Skool Posts Listing Scraper
Pricing
from $1.50 / 1,000 results
Skool Posts Listing Scraper
Skool.com Posts Listings Scraper automates extraction of community posts, discussions, and engagement data from Skool groups. Efficiently collect content metadata, user activity, and post analytics for community management, content strategy, and market research.
Pricing
from $1.50 / 1,000 results
Rating
0.0
(0)
Developer
ecomscrape
Maintained by CommunityActor stats
0
Bookmarked
6
Total users
0
Monthly active users
4 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My posts
Skool.com Posts Listings Scraper: Extract Community Content & Engagement Data
Introduction
Skool.com is a rapidly growing community platform that combines course hosting, community discussions, and gamification features. It hosts thousands of communities across niches including entrepreneurship, AI/automation, marketing, personal development, and specialized skill-building groups. Each Skool group generates continuous streams of posts, discussions, and user-generated content that provide valuable insights into community engagement, trending topics, and member activity patterns.
For community managers, content strategists, market researchers, and course creators, accessing this structured post data is invaluable for understanding engagement trends, identifying popular topics, monitoring competitor communities, and analyzing content performance. However, manually tracking posts across multiple Skool groups or analyzing large volumes of community content is extremely time-consuming.
The Skool.com Posts Listings Scraper automates this extraction process, enabling systematic collection of post metadata, user activity, and engagement patterns from any Skool community.
Scraper Overview
The Skool.com Posts Listings Scraper is designed to extract post listing data from Skool community pages. It collects comprehensive metadata including post IDs, timestamps, user information, post types, and organizational data that reveals community dynamics and content patterns.
The tool handles pagination automatically, processes multiple community pages simultaneously, and includes configurable retry mechanisms for reliable data collection. It's valuable for community managers analyzing engagement trends, content creators researching successful post formats, market researchers studying niche communities, competitors monitoring similar groups, and educators tracking course discussion activity.
The scraper maintains data quality while respecting platform guidelines and implementing best practices for ethical data collection.
Input and Output Details
Example url 1: https://www.skool.com/ai-automation-society?c=&fl=&p=2
Example url 2: https://www.skool.com/goosify
Example url 3: https://www.skool.com/goosify?c=88c760eb0f454be6abddb9e2160cd8c8&s=newest-cm&fl=
Example Screenshot of posts list page:
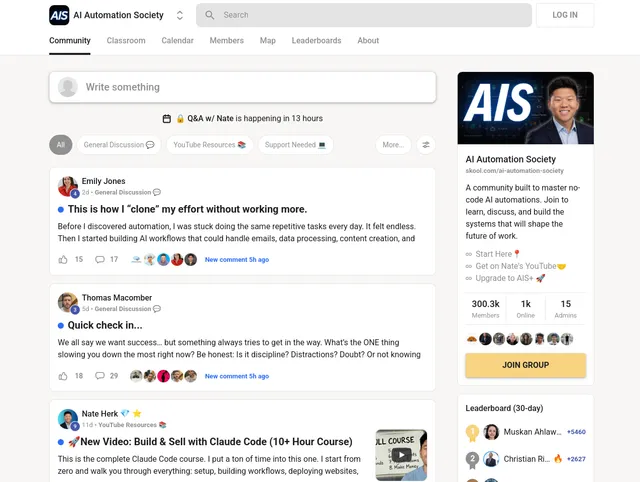
Input Format
The urls parameter: Add URLs of Skool posts list pages you want to scrape. You can paste URLs one by one or use bulk edit for prepared lists. These should be community post listing pages, which can include pagination parameters (p=2), category filters (c=), or other query strings.
The ignore_url_failures parameter: If true, the scraper continues running even if some URLs fail after maximum retries. Essential for large-scale scraping across multiple communities.
The max_items_per_url parameter: Limits the number of posts extracted per URL. Default is 20. Adjust based on your analysis needs and available resources.
The max_retries_per_url parameter: Sets retry attempts for failed requests. Default is 2, balancing thoroughness with efficiency.
Output Format
The scraper returns structured post data with fields providing specific analytical value: