltrinelli.it/libri/bambini-ragazzi/infanzia
Example url 3: https://www.lafeltrinelli.it/libri/fumetti-graphic-novels/manga-c8014?page=2
Example Screenshot of product list by query page:
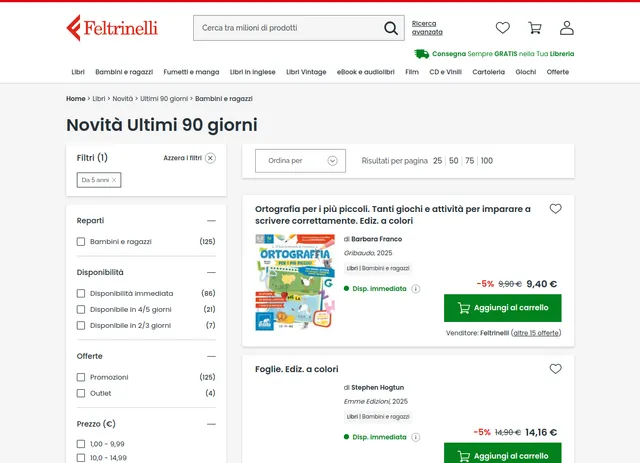
Input Format
The scraper accepts configuration through a JSON object with several key parameters:
Scrape with URLs:
The urls parameter: List of product list page URLs that you want to scrape. You can add URLs one by one, or use the Bulk edit section to add a prepared list.
The ignore_url_failures parameter: If set to true, the scraper will continue running even if some URLs fail to be scraped after reaching the maximum number of retries. This ensures that one problematic URL doesn't stop your entire scraping job.
When you provide a list of URLs for scraping, all options in the "Scrape with search filters" section will be disabled. The system will only collect data from the URLs you specified.
Scrape with Search Filters:
The keyword parameter: The search keyword to find items (e.g., "libro bambini", "manga", "romanzi").
The filter_price parameter: Filter items by price range:
""- Any price":0.99"- Less than €1.00"1:9.99"- €1.00 - €9.99"10:14.99"- €10.00 - €14.99"15:19.99"- €15.00 - €19.99"20:39.99"- €20.00 - €39.99"40:"- €40.00 or more
The filter_rating parameter: Filter items by customer rating:
""- Any rating"1"- 1 star"2"- 2 stars"3"- 3 stars"4"- 4 stars"5"- 5 stars
The page parameter: Starting page number for scraping, useful for continuing interrupted scrapes or targeting specific result ranges.
When using search filters for scraping, you need to leave the urls field empty (or set it to null) in the "Scrape with URLs" configuration.
General Options:
The max_items_per_url parameter: Limits the number of items extracted from each product list page or search results page. The default value is 20, providing a manageable batch size while allowing for comprehensive data collection.
The max_retries_per_url parameter: Sets the maximum number of retry attempts for each URL or search filters if the scrape is detected as a bot or the page fails to load. The default value is 2, providing a good balance between thoroughness and efficiency.
The proxy parameter: Proxy configuration is essential for maintaining anonymity and avoiding detection. The residential proxy option ensures that your scraping activities appear as legitimate browsing, reducing the risk of being blocked or rate-limited. You should choose a country that matches the location of the website you're scraping (e.g., Italy for lafeltrinelli.it).
Comprehensive Output Data Structure
You get the output from the lafeltrinelli.it Product Search Scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
Output Fields Explained
Core Product Identification:
-
SKU Prmt: Stock Keeping Unit for product tracking—a unique internal identifier used by LaFeltrinelli for inventory management. This helps track the same product across different listings and time periods.
-
Item ID: The unique product identifier in LaFeltrinelli's system. Essential for creating direct product links and avoiding duplicates in your dataset.
-
Item Name: The complete product title as displayed on the website. For books, this typically includes the full title and may include edition information.
Pricing and Discounts:
-
Price: The current selling price in euros. This is the actual price customers pay, after any discounts have been applied.
-
Discount Percentage: The markdown percentage from the original price. Critical for analyzing promotional strategies and identifying sales patterns.
-
Discount: The absolute discount amount in currency. When combined with the price, you can calculate the original price:
Original Price = Price + Discount. -
Coupon: Indicates if any coupon codes or promotional offers apply to the product. This field helps identify special promotion campaigns.
-
Currency Code: The currency designation (typically "EUR" for euros). Important for international data analysis and currency conversion.
Product Classification:
-
Item Category: The primary category assignment (e.g., "Books", "Music", "Games"). This is the broadest classification level.
-
Item Category 2, 3, 4: Hierarchical subcategories providing increasingly specific classification. For example: Category 1: "Books" → Category 2: "Children's Books" → Category 3: "Picture Books" → Category 4: "Ages 3-5". These nested categories enable sophisticated filtering and trend analysis.
-
Literature: A classification field indicating the literary genre or type. This might distinguish between fiction, non-fiction, poetry, essays, etc.
Author and Publication Details:
-
Item Author: The author(s) or creator(s) of the product. For books with multiple authors, this field may contain a concatenated or primary author name.
-
Year Edition: The publication year or edition year. Essential for tracking new releases, analyzing publication trends, and distinguishing between different editions of the same work.
-
Item Series: The series name if the product is part of a collection or series. Examples include "Harry Potter" series, "Marvel Comics" series, etc.
-
Item Series 2: A secondary series classification, possibly for products belonging to multiple series or franchise hierarchies.
Commercial Information:
-
Item Brand: The publisher, label, or manufacturer. For books, this is typically the publishing house; for music, the record label; for games, the game publisher.
-
Item Variant: Specific product variations such as format (hardcover, paperback, audiobook), language editions, or special editions (illustrated, annotated, collector's edition).
-
Vendor: The seller information, particularly relevant if LaFeltrinelli operates as a marketplace with third-party sellers.
-
Item Marketplace: Indicates the specific marketplace or sales channel within LaFeltrinelli's ecosystem.
Inventory and Logistics:
-
Quantity: Available stock quantity or stock status indicator. This field may show exact numbers or status terms like "in stock", "limited availability", or "out of stock".
-
Delivery Availability: Information about delivery options and estimated delivery times. This may include phrases like "Ships within 24 hours" or "Delivery in 3-5 business days".
-
Pickup Availability: Indicates if the product can be picked up at physical LaFeltrinelli store locations and which stores have it in stock.
-
Delivery Free: Boolean or descriptive field indicating if free delivery applies to the product, often based on order value thresholds.
Customer Engagement:
-
Reviews: Customer review data, which may include review counts, average ratings, or links to review sections. This provides social proof and quality indicators.
-
Item Position: The product's position in search results or category listings. This ranking information is valuable for understanding product visibility and SEO performance.
Example Output Record:
This structured output enables multiple analytical approaches: price tracking over time, category performance analysis, author popularity studies, discount pattern identification, and inventory availability monitoring.
Step-by-Step Usage Guide
Step 1: Choose Your Scraping Method
Decide between two approaches:
- Method A - URL-based scraping: Navigate to LaFeltrinelli.it and use the website's search and filtering features to find the exact product listings you want to scrape. Copy the complete URLs including all query parameters.
- Method B - Filter-based scraping: Use the built-in search filters (keyword, price range, rating) to automatically generate search queries without manually copying URLs.
Step 2: Configure Your Input JSON
For URL-based scraping:
Create your configuration file with the URLs you've identified. Include the urls array and leave filter parameters empty.
For filter-based scraping: Set up your configuration with search parameters:
- Define your
keyword(e.g., "libro bambini", "manga") - Optionally add
filter_price(e.g., "10:14.99" for €10-€14.99 range) - Optionally add
filter_rating(e.g., "4" for 4+ stars) - Set
pageto start from a specific results page
Set max_items_per_url based on your needs—lower numbers (10-20) work well for sampling, while higher numbers (50-100) are better for comprehensive catalogs. Configure the proxy settings with apifyProxyCountry set to "IT" for optimal performance with Italian websites.
