Advanced Social Media Agent
Pricing
from $0.05 / 1,000 results
Advanced Social Media Agent
A production-grade AI agent built on cutting-edge research patterns for intelligent social media analysis on the Apify platform.
Pricing
from $0.05 / 1,000 results
Rating
0.0
(0)
Developer
Cody Churchwell
Maintained by CommunityActor stats
0
Bookmarked
3
Total users
0
Monthly active users
8 months ago
Last modified
Categories
Share
Advanced Social Media Analysis Agent
A production-grade AI agent built on cutting-edge research patterns for intelligent social media analysis on the Apify platform.
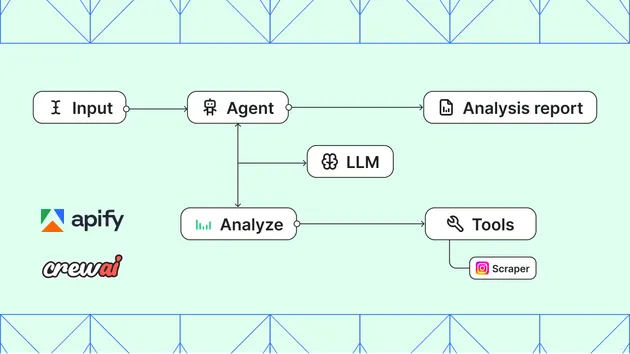
Architecture Overview
This agent implements state-of-the-art AI agent patterns based on research papers and production best practices:
Core Patterns Implemented
-
ReAct (Reasoning + Acting) - Paper
- Interleaves chain-of-thought reasoning with tool-using actions
- Thought -> Action -> Observation cycle
- 34% improvement over imitation learning on ALFWorld
-
Reflexion (Self-Improvement) - Paper
- Verbal reinforcement learning through self-reflection
- Episodic memory for storing lessons learned
- 91% pass@1 on HumanEval (vs GPT-4's 80%)
-
12-Factor Agents - GitHub
- Production principles from 100+ SaaS builders
- Small, focused agents (3-20 steps max)
- Own your control flow
- Compact errors into context for self-healing
-
Multi-Tier Memory System
- Working Memory: Current conversation context
- Episodic Memory: Task-specific learnings
- Semantic Memory: General knowledge
- Procedural Memory: How to perform tasks
-
Human-in-the-Loop
- Approval gates for high-risk actions
- Interrupt/resume capabilities
- Confidence-based escalation
Features
- Intelligent Reasoning: ReAct pattern for transparent decision-making
- Self-Improvement: Reflexion pattern learns from each execution
- Advanced Memory: Multi-tier memory system for context retention
- Human-in-the-Loop: Approval gates for sensitive operations
- Full Observability: Distributed tracing, metrics, cost tracking
- Error Recovery: Self-healing with exponential backoff
- Cost Control: Budget limits and usage tracking
- Multiple Modes: Autonomous, Supervised, Interactive, Research
Project Structure
Usage
Basic Usage
Input Configuration
| Parameter | Description | Default |
|---|---|---|
query | The task for the agent | Required |
modelName | LLM model to use | gpt-4o |
mode | Operating mode | supervised |
maxSteps | Maximum reasoning steps | 20 |
budgetLimit | Cost limit in USD | None |
enableMemory | Enable memory system | true |
enableReflection | Enable self-reflection | true |
Agent Modes
- Autonomous: Full autonomy within defined constraints
- Supervised: Requires approval for important/risky actions
- Interactive: Step-by-step execution with human guidance
- Research: Read-only mode, no side effects
Architecture Deep Dive
State Management (Factor 5 & 12)
Control Flow (Factor 8)
Error Recovery (Factor 9)
Memory System
Observability
The agent includes comprehensive observability:
- Distributed Tracing: Track every step with span hierarchy
- Metrics Collection: Counters, gauges, histograms, timers
- Cost Tracking: Per-model, per-operation cost breakdown
- Structured Logging: JSON logs for aggregation
Best Practices (from 12-Factor Agents)
- Small, Focused Agents: 3-20 steps max per agent
- Own Your Context Window: Custom formats for efficiency
- Tools Are Structured Outputs: Function calling IS structured output
- Contact Humans with Tools: Human interaction as first-class tool
- Compact Errors: Self-healing with formatted error context
- Stateless Reducer: Agent = pure function (state, event) => state
References
- ReAct Paper - Synergizing Reasoning and Acting
- Reflexion Paper - Language Agents with Verbal Reinforcement
- 12-Factor Agents - Production patterns
- LangGraph Memory - Stateful workflows
- CrewAI - Multi-agent orchestration
Development
License
MIT License