Binance NFT Collection Scraper
DeprecatedPricing
$20.00/month + usage
Binance NFT Collection Scraper
Deprecated🌐 Unlock the world of Binance NFT marketplace with our all-in-one scraper 💹 Extract rankings, explore individual collections, and access asset metadata easily. Get key metrics in your preferred cryptocurrency and fine-tune your results with extensive filtering, sorting and exporting options!!
Pricing
$20.00/month + usage
Rating
0.0
(0)
Developer
Gabriel
Maintained by CommunityActor stats
2
Bookmarked
9
Total users
1
Monthly active users
3 years ago
Last modified
Categories
Share
The Binance NFT scraper

|
Hello! It's Indy. I'm in charge of introducing you to this actor, but if you are here, I bet you are skilled enough in crypto assets jargon, so we can skip that part. 🤭 This actor scrapes NFT collections and assets from Binance, the largest cryptocurrency exchange in the world. Founded in 2017, Binance has a near-perfect score (as of September, 2023) according to CoinMarketCap, regarding trading volume, liquidity, web traffic and confidence. During the 'boom' of NFTs in 2021, Binance launched its own marketplace with several features for both creators and owners of digital assets. So here we are. 🙂 Welcome to the Binance NFT scraper! |
Our goal
As with most actors, we try to provide a service that is not available in the 'target' site, or takes too long to do it in bulk by hand.
It's noticeable that the Binance API for NFTs is very limited, with just a few end-points available and lacking of several useful details in the responses.
Additionally, using the web interface to search for collections or within collections under some parameters is already painfully slow without even considering the human factor.
This scraper lets you do all that anonymously, without quota limits and the constant risk of getting banned.
We achieve that by working one layer below the usual browser automation, through their 'non-public' API, and this has pros and cons.
The pros, it's lightning fast and detailed, compared to what you see as a web user. The cons, it's undocumented, but that's the reason we decided to develop this actor. So don't worry!
Roadmap
If you're in a hurry, follow this quick guide:
✅ In 0️⃣ Basic options, decide which currency you want your amounts converted to, and select it.
✅ For scraping the rankings or trending list and useful data about each collection inside, select 2️⃣ Collection rankings as the scraping mode.
- In 2️⃣ Collection rankings, pick the 'Ranking type' and optionally enable 'Include properties' or 'Include additional details' for extra data.
- Depending on the 'Ranking type' you chose, customize your results (period covered or sorting) in 2️⃣.1️⃣ All collections or 2️⃣.2️⃣ Trending collections.
✅ For scraping useful data about the NFTs in a given collection, select 3️⃣ Collection assets as the scraping mode.
- In 3️⃣ Collection assets, enter the desired 'Collection id' or just the URL of that collection, and optionally customize your results (filters, sorting, etc.) with the rest of the options in this section.
▶ Hit Start and wait a few minutes.
✅ Select the right view for browsing the Output. For rankings or trending list, be sure to pick 1️⃣&2️⃣ Collections - Compact/Detailed. As for NFTs, pick 3️⃣ Assets - Compact/Detailed.
Basic options
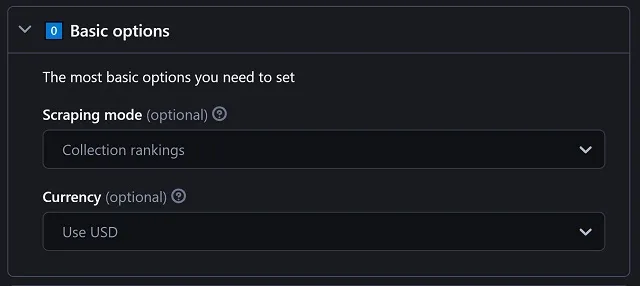
|
There are 6 currencies that can be used in the results shown:
Since the listed collections belong to diverse networks, a currency conversion may be required. We take the conversion rates directly from Binance, but as expected in the crypto world, the amounts can vary after a few minutes. In case you don't want any conversion applied, pick the Network's coin option. It will show each result in its associated currency. |
|
This actor encapsulates three working modes:
|
Specific collection(s)
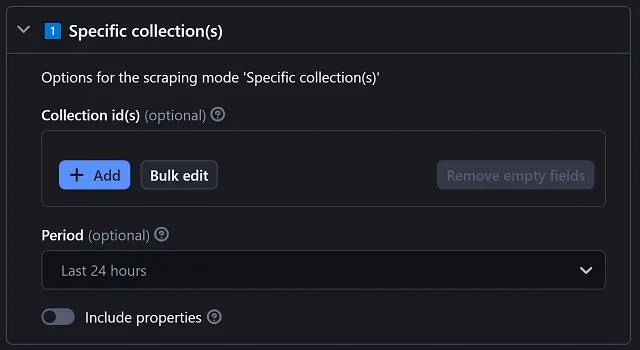
|
Period chooses what kind of volume, volume rate, floor price and floor price rate values are scraped:
⚠️ Sometimes, the specified collections are not included in the selected period rankings, resulting in missing volumes and prices, and there's no known workaround for that. Volume rate and floor price rate are seen as '1H/6H/24H/7D/30D change' in the website. Include properties will add the available attributes (or traits) for every scraped collection. Be wary that this option can add a lot of details to your results. Some collections don't have any properties at all, but some can have A TON of them. |
|
Enter a list of collection ids and the actor will scrape the details of each one. [required] Each entry can be any of the following:
The actor will 'understand' each type, as long as they correspond to Binance collection ids or collection URLs, and will ignore the invalid ones. The system will remove the empty spaces and won't allow duplicated ids. And the actor is still able to detect (and remove) different URLs pointing to the same collection. |
Collection rankings
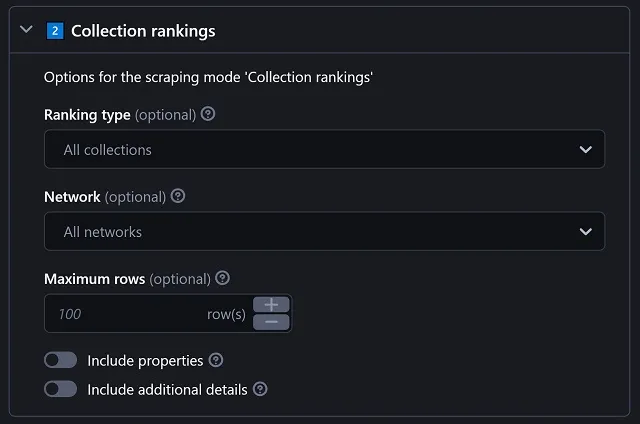
|
Maximum rows sets the length of the list of scraped collections. There is a limit of 100 for the Trending list, imposed by the website. Include properties, exactly as with Specific collection(s), will add the traits for every scraped collection. Include additional details, when enabled, extends the results with this information:
These details require a separate request per each collection. Have that into account when scraping several rows. All the rates are expressed in percentages. It's worth mentioning that the options described here (Network, Maximum rows, Properties and Additional details) apply for the next two sections, 2️⃣.1️⃣ and 2️⃣.2️⃣, corresponding to each ranking type. |
|
There are two available ranking types:
The details (i.e., columns) collected by these ranking types are exactly the same. The difference lies in how the results (i.e., rows) are selected. Network restricts the collections to the ones belonging to any of these:
In September 2023, Binance decided to part ways with the Polygon blockchain as a business move we don't fully understand. Because of that, Polygon's collections are not shown in the rankings anymore. They (and their NFTs) can still be accessed directly and appear in the results, but are planned to be delisted by the end of 2023. 😞 |
All collections

These options are exclusive for the scraping mode 'Collection rankings' and the ranking type 'All collections'. |
Sort metric is pretty much self-explanatory when you see the available options:
Sort direction acts as a modifier for the previous option:
Both sort metric and direction may seem useless considering that once a dataset is exported, you can sort it by whatever criteria you wish. However, notice that we are querying the Binance rankings, so the results vary a lot depending on the sort parameters. E.g., the top ten collections by volume are not gonna be the same as the top ten by price, etc. |
|
Period works exactly as in the 'Specific collection(s)' mode:
|
Trending collections
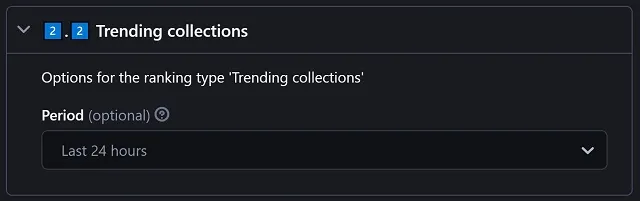
|
Period works as expected, but since the 'trending' ranking is limited by the website, it has fewer options:
|
Collection assets
|
The last scraping mode is the most customizable, given that we are dealing with individual NFTs here. 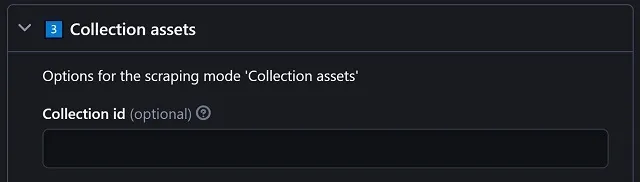
|
Enter a collection id (or URL) and the actor will scrape all the NFTs belonging to that collection. You can leave it in blank and that will result in grabbing the NFTs for ANY collection, meaning THOUSANDS of probable results. So we trust you know what you are doing.😉 |
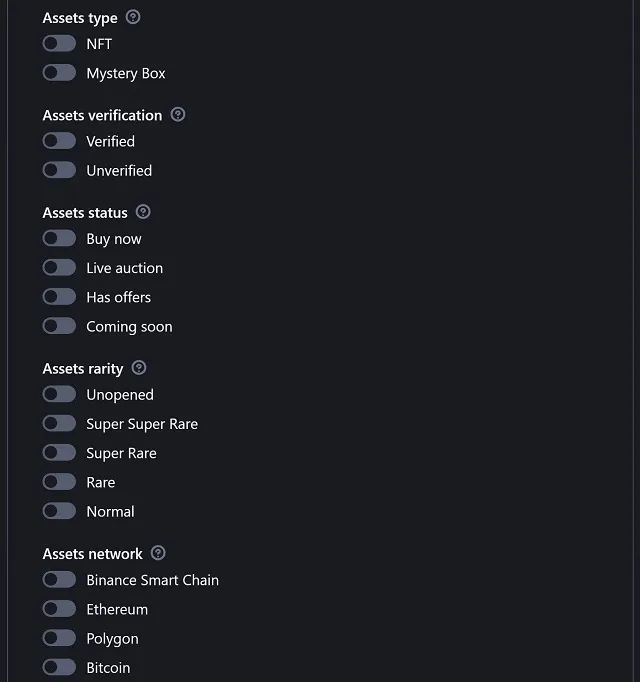
|
These filters are pretty evident. Let's review only the particular details which may not be obvious at first look. Not selecting anything in each filter group is the same as completely ignoring that filter, and that makes the available results wider. ⚠️ Don't trust the 'Assets status' filter for anything different than 'Buy now'. This Binance feature is problematic by design. Selecting individual statuses works but does not guarantee an exact filtering of the results, and there's nothing to do about it because their API behaves that way. Rarity only applies to 'Mystery boxes' and the NFTs coming from them, 'Box-exclusive'. This is a Binance-only feature, not to be confused with 'Open rarity'. As mentioned before, Binance does not work with the Polygon network anymore, but you can filter by that and still obtain results (which is likely to continue happening until the end of 2023). |
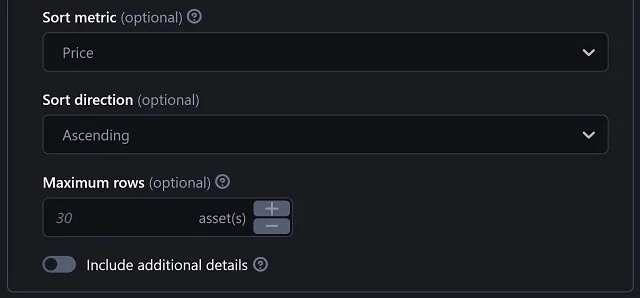
Sort metric differs slightly from what the website provides for sorting the NFTs. But combining it with Sort direction will give us these useful and well-known criteria:
Additionally, you can play with the options and get other not-that-useful results. For example:
If a date is missing, it will be treated as the oldest date when sorting in ascending order, and this causes that the rows with missing dates are moved to the top. The favorites 'count' can be negative, possibly due to dislikes or other reasons. Don't be surprised if you come across this. |
Maximum rows sets the length of the list of scraped assets. There is no limit for this value, and collections can include any number of assets from only a few tens to tens of thousands. We are confident that you will keep this in mind to prevent the actor from consuming unnecessary resources. Include additional details, when enabled, extends the results with this information:
The values 1-5, the bids, and the offers require a separate request for each. So be careful when scraping several assets as this can take a considerable time. |
Advanced options
|
Most of the time, you won't need to make any changes in this section unless you wish to customize the actor's behavior for specific situations. 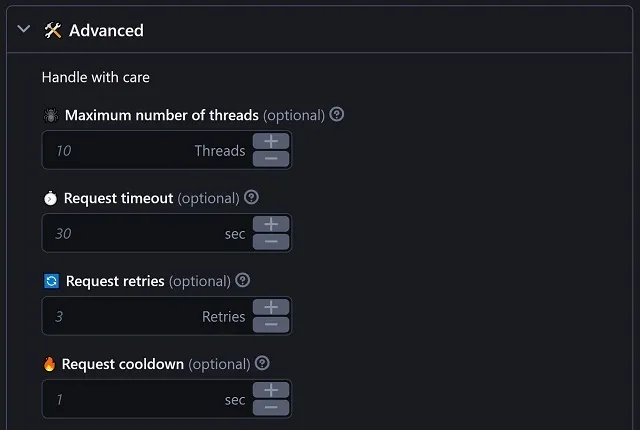
|
Maximum number of threads is the amount of simultaneous scraping processes this actor can start at a given time. Request timeout is the amount of time given to each individual request to complete. After this interval, incomplete requests are just forgotten. Request retries is the number of times to try again a failed request before giving up and acknowledge the actual failure. Request cooldown is the amount of time to wait before retrying each failed request. |
This actor can run without proxies, but, like any scraper, proxies can be used to simulate 'fair use' by multiple users, ensuring anonymity and reducing the likelihood of triggering certain flags. People used to think that proxies could slow down and degrade the success rate of requests. However, any decent proxy list, including the ones Apify provides, are more than sufficient. Binance is known for its hostility towards automation and issues IP bans, sometimes lasting for days. So you have been warned. Use proxies. 😋 |
Having said that, these are the available proxy options:
|

|
This final group of options really requires a deeper explanation, with examples, etc., to be fully understood, and we'll do that next. But the main idea is that you don't need to worry about it. 😉 |
Dataset optimization
This option, when enabled, reduces the horizontal size of the exported data by unifying the columns belonging to the same top-level group. Only some columns like properties or fees may need this.
Let's see an unoptimized collection's properties export. Notice the amount of wasted space for a collection with only 2 properties, 'Relic' and 'Role':
| properties/Relic/0/total | properties/Relic/0/value | properties/Role/0/total | properties/Role/0/value | properties/Role/1/total | properties/Role/1/value | properties/Role/2/total | properties/Role/2/value |
| 84 | KodaPendant | 15793 | Hunter | 12239 | Farmer | 7158 | Enchanter |
Now look how simple it becomes when optimized.
| properties |
|
Relic: KodaPendant (84)
Role: Hunter (15793), Farmer (12239), Enchanter (7158) |
For a programmatic post-processing this may not seem adequate, but from a human point of view, it's neat and concise.
Another sample. An unoptimized assset's platform fees export. One single asset/row, to keep it simple:
| platformFees/0/productSource | platformFees/0/rate | platformFees/0/vipRate | platformFees/1/productSource | platformFees/1/rate | platformFees/1/vipRate |
| Binance | 1 | OpenSea | 2.5 |
See the beauty of the optimization for the previous export:
| platformFees |
|
Binance: 1%
OpenSea: 2.5% |
Dataset cleanse
Enabling this gets rid of collections/assets which don't include enough information to be considered valuable.
For example, not having ('null') a Network or Currency specified, results in all the amounts (volumes, prices, etc.) being either missing as well or invalid for a given result row.
A collection with no assets (i.e., total items being zero) only wastes space in the results.
An asset with no defined marketplace and/or trade type has been probably de-listed or is somewhat inactive.
Maybe there are other conditions to discard results, but after a thorough analysis, we have concluded that the ones described here are the most prominent.
Notice that the omitted results are still shown in the actor's log.
Show warnings
Reporting an issue will be better when you attach the information shown (in the actor's log) by activating the warnings.
Apart of a bigger log, this won't hurt anybody. Most of the time, you get messages like this:
!! request failed: [Binance 000003 - Too many requests. Please try again later.] url=... (3 retries remaining) !!
Remember when we talked about hostility? Well, look it in action here. That's just a notification. Insisting with the same IP could get it blocked for who knows how long, and that's why proxies are recommended.
Other common warnings are about missing information. For example:
!! [getNFTAPICollectionProperties()] Collection properties request failed: Response data is empty - collection '...' !!
This just means that we found a collection with no properties/attributes/traits. 👨🏽🔬 A completely normal phenomenon.
Failures related to different issues are very rare.
Allow incompletion
This one's directly related to the previous option, and works as follows:
If a request fails and we are allowing incomplete information, the data that the request was attempting to populate remains empty without causing any interruption; otherwise, the entire process fails too.
Having the warnings enabled let you know what happened in these cases.
Output
Before explaining how the datasets will look, it's important to know two essential aspects about the data gathered from Binance.
There can be empty fields, so you will often find 'null' values, meaning that the content is either not available or not applicable.
Some of those are pretty obvious to figure out a reason why. For example, an asset with no offers (i.e., 'totalOffers' is zero), is certain to have the offer values ('lowestOffer' and 'highestOffer') set to 'null'.
On the other hand, an asset with a 'score' (the index of popularity) set to 'null' makes little sense. Probably means that they did not bother to calculate it, but we all know that the best approach should be setting it to '0.0'.
We need to accept some sort of small imprecision, both in terms of time and money, imposed by the website itself. The information is not generated in real-time, and our objective is not that either. Having that in mind:
The volumes, prices, and other currency amounts, along with dependent values (e.g., rates), aren't perfectly up to date, at least not to the second.
Rankings can also take some minutes to be updated. That's the reason the values in these lists sometimes differ from what you get when browsing individual collections.
The currency conversion table is loaded at the beginning of the actor's run, and the same exchange ratios are used throughout the process. Constantly updating this table would waste processing time and bandwidth.
Moving forward, remember that there are 3 scraping modes for this actor. 'Specific collection(s)' and 'Collection rankings' refer to (guess what) collections and hence, will produce results using the same layout. Let's see a 1-row sample:
Now, let me explain a little things about the previous collected information...
-
You may see that this collection runs on the Ethereum network, but the actor was instructed to convert the currency amounts (
volume,volume24h,volumeLifetime,floorPriceandfloorPrice24h) to the one Binance uses. So,networkis 'ETH' andcurrencyis 'BNB'. -
Therefore, the
contractAddressbelongs to the Ethereum blockchain, and you can verify that here. -
As you have probably noticed, the amounts are represented as strings, and if you wonder why, don't forget that in the crypto world, every decimal matters and precision loss can lead to huge differences in currency conversions.
-
The amounts
volumeandfloorPrice, refer to the period selected by the user. For this example, it was 'Last 7 days' (run in September 2023 if you ask). -
The amounts
volume24handfloorPrice24hare obviously for the 'Last 24 hours'. And yes, since this same period can be selected from the list of options, doing it will result involumeandfloorPriceholding the same values, respectively. -
As pointed out previously in this document, rates (
volumeRate,volumeRate24h,floorPriceRateandfloorPriceRate24h) are expressed in percentages. ThevolumeRateandfloorPriceRatevalues will match the 'Last 24 hours' values when this is the selected period, consistently. -
This collection have NFTs with two possible attributes: 'Relic' and 'Role'. 'Relic' can be 'KodaPendant' only and there are 84 items with this value. 'Role' can be either 'Hunter', 'Farmer', or 'Enchanter' and there are 15793, 12239, and 7158 items with this value, respectively.
The results of the 'Collection assets' scraping mode use this other layout. Check this 1-row sample:
Remarkable elements about these new scraped results are:
-
assetTypeis usually 'NFT' but it can have other values such as 'Mystery Box'. -
assetMediaholds the URL of the raw NFT content. It uses to be the same asassetCover, whenmediaTypeis 'IMAGE'. But if it's 'VIDEO', the URL will point to an actual MP4 file (or another supported format). These URLs are permalinks, so you can download the files anytime. -
About the dates (
dateCreate,dateEnd,dateList, anddateStart), see that they adhere to the ISO 8601 format, in UTC to eliminate ambiguity and facilitate automated post-processing. -
Since
totalBidsis zero, bothhighestBidandlowestBidare 'null'. -
There are 4 offers for this asset, as you can see in the value of
totalOffers, but only thehighestOfferandlowestOfferare scraped. -
openRarityandopenRarityCountrefer to the OpenRarity standard for NFT rarity rankings, which Binance has now support for. The less the quotient of those values, the rarest the NFT is (the one in the example is pretty common: 9861/10000). But take note that it's a slowly adopting feature which not every collection includes, so this pair usually appears as 'null'. -
The arrays
platformFeesandroyaltyFeesare the fees you have to pay for trading with the asset in the website. Thus,productSourceis gonna be 'Binance', but other marketplaces such as 'OpenSea' can be included for third-party listed NFTs. Remember thatrate, just like other rates will be a percentage. I've not found anyvipRatewhich is not empty so far. It's there because the API includes it. That's all. -
You can find the 'Buy Now' price as
price, the price that the owner paid aspriceLastSold, and in case there's a running auction for the asset, the 'Place a Bid' price is now inprice, andpriceBuyoutcontains the immediate win price. -
The sample asset has values set for 5 traits: 'body' is 'combo 1 puffer', 'background' is 'grey', 'face' is 'sunglasses', 'head' is 'med', and 'hair' is 'green mullet'. The percentage of assets (in this collection) having 'combo 1 puffer' as 'body' is aproximately 3.5% (331 assets); for having 'grey' as 'background' is aproximately 7.8% (742 assets), etc.
-
rarity, as stated in the 'Collection assets' options, only applies for 'Mystery boxes' and 'Box-exclusive' NFTs. The possible values are 'Unopened', 'Normal', 'Rare', 'Super Rare', 'Super Super Rare', and of course 'null', meaning 'not applicable'. -
score, the previously discussed 'index of popularity' (when available), is a decimal value between 0 and 1. The highest values, closer to 1, correspond to the most popular assets. -
tokenId, along with thecontractAddress, helps to locate the NFT in its original marketplace. It can be used to auto-generate external links.
Output views
There are four type of available views for browsing and export your datasets. Two for collections and two for assets.
The way Apify works, there is no chance of enabling the availability of the views according to the current scraping mode. Hence, it's possible to browse a dataset with an incompatible view by mystake. Watch it. 😋
Please observe that 1️⃣, 2️⃣, and 3️⃣ identify the scraping mode. Remember that the scraping modes 'Specific collection(s)' and 'Collection rankings' share the same results layout.
-
1️⃣&2️⃣ Collections - Compact: this layout includes Cover, Id, Name, Network, Verified status, Currency, Volume, Volume rate, Volume 24h, Volume rate 24h, Floor price, Floor price rate, Floor price 24h, Floor price rate 24h, Total owners and Total items.
-
1️⃣&2️⃣ Collections - Detailed: same as 'Collections - Compact', but includes the collection URL, Contract address, Volume lifetime, Royalty fee rate, Total listed items and Properties.
-
3️⃣ Assets - Compact: this includes Cover, Id, Name, Type, Collection id, Collection name, Network, Verified status, Source marketplace, Currency, Price, Creator, Price last sold, Owner, Total bids, Total Offers, Total favorites, Score, Rarity and Open rarity
-
3️⃣ Assets - Detailed: same as 'Assets - Compact', but includes the asset Media type, URL, collection URL, Contract address, Category, Trade type, Token id, Product id, Creator URL, Owner URL, Royalty fees, Platform fees, Highest bid, Lowest bid, Highest offer, Lowest offer, Open rarity count, Create/List/Start/End dates and Properties
-
All fields: this one includes everything. Even some fields not shown in the custom layouts, at the expense of being a little messy.
That finishes this document. We gladly hope you have found this guide very helpful, but given the amount of sections covered, maybe we went too fast on something or even forgot one thing or two.
Feel free to contact us if you have any questions or need a custom development. 🙂
Happy scraping!