Step 3: Run the Scraper
Execute the scraper with your configuration. The tool will begin processing URLs or search filters sequentially, respecting the retry settings and handling any failures according to your ignore_url_failures setting.
Step 4: Monitor Progress
Track the scraper's progress through the provided logs. Watch for any consistent failures that might indicate URL formatting issues, invalid filter combinations, or website changes.
Step 5: Validate and Process Output
Once complete, review the output data for completeness. Check that all expected fields are populated and that prices and categories make sense. Export the data in your preferred format (CSV, JSON, Excel) for further analysis.
Best Practices:
- Respect rate limits: Don't scrape too aggressively. Set reasonable delays between requests to avoid overloading the server.
- Choose the right method: Use URL-based scraping for specific, complex queries; use filter-based scraping for broader, category-wide searches.
- Use specific URLs or filters: The more targeted your input (whether URLs or search filters), the more relevant your output data will be.
- Test with small batches: Before running large-scale extractions, test with a few URLs or a limited
max_items_per_urlto ensure your configuration works correctly. - Update proxy country: Always use Italian proxies ("IT") for LaFeltrinelli.it to avoid geographic restrictions.
- Refine your filters: When using filter-based scraping, start with broad criteria and narrow down based on results.
- Handle pagination:
- For URL-based: Include all pagination URLs in your input array
- For filter-based: Use the
pageparameter to continue from where you left off
- Enable
ignore_url_failures: This prevents one failed URL or search query from stopping your entire scraping job.
Common Issues and Solutions:
- Empty results: Verify your URLs load correctly in a browser and include the full query parameters.
- Missing data fields: Some products may not have all fields populated. Your analysis should account for null values.
- Proxy failures: If residential proxies fail frequently, consider datacenter proxies for better stability, though they may be more easily detected.
- Rate limiting: If you encounter frequent failures, increase delays between requests or reduce
max_items_per_url.
Business Value and Practical Applications
Time Efficiency:
Manual data collection from hundreds or thousands of products would require weeks of tedious copy-paste work. This scraper reduces that timeline to hours or minutes, depending on the scale of your needs. For businesses monitoring competitive pricing daily, the time savings compound dramatically over weeks and months.
Real-World Applications:
Competitive Intelligence: Publishers can monitor how competitors price similar titles, identify promotional patterns, and adjust their strategies accordingly. Track which genres receive the most promotional support and how deeply products are discounted during sales periods.
Market Research: Analyze category trends by examining the volume of new releases, author popularity by review counts and product positions, and seasonal variations in pricing and availability. Understand which categories LaFeltrinelli emphasizes through featured placement and promotional strategies.
Price Monitoring: Build a comprehensive price history database to identify optimal pricing points, track price elasticity across different categories, and detect pricing anomalies that might indicate stock clearances or upcoming promotions.
Inventory Planning: Study availability patterns to understand supply chain dynamics, identify frequently out-of-stock items that represent market opportunities, and correlate availability with pricing strategies.
Content Enrichment: Use the comprehensive product data to enrich your own database, improve product recommendations through category hierarchies, and enhance search functionality with author and series information.
The comprehensive author, category, and series data enables sophisticated content-based filtering and recommendation systems. The delivery and pickup availability information helps logistics companies optimize their distribution networks and understand regional demand patterns.
Conclusion
The LaFeltrinelli.it Product Search Scraper provides a powerful solution for anyone needing structured data from Italy's leading online bookstore and cultural products retailer. By automating the extraction of over 25 data fields across categories, pricing, authors, and availability, this tool transforms the time-consuming process of manual data collection into an efficient, repeatable workflow.
Whether you're conducting market research, monitoring competitive pricing, analyzing publishing trends, or building data-driven applications, this scraper delivers the comprehensive, accurate data you need to make informed decisions in the Italian retail market.
Ready to start extracting valuable insights from LaFeltrinelli.it? Configure your first scraping job today and unlock the power of structured e-commerce data.
Related Actors
- Lafeltrinelli.it Product Details Scraper: A specialized data extraction tool engineered to harvest detailed product information from lafeltrinelli.it's product marketplace.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about lafeltrinelli.it Product Search Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.