Personio Jobs Scraper (FreshActors)
Pricing
from $20.00 / 1,000 company jobs fetcheds
Personio Jobs Scraper (FreshActors)
Reliable, always-fresh job postings from any Personio career portal. Public XML feed, no login — departments, seniority, and full descriptions in a single call. Monitored daily. By FreshActors.
Pricing
from $20.00 / 1,000 company jobs fetcheds
Rating
0.0
(0)
Developer
Freshactors
Maintained by CommunityActor stats
0
Bookmarked
1
Total users
1
Monthly active users
17 days ago
Last modified
Categories
Share
Personio Jobs Scraper — Every Career Portal as Clean JSON (No API Key)
Scrape Personio career-portal job postings from any company's public board into clean, structured JSON — title, department, seniority, full description sections, locations, posting date, and apply URL. No account, no login, no API key. Point it at a list of Personio tenants and get a normalized jobs feed back.
✅ Last verified working: 2026-07-08. Monitored by an automated daily canary. When Personio changes its feed, we patch fast and log it in the changelog below — so your hiring-data pipeline doesn't silently break.
Why this Personio scraper
Personio is the ATS standard for the German, Austrian, and Swiss SMB market — thousands of DACH companies run their careers page on a {tenant}.jobs.personio.de portal, and every one of those portals serves a public XML feed of its published positions at the explicit /xml path. No key, no login, no browser. One request returns the whole board with full descriptions, departments, and seniority levels — metadata most ATS feeds don't expose. The catch is the usual one: the moment the feed shape shifts, a naive scraper silently returns nothing. This actor is built to stay working:
- One normalized schema — the same stable job record as our Greenhouse & Lever, Workable, SmartRecruiters, Recruitee, and Teamtailor scrapers, so Personio companies slot into the exact same pipeline with no special-casing.
- Departments + seniority included — Personio's feed exposes
department,seniority(entry-level / experienced / …), and employment schedule on every position: the segmentation fields hiring-signal and recruiting datasets usually have to infer. - Full descriptions, in one call — every description section ("About the role", "Your profile", …) comes back as labeled clean text. No extra requests, so it's fast and cheap.
- Language option — pass
language: "en"(orde, …) to get localized titles/descriptions where the company provides them. - Per-company isolation + retries — a dead or unknown tenant is skipped and logged; it never crashes the run. Transient errors retry with backoff.
- Stable, versioned output (
_schemaVersion) + a daily canary — that "last verified working" date is real.
What data you get
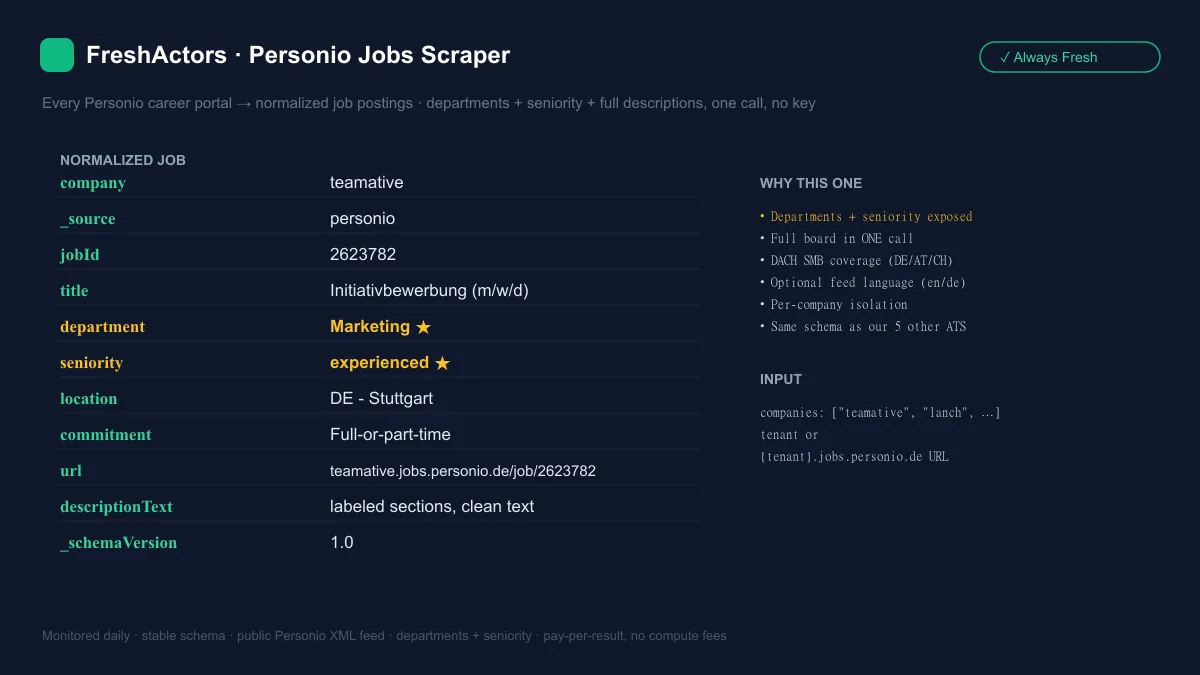
Each row is one normalized job posting. Fields Personio's public feed doesn't provide come back as null, never missing, so your downstream schema stays predictable.
| Field | Type | Description |
|---|---|---|
_type | string | Always job. |
_schemaVersion | string | Output schema version. |
_source | string | Always personio. |
company | string | Tenant identifier (the {tenant}.jobs.personio.de subdomain). |
jobId | string | Personio position ID. |
title | string | Job title. |
department | string | null | Department (populated on virtually every posting). |
seniority | string | null | Seniority level (e.g. entry-level, experienced). |
team | null | Not exposed in the feed — always null. |
location | string | null | Primary office string (as the company writes it, e.g. DE - Stuttgart). |
allLocations | string[] | null | All listed offices (comma-separated offices split out). |
workplaceType | null | Not exposed as a dedicated field — remote status often appears in the office string. |
commitment | string | null | Schedule (Full-time, Part-time, …). |
country | null | Personio gives free-form office names, not country codes — always null. |
url | string | Public posting URL (/job/{id}). |
applyUrl | string | The posting page (applications happen there). |
postedAt | string | null | Creation date (ISO). |
updatedAt | null | Not exposed in the feed — always null. |
descriptionText | string | null | All description sections as labeled clean text (when includeDescription is on). |
_scrapedAt | string | ISO timestamp this record was fetched. |
Use cases
- DACH sales intelligence / hiring-signal tracking. Personio is where German-speaking SMB hiring lives — a segment US-centric ATS datasets miss entirely.
department+seniority+postedAtfeed straight into lead-scoring and growth-signal models. - Recruiting & talent sourcing. Aggregate live openings across target employers into one table — same schema as our five other ATS scrapers, so multi-ATS coverage needs zero special-casing.
- Job boards & aggregators. Need to scrape Personio jobs into a uniform feed? Point it at your tenant list and ingest normalized records on a schedule, in the language you need.
- Labor-market research. Track posting volume, departments, and seniority mix across the DACH SMB market over time.
Input
| Field | Type | Required | Notes |
|---|---|---|---|
companies | string[] | ✅ | Personio tenants (lanch) or {tenant}.jobs.personio.de URLs. One per row. |
language | string | — | Optional two-letter code (en, de, …) for localized titles/descriptions where provided. Empty = tenant default. |
includeDescription | boolean | — | Include the labeled description sections. Default true. Same request either way — turning it off only trims output size. |
maxJobsPerCompany | integer | — | Cap per company (1–5000). Default 100. |
Output sample
A real record from the default run (teamative — a DACH IT-services group hiring across Germany and Czechia):
Use with AI agents (MCP)
This scraper is callable as a tool by AI agents via the Apify MCP server — so assistants like Claude, Cursor, and VS Code can run it and use the structured results mid-conversation, with no glue code.
Simplest path: in a recent Claude Desktop, add the hosted server https://mcp.apify.com under Settings → Connectors and authorize with OAuth. For any config-file client:
Then ask in plain language, e.g. "List the open jobs on teamative's Personio portal with departments, seniority, and apply links." — the agent calls freshactors/personio-jobs-scraper with the right input and reads back the JSON. Full setup: Apify MCP docs.
No Apify account? x402-enabled AI agents can also run this actor autonomously and pay per use via the x402 payment protocol — no signup, subscription, or API token required.
Pricing
Pay-per-event — no subscription. You pay only for the boards you fetch and the postings you receive:
| Event | Price (USD) | When it fires |
|---|---|---|
| Company jobs fetched | $0.02 | Once per company career portal successfully fetched (with ≥1 job). |
| Job posting fetched | $0.0005 | Once per job posting returned. |
Worked example — "how much do 100 results cost?" Scrape 5 companies for 100 postings total:
- Boards: 5 × $0.02 = $0.10
- Postings: 100 × $0.0005 = $0.05
- Total: $0.15 for 100 normalized jobs (with departments, seniority, and full descriptions) across 5 companies.
(Apify platform usage is billed separately per their standard rates.)
FAQ
Is scraping Personio jobs legal? This actor reads public, non-personal job-posting data from companies' own public career portals — the same data those pages serve to any visitor. No login, no personal data. Use responsibly and in line with applicable terms and laws.
Do I need an API key? No. There's no Personio API key, account, or login — it reads the public XML feed every career portal already serves.
How do I find a company's Personio tenant?
It's the subdomain of their careers page — **lanch**.jobs.personio.de. Companies that embed jobs on their own site usually link through to the jobs.personio.de portal — paste that URL.
How many jobs can one call return?
The feed returns the company's full published board in a single request — Personio's customer base is SMB, so boards are typically 3–50 positions. Use maxJobsPerCompany to cap volume and cost.
Can I get postings in English (or German)?
Yes — set language to a two-letter code (e.g. en). Where the company maintains translations, titles and descriptions come back localized; otherwise you get the tenant's default language.
Why is country always null?
Personio's feed gives free-form office names ("DE - Hamburg - remote", "Berlin"), not structured country codes — we pass the office strings through honestly in location/allLocations rather than guessing.
Can I scrape many companies at once?
Yes — pass as many tenants in companies as you need. Each board is fetched in isolation; a dead or unknown tenant is skipped, not fatal.
How often is the data updated? It's live — every run fetches the companies' current public boards. The actor itself is monitored by a daily canary so parsing stays correct as the feed evolves.
Other FreshActors tools
| FreshActors actor | What it scrapes |
|---|---|
| Greenhouse & Lever Jobs Scraper | Greenhouse + Lever — normalized job postings |
| Workable Jobs Scraper | Workable — normalized job postings, full descriptions |
| SmartRecruiters Jobs Scraper | SmartRecruiters — normalized job postings, full descriptions |
| Recruitee Jobs Scraper | Recruitee — normalized job postings, full descriptions + salary |
| Teamtailor Jobs Scraper | Teamtailor — normalized job postings, full descriptions |
| App Store Scraper | Apple App Store — app details, search, reviews |
| Google Play Scraper | Google Play — app details + reviews |
| Microsoft Store Scraper | Microsoft Store — app details, rating windows, search, reviews |
| VS Code Marketplace Scraper | VS Code extensions — install/trending stats, search, reviews |
| Shopify App Store Scraper | Shopify App Store — app details, reviews, discovery |
| Redfin Scraper | Redfin — US real-estate listings |
Reliability
A scheduled daily canary scrapes a known Personio portal, validates the normalized schema, and alerts the moment a parse changes. When Personio shifts its feed, we patch the same day and record it in the changelog below. Every record carries _schemaVersion and _scrapedAt.
Changelog
- 2026-07-08 — Freshness pass: re-verified working across every mode via the daily monitoring battery; documented x402 support (AI agents can run this actor pay-per-use with no Apify account). No change to scraping behavior, output, or pricing.
- 2026-06-10 — v1.0 launch. Single-call public XML feed (full board + labeled description sections per request), departments + seniority exposed, optional feed language, normalized schema shared with our five other ATS scrapers, per-company isolation, daily canary monitoring.
Legal note: Reads public, non-personal job-posting data from companies' own public career portals (the same data those pages serve to any visitor). No login, no personal data. Use responsibly and in line with applicable terms and laws.
Found a problem? Open an issue on the actor — issues are answered fast.