Yelp Business Search Scraper
Pricing
$10.00/month + usage
Yelp Business Search Scraper
Yelp Business Search Scraper automates data extraction from Yelp.com, collecting business names, addresses, reviews, ratings & hours. Outputs structured JSON for easy integration. Supports bulk processing across global Yelp platforms for market research & lead generation.
Pricing
$10.00/month + usage
Rating
1.0
(1)
Developer
ecomscrape
Maintained by CommunityActor stats
2
Bookmarked
53
Total users
1
Monthly active users
5 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
What does Yelp.com Bussiness Search Scraper do?
Introduction
Yelp.com is one of the most popular platforms for finding local businesses, renowned for its extensive user reviews and detailed business information. In today’s data-driven world, accessing real-time business insights from Yelp has become invaluable for marketers, analysts, and business owners alike. However, manually gathering this wealth of data can be extremely time-consuming and error-prone. This is where our Yelp.com Scraper comes into play. Designed to extract key details such as names, ratings, reviews, and operational hours, the scraper addresses the need for efficient and large-scale data collection. By automating the data retrieval process, it enables users to focus on analysis and strategy, rather than struggling with manual extraction. Moreover, the scraper supports structured data export, simplifying the integration into business intelligence and analytical workflows.
Overview of the Scraper
The Yelp.com Scraper is engineered to extract comprehensive details from Yelp business search pages. It allows users to retrieve a variety of data points, including the output fields: Encid, URL, Name, Alias, Primary Photo, Rating, Total Reviews, Categories, Location, Operation Hours, and Media. The primary function is to automate the business search process on Yelp, ensuring that critical pieces of information are collected swiftly and accurately. One of the great strengths of this tool is its reliability under various network conditions, thanks to built-in re-try mechanisms and the use of proxy configurations such as Apify Proxy with residential IP groups. This ensures that data collection can continue even if temporary blocks or connectivity issues occur. The tool is designed for SEO professionals, market researchers, and business analysts who need actionable insights to drive local business strategies. With technical accuracy and a user-friendly interface, the scraper can be deployed in diverse settings, from academic research to competitive market analysis. Its robust design makes it suitable for both small-scale projects and large, automated data collection initiatives, keeping legal limitations and usage policies in mind.
Input and Output Details
Example url 1: https://www.yelp.com/search?find_desc=Restaurant&find_loc=San+Francisco%2C+CA
Example url 2: https://www.yelp.com/search?find_desc=Home+%26+Garden&find_loc=San+Francisco%2C+CA
Example url 3: https://www.yelp.com/search?find_desc=Auto+Detailing&find_loc=San+Francisco%2C+CA
Example Screenshot of bussiness information page:
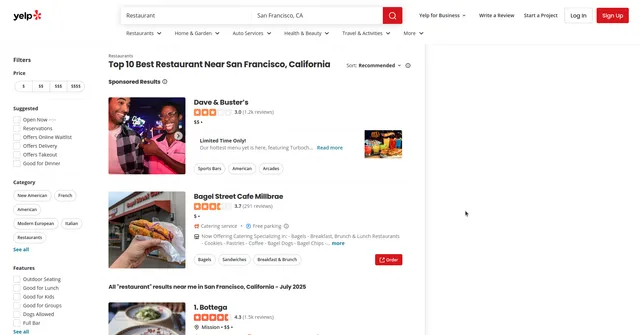
Input Format
The scraper accepts configuration through a JSON object with several key parameters:
Scrape with URLs:
The urls parameter: List of business listing page URLs that you want to scrape. You can add URLs one by one, or use the Bulk edit section to add a prepared list.
The ignore_url_failures parameter: If set to true, the scraper will continue running even if some URLs fail to be scraped after reaching the maximum number of retries. This ensures that one problematic URL doesn't stop your entire scraping job.
When you provide a list of URLs for scraping, all options in the "Scrape with search filters" section will be disabled. The system will only collect data from the URLs you specified.
Scrape with Search Filters:
The country_code parameter: Select the Yelp country site you want to scrape:
"com"- Global (Yelp.com - primarily USA)"uk"- United Kingdom (Yelp.co.uk)"ca"- Canada (Yelp.ca)"de"- Germany (Yelp.de)"fr"- France (Yelp.fr)"au"- Australia (Yelp.com.au)"jp"- Japan (Yelp.co.jp)"it"- Italy (Yelp.it)"es"- Spain (Yelp.es)
The keyword parameter: The search keyword to find businesses (e.g., "restaurant", "pizza", "plumber", "dentist", "hotel").
The location parameter: Enter the location to search for businesses. You can use:
- City and state (e.g., "San Francisco, CA", "New York, NY")
- Zip codes (e.g., "94102", "10001")
- Neighborhoods (e.g., "Brooklyn", "SoHo")
- Addresses or landmarks
The sort_by parameter: Sort businesses by various criteria:
"relevance"- Relevance (most relevant first)"rating"- Highest Rated (best reviews first)"review_count"- Most Reviewed (most reviews first)
The page parameter: Starting page number for scraping, useful for continuing interrupted scrapes or targeting specific result ranges.
When using search filters for scraping, you need to leave the urls field empty (or set it to null) in the "Scrape with URLs" configuration.
General Options:
The max_items_per_url parameter: Limits the number of business listings extracted from each listing page or search results page. The default value is 20, providing a manageable batch size while allowing for comprehensive data collection.
The max_retries_per_url parameter: Sets the maximum number of retry attempts for each URL or search filters if the scrape is detected as a bot or the page fails to load. The default value is 2, providing a good balance between thoroughness and efficiency.
The proxy parameter: Proxy configuration is essential for maintaining anonymity and avoiding detection. The residential proxy option ensures that your scraping activities appear as legitimate browsing, reducing the risk of being blocked or rate-limited. You should choose a country that matches the Yelp site you're scraping (e.g., US for Yelp.com, UK for Yelp.co.uk, CA for Yelp.ca, etc.).
Ouput format
You get the output from the Yelp.com Bussiness Search Scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
The output follows a structured format, providing rich detail in each field:
- Encid: A unique identifier for each business entry.
- URL: The direct link to the business’ Yelp page.
- Name: The official name of the business.
- Alias: An alternative representation of the business name.
- Primary Photo: The main image associated with the business.
- Rating: The average user rating, which can offer insight into service quality.
- Total Reviews: The number of reviews, indicating the level of customer engagement.
- Categories: Business categories that classify the type of service or product offered.
- Location: The business address and geographical information.
- Operation Hours: The schedule indicating when the business is open.
- Media: Additional images or videos that enrich the business profile.
- Phone: The contact number for the business.
- Tags: Keywords or phrases associated with the business.
- Price Range: The estimated price range for services or products provided.
Each field is meticulously documented to ensure that users understand the data’s context, usage, and limitations. For instance, the “Rating” field outlines average user opinions, while “Total Reviews” indicates popularity and reliability. The annotation in the output sample guides users in integrating this structured data into databases or analytics tools, facilitating seamless downstream processing.
Usage Guide
Method 1: Scraping with URLs
Using the Yelp.com Scraper with URLs is straightforward. Begin by configuring your input JSON with the desired proxy settings and target URLs from Yelp.com. Add URLs of search result pages, business category pages, or location-specific listings that contain the data you need. Ensure that the "max_retries_per_url" and "max_items_per_url" are set according to the volume and frequency of data you wish to extract.
When providing URLs for scraping, all options in the "Scrape with search filters" section will be automatically disabled. The scraper will focus exclusively on extracting data from your specified URLs. You can paste URLs one by one or use the Bulk edit section to add a prepared list efficiently.
Enable the "ignore_url_failures" option to ensure your scraping job continues even if some URLs encounter issues after reaching the maximum retry limit. This prevents a single problematic URL from stopping your entire data extraction process.
Method 2: Scraping with Search Filters
Alternatively, you can scrape Yelp.com by using search filters instead of providing specific URLs. When using this method, leave the URLs section empty and configure the following parameters:
Country Code: Select the Yelp domain you want to scrape from (e.g., Global/Yelp.com, United Kingdom/Yelp.co.uk, Canada/Yelp.ca, Germany/Yelp.de, France/Yelp.fr, Australia/Yelp.com.au, Japan/Yelp.co.jp, Italy/Yelp.it, or Spain/Yelp.es).
Keyword: Enter the search term to find businesses (e.g., "Restaurant", "Coffee Shop", "Hotel", "Dentist").
Location: Specify the geographic location for your search (e.g., city, state, or zip code such as "San Francisco, CA" or "10001").
Sort By: Choose how you want results sorted:
- Relevance - Most relevant results first
- Highest Rated - Businesses with the best ratings
- Most Reviewed - Businesses with the most customer reviews
Page Start: Specify which page number to begin scraping from, useful for continuing interrupted scrapes or targeting specific result ranges.
Execution and Data Processing
Once the configuration is complete, run the scraper command; it will sequentially process each URL or search query and retrieve the specified details. As the process unfolds, the tool will output a structured dataset that can be directly imported into your preferred data management system or further analyzed with tools like Excel and BI software.
Best Practices and Troubleshooting
Monitor the scraping process to identify any anomalies, such as temporary site blocks or incomplete data segments. Users are encouraged to validate the output by cross-referencing a few data points with the actual Yelp listings to ensure accuracy.
In case of errors, the scraper provides detailed error messages, which can be used to troubleshoot connectivity issues or configuration mismatches. It is advisable to keep your proxy settings updated and compliant with legal frameworks to avoid any potential issues with Yelp's terms of service.
Additional Recommendations:
- Start with a small "max_items_per_url" value to test your configuration before running large-scale extractions
- Use residential proxies with country settings that match your target Yelp domain for optimal performance
- Regularly update your URL lists or search parameters to capture new businesses or seasonal changes
- Monitor for any changes in Yelp's website structure that might affect scraping performance
Moreover, regular updates to the scraper may be needed to adapt to any changes in the Yelp website's structure. Following these steps will ensure a smooth and efficient data extraction process.
Benefits and Applications
The primary advantage of using the Yelp.com Scraper is the dramatic reduction in time and energy spent on collecting business data. By automating repetitive tasks, it allows professionals to focus on strategic decision-making. Marketers can use the extracted data for local SEO optimization and targeted advertising, while market researchers can analyze trends and consumer sentiment. Additionally, business analysts benefit from access to reliable data that may inform operational strategies and competitive intelligence. This scraper is particularly useful for startups and SMEs looking to harness online reviews and business details for competitive advantage. Ultimately, users gain more reliable data, leading to smarter business decisions and enhanced performance in a competitive market.
Conclusion
The Yelp.com Scraper offers a powerful solution for extracting critical business data from one of the leading review platforms. By automating the data collection process and providing structured output, it helps users save time and improve insight-driven strategies. Whether for marketing, research, or operational efficiency, this tool can be seamlessly integrated into your workflows. Explore the possibilities and take your business intelligence efforts to the next level.
Note: Always ensure that your usage of the scraper complies with Yelp’s terms of service and local legal requirements.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about Yelp.com Bussiness Search Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.