Google Maps Email Extractor & Lead Scraper
Pricing
from $5.00 / 1,000 results
Google Maps Email Extractor & Lead Scraper
Google Maps email scraper with built-in MX/SPF/DMARC validation + catch-all detection. 50-70% email hit rate (vs 0-15% English-only). Multilingual crawl (10+ langs: kapcsolat/kontakt/contacto/contatti/...). Lead scoring 0-100, delta mode ($0 dupes). PAY_PER_EVENT: $0.007/lead from 10 Aug.
Pricing
from $5.00 / 1,000 results
Rating
0.0
(0)
Developer
yestrue
Maintained by CommunityActor stats
1
Bookmarked
70
Total users
10
Monthly active users
an hour ago
Last modified
Categories
Share
Google Maps Email Extractor & Lead Scraper — Validated B2B Leads with Deliverability Grades
![]()
🆕 Companion actor — track which AI engines mention your business. Pairs perfectly with this lead-extractor: see whether the businesses you scrape (or your own brand) get cited in ChatGPT, Perplexity, Gemini, and Google AI Overviews across 24 languages. Bring-your-own-key, free with Gemini's free tier. → AI Search Visibility Tracker
⭐ 70+ teams have run this actor. If it saved you a manual data-extraction job, a 30-second review goes a long way — Store ranking runs on reviews, and that's how the next person finds it. 🔖 Bookmark it too, so you can launch new runs in one click.
The most advanced Google Maps lead-generation scraper on the Apify Store. Extracts everything competitors do — plus 13+ exclusive features no other scraper offers: geo-grid tiling (bypass Google's 120-result cap), email deliverability grading (MX/SPF/DMARC), web quality signals (lite Lighthouse), delta mode (skip already-scraped leads), Meta Ad Library enrichment (find active advertisers), Google CID for cross-query dedup, tech-stack detection, 0-100 lead scoring, AI-ready outreach profiles, review keywords, service options, business status, owner descriptions, and website language.
🏆 The 6 things no other Google Maps scraper has
- Geo-grid tiling — bypass Google's ~120-result cap. Set
geoGridTiles: 5and the actor splits your search into a 5×5 grid covering the whole city (25 tile viewports, auto-geocoded via OSM/Nominatim) — reach up to 1500+ unique leads for big cities like NYC, London, Berlin. Results are de-duplicated by placeId so you still get a single clean dataset. - Email deliverability grading — MX / SPF / DMARC / SMTP probe + catch-all detection before you send your first email (saves $0.01–0.03/email vs buying a separate validator like ZeroBounce or NeverBounce)
- Delta mode — pass a previous run's
sinceDatasetId, duplicates are filtered out before any event fires = pay $0 on daily/weekly re-runs - Meta Ad Library inline enrichment — each Facebook page's numeric ID is extracted and turned into a one-click Meta Ad Library URL (filter on active advertisers = confirmed marketing budget)
- Lead score 0–100 + AI-ready outreach profile — feeds straight into GPT/Claude prompts, zero data wrangling
- Multilingual contact-page crawl — detects
/kapcsolat,/kontakt,/impressum,/contacto,/contatti,/contactez-nous, etc. (10+ languages) → 50–70% email hit rate vs 0–15% for English-only competitors
💸 Transparent pricing — you pay only when leads are delivered
⏳ Until 10 August 2026 the live rate is still
$0.005per delivered lead +$0.00005per run start. The rates below take effect on 10 August 2026 — Apify applies a mandatory 14-day notice period to price changes, and existing users were notified on 27 July 2026.
PAY_PER_EVENT model — the fairest on the Apify Store:
$0.007per delivered business lead — flat rate, ALL enrichment included: Google Maps place data, email + 5-source extraction, tech-stack, web-quality grading, MX/SPF/DMARC email validation, lead scoring, AI-ready outreach profile, social links, Meta Ad Library URL$0.015per GB of run memory at start — $0.06 on the 4 GB default, covering browser launch and Maps session warm-up. Fixed per run, so it amortises away as runs get bigger: $0.0100/lead at 20 leads, $0.0071/lead at 1000.- No monthly subscription, no per-minute compute fee, no hidden charges
- 🛡️ Run failed before any lead was delivered? You pay
$0. PAY_PER_EVENT only bills for records actually written to the dataset — not for compute time, not for timeouts, not for network errors. - Delta mode drops cost to near $0 on weekly re-runs — duplicates are filtered out before any event fires
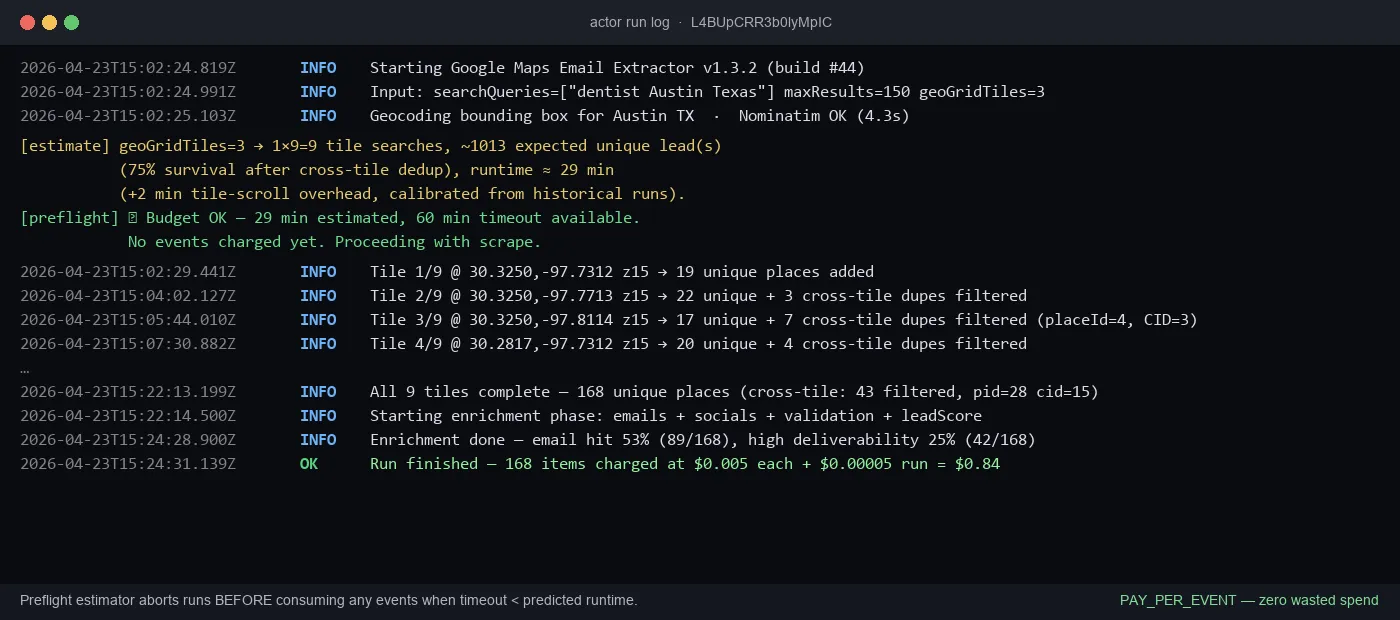
- Preflight budget check refuses to start (0 events billed) if your
maxResultswouldn't fit the run timeout — you'll never silently burn money on an impossible run. With auto-extend on (default), the actor auto-spawns a fresh run with a proper timeout — zero-touch UX.
| Search | Leads | Cost | Runtime |
|---|---|---|---|
| 25 Manhattan Italian restaurants | 25 | $0.24 | ~4 min |
| 20 London coffee shops | 20 | $0.20 | ~2.5 min |
| 20 Berlin dentists (German) | 20 | $0.20 | ~3.5 min |
| 100 plumbers in Chicago | 100 | $0.76 | ~15 min |
| 500 leads across 10 US cities | 500 | $3.56 | ~50 min |
| 500 leads — week 2 (delta mode) | ~50 new | $0.41 | ~6 min |
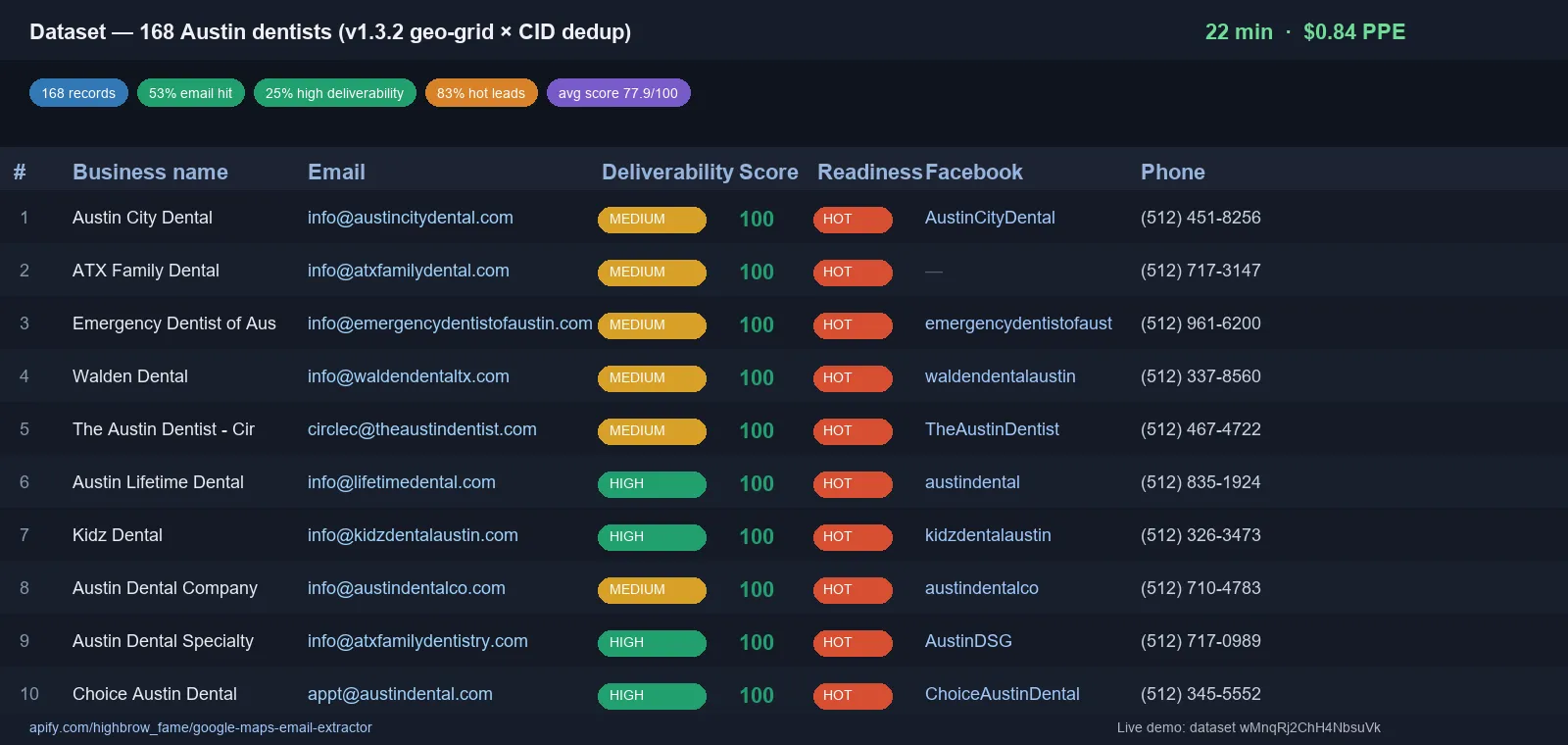
🔎 Live demo datasets — all publicly accessible, no auth: • 25 Manhattan Italian restaurants (64% email hit rate) • 20 London coffee shops (70% email hit rate) • 20 Berlin dentists (German) (85% email hit rate, 65% high deliverability)
Why this scraper beats every competitor
| Feature | This actor | Outscraper | Apify official | PhantomBuster |
|---|---|---|---|---|
| Email deliverability grade (MX/SPF/DMARC) | ✅ catch-all detection | ❌ | ❌ | ❌ |
| Web quality signals (lite Lighthouse) | ✅ HTTPS/mobile/pageSize | ❌ | ❌ | ❌ |
| Delta mode (skip already-scraped) | ✅ $0 for duplicates | ❌ | ❌ | ❌ |
| Meta Ad Library lookup URL | ✅ page-specific | ❌ | ❌ | ❌ |
| Email extraction from websites | ✅ 5-source + ranked | ✅ basic | ❌ | ❌ |
| Primary email auto-selection | ✅ domain-match algorithm | ❌ | ❌ | ❌ |
| Tech stack detection | ✅ WordPress/Wix/Shopify/... | ❌ | ❌ | ❌ |
| Lead score 0-100 | ✅ aggregate quality metric | ❌ | ❌ | ❌ |
| AI-ready outreach profile | ✅ GPT/Claude-ready | ❌ | ❌ | ❌ |
| Owner name extraction | ✅ 3-stage NLP pipeline | ❌ | ❌ | ❌ |
| Review keywords | ✅ | ❌ | ❌ | ❌ |
| Service options (delivery, Wi-Fi, etc.) | ✅ | ⚠️ partial | ❌ | ❌ |
| Business status (open/closed) | ✅ | ⚠️ partial | ❌ | ❌ |
| Owner description | ✅ | ❌ | ❌ | ❌ |
| Website language | ✅ | ❌ | ❌ | ❌ |
| Menu URL / Booking URL | ✅ OpenTable/Resy/Tock | ❌ | ❌ | ❌ |
| WhatsApp Business number | ✅ | ❌ | ❌ | ❌ |
| Cloudflare email decoding | ✅ | ⚠️ | ❌ | ❌ |
| ROT13 / JSON-LD parsing | ✅ | ❌ | ❌ | ❌ |
| Contact page crawl in 10 languages | ✅ | ⚠️ English only | ❌ | ❌ |
| Industry & cuisine classification | ✅ | ❌ | ❌ | ❌ |
50–70% email hit rate in testing (market-dependent) — significantly higher than competitors, which typically return 0–15%.
📊 Real demo data — three verticals, three countries, zero filtering
Every dataset below is publicly accessible — click any link, no account needed.
🗽 Italian restaurants — Manhattan, NYC
api.apify.com/v2/datasets/M9Bd8gMh4NglVKIbt/items
25 results • 4m 15s • $0.24 • 64% email hit rate • 56% owner name • 32% deliverability: "high"
☕ Coffee shops — Shoreditch, London
api.apify.com/v2/datasets/ROgK5EsNU6UtTSwFl/items
20 results • 2m 30s • $0.06 • 70% email hit rate • 40% deliverability: "high" • 79% FB page IDs
🦷 Zahnarzt (dentists) — Berlin Mitte (German)
api.apify.com/v2/datasets/gI04MuKrfPF4D4Ui8/items
20 results • 3m 30s • $0.07 • 85% email hit rate • 65% deliverability: "high" • 100% website coverage
Cross-vertical takeaway: email hit rates and deliverability grades vary 1.5-2× across industries and countries. Regulated markets (medical/EU) maintain the highest email hygiene. See the full cross-vertical breakdown in marketing/showcase.md.
Detailed metrics — Manhattan Italian restaurants
| Metric | Count | Rate |
|---|---|---|
| Places scraped | 25 | 100% |
| With email extracted | 16 | 64% |
With ownerName extracted | 14 | 56% |
With deliverability: "high" grade | 8 | 32% |
With catch-all detected | 0 | — |
| With Facebook page ID (Meta Ad Library) | 10 of 17 FB pages | 59% |
With webQuality: "modern" | 20 | 80% |
| With booking URL (OpenTable/Resy/Tock) | 14 | 56% |
| With social media | 23 | 92% |
Avg leadScore | 81.2 / 100 | — |
| Runtime | ~3 min | |
| Cost | ~$0.10 |
Who is this for?
- Sales teams who need pre-qualified, email-validated leads — skip the separate email verification step (saves $0.01-0.03/email)
- Cold-outreach operators protecting sender reputation — filter on
deliverability: "high"before firing the campaign - Web design agencies — filter on
webQuality: "dated"orhttpsOnly: falsefor perfect modernization leads - AI-powered outreach platforms consuming
aiLeadProfiledirectly into GPT/Claude prompts - Marketing agencies targeting active Facebook/Instagram advertisers (via
metaAdLibraryUrl) - Web dev / SaaS companies targeting specific CMS users (WordPress, Shopify, Squarespace)
- Recruiters finding claimed, operational businesses with working contact details
- Market researchers analyzing competitors, pricing, tech adoption, and review keywords
- Anyone running scheduled scrapes — delta mode means weekly re-runs cost near zero
🔥 Exclusive features (no other scraper has these)
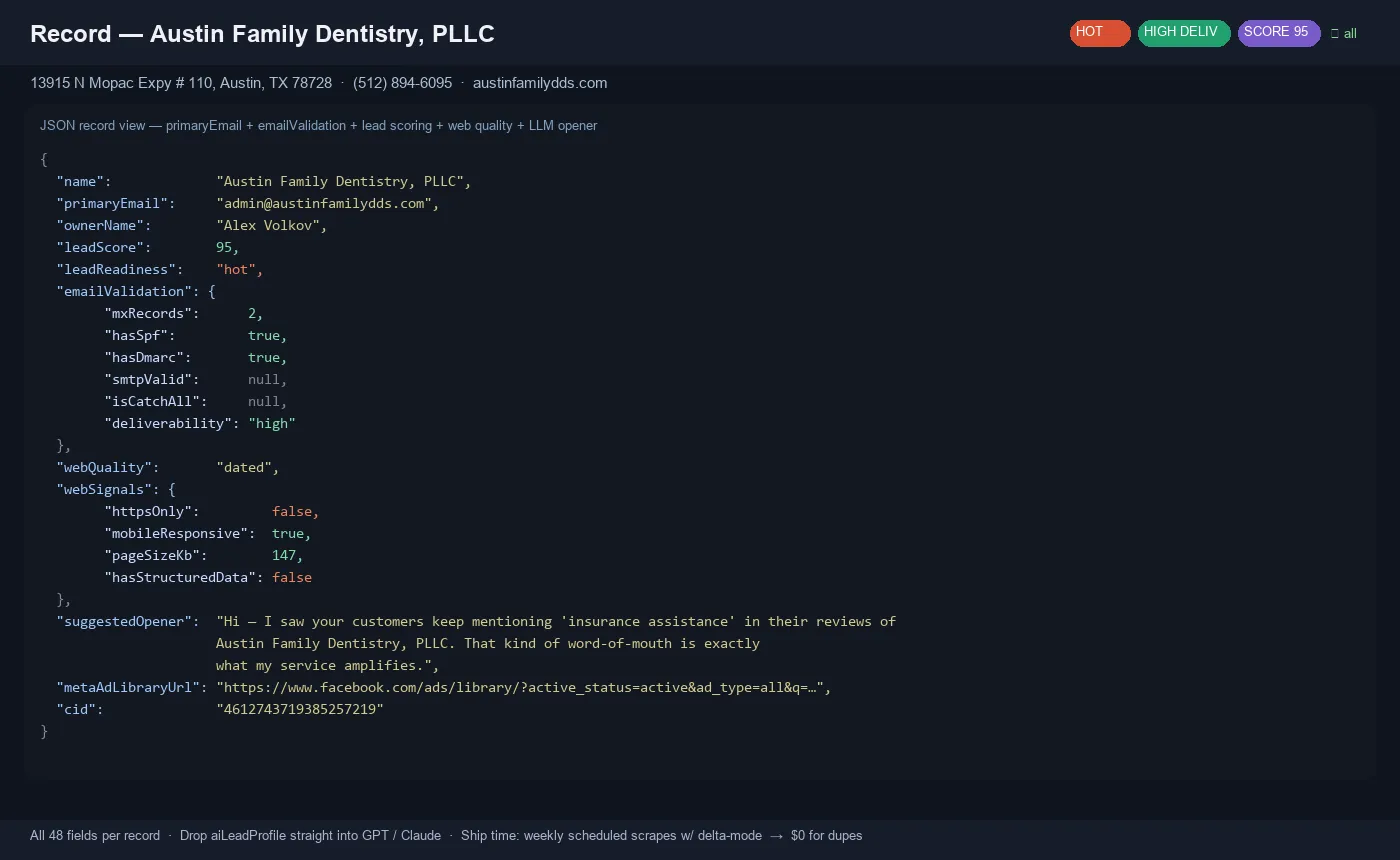
1. Email deliverability grading (MX / SPF / DMARC / SMTP)
Every primaryEmail is graded before you send outreach — so you don't burn sender reputation on invalid or catch-all addresses.
- MX lookup — 0 MX records = domain can't receive email (filter these out)
- SPF + DMARC — real businesses configure both (weak config = higher bounce risk)
- SMTP RCPT TO probe — gold-standard mailbox existence check + catch-all detection (best-effort; port 25 often blocked in cloud, gracefully degrades to DNS-only)
- Deliverability grade:
"high"/"medium"/"low"— sortable, filterable, ready for outreach automation
Why it matters: cold-outreach tools charge per verified email ($0.01-0.03 each — 10× our price). Our scraper delivers graded leads in one step.
2. Web quality signals — "lite Lighthouse"
Every homepage is inspected for quality indicators — zero extra cost because we already fetched the HTML.
Why it matters: web-dev agencies and SaaS companies can target businesses with dated or poor sites for redesign / modernization pitches. Example: a restaurant with httpsOnly: false and webQuality: "poor" is a hot lead for a web agency.
3. Delta mode — pay $0 for leads you already have
Pass a previous run's dataset ID via sinceDatasetId and the actor skips every place already scraped (matched by either Google Maps placeId or the Google cid). Duplicate-filtering happens before detail-page fetch, so no place-scraped events fire for known leads = zero cost for duplicates.
Since v1.3.2 the delta matcher uses two keys — placeId catches the common case, and cid catches the occasional edge case where Google serves the same business under slightly-different placeIds across query contexts (localization, partnership tier, claim status). Users on scheduled weekly scrapes see near-100% dedup coverage.
Perfect for scheduled runs: daily/weekly recurring scrapes where you only want NEW leads.
4. Meta Ad Library URL — find active advertisers
For every business with a Facebook URL, the actor fetches the page and extracts the numeric Facebook page ID, then builds a targeted Meta Ad Library lookup URL (not a noisy keyword search — the actual page's ads).
Why it matters: actively-advertising businesses have confirmed marketing budget = high purchase intent for B2B outreach selling marketing tools, analytics, creative services.
4.5. 🎯 Geo-grid tiling — bypass Google's 120-result cap (v1.3.0)
Google Maps returns at most ~120 places per search, regardless of how many actually match. Small town? Fine. Trying to scrape every restaurant in Manhattan (800+), every dentist in London (1200+), every plumber in Chicago? You never see the long tail.
Set geoGridTiles (1–10) and the actor splits your search area into an N×N geographic grid, hitting each tile's map viewport with the same keyword. Overlapping results are de-duplicated by placeId at enqueue time — the final dataset is one clean list, billing is linear in unique leads (not in tiles).
| Grid size | Tiles | Typical max coverage | Best for |
|---|---|---|---|
| 1 (default) | 1 | ~120 leads | small towns, quick runs |
| 3 | 9 | ~600 leads | mid-size cities (Budapest, Lyon, Porto) |
| 5 | 25 | ~1500 leads | big cities (Berlin, London, Chicago) |
| 10 | 100 | ~6000 leads | mega-cities (NYC, Tokyo, Seoul) |
How it works under the hood:
- Query parser detects
"{term} in {location}"/"{term} near {location}"/ plain"{term} {location}"patterns - Free OpenStreetMap Nominatim geocode (1 call per query, no API key) → bounding box
- Bounding box split into N×N tiles, each with a lat/lng span
- Each tile maps to a Google Maps zoom level via
zoom ≈ log2(0.7 / latSpanDeg) + 10, empirically calibrated against Google's public zoom table - Tile URLs:
https://www.google.com/maps/search/{term}/@{lat},{lng},{zoom}z?hl={lang}— each viewport is independently searched placeId-based run-scoped dedup prevents double-enqueue when neighbouring tiles overlap- If geocoding fails (unknown location, Nominatim down): silent fallback to a single untiled search — no crashes
Billing reality check: 5×5 tiles discovering 1500 unique leads costs 1500 × $0.007 = $10.50 + $0.06 run start. Same per-lead rate as a single-tile run — you pay for data, not for the crawl budget.
4.7. 🔑 Google CID — stable cross-query primary key (v1.3.0)
Every dataset row now includes a cid field — the numeric Customer ID Google uses internally for a business. Two extraction paths: the ?cid=<DECIMAL> pattern in share URLs, and the second hex group of the !1s0xHEX:0xHEX feature-ID token (converted to decimal via BigInt, 64-bit safe).
Why it's useful:
- Merge datasets from different queries — the same business discovered via
"pizza Manhattan"+"italian restaurants Manhattan"always has the samecid. Use it as your JOIN key in SQL / pandas. - Reconstruct a share URL —
https://maps.google.com/?cid={cid}opens the place page regardless of language/region. The hexplaceIdformat occasionally drifts between Google runtime updates; the decimal CID is rock-solid. - Tile dedup insurance — when
geoGridTiles > 1, the SEARCH handler usesplaceIdto skip the second enqueue of overlapping tiles. BothplaceIdandcidend up in the output for downstream dedup.
5. Tech stack / CMS detection
Detect the platform, e-commerce engine, frameworks, analytics, and marketing tools used on each business website. Over 40 technologies detected:
- Website builders: Wix, Squarespace, Webflow, Duda, Weebly, GoDaddy Builder, Jimdo
- CMS: WordPress, Drupal, Joomla, Ghost, HubSpot CMS
- E-commerce: Shopify, WooCommerce, BigCommerce, Magento, PrestaShop
- Frontend: Next.js, Nuxt, Gatsby, React, Vue, Angular
- Marketing: Google Analytics, Facebook Pixel, HubSpot, Mailchimp, Intercom, Calendly, Hotjar
- Booking: OpenTable, Resy, Tock, TheFork, Booking.com, SevenRooms
Why it matters: Target businesses on legacy platforms (Wix, Weebly, GoDaddy Builder) for upgrade pitches. Target WooCommerce stores for plugin sales. Target Shopify for e-commerce consulting.
6. Lead Score (0-100) + Readiness tier
Each lead gets an aggregated quality score from 0 to 100:
| Range | Readiness | Meaning |
|---|---|---|
| 70-100 | hot | Domain-matched email, claimed, good reviews, social, etc. — outreach immediately |
| 45-69 | warm | Has some signals — worth personalized outreach |
| 25-44 | cold | Basic data only — needs enrichment before outreach |
| 0-24 | dead | Low-signal — likely not worth the time |
Scoring breakdown (max 100): +25 domain-matched email, +10 any email, +10 phone, +10 website, +15 claimed, +10 rating ≥ 4.0, +10 reviews ≥ 20, +10 social media, +5 contact form, +5 modern tech stack.
7. AI-Ready Lead Profile
A pre-digested outreach profile ready to feed into GPT-4, Claude, or Gemini prompts — so your cold-email automation doesn't have to reinvent the wheel.
Plug aiLeadProfile directly into your LLM prompt:
"Write a cold outreach email to
{businessSummary}. Mention one outreach hook from:{outreachHooks}. Address this pain point:{painSignals[0]}. Personalize with:{personalizationContext}."
8. Review keywords
Google Maps aggregates what customers mention in reviews. We extract those keywords so you can:
- Open cold emails with "I saw your customers love your
{keyword}..." - Understand what the business is known for, at a glance
- Spot positioning opportunities (e.g. everyone mentions "slow service" → sell CRM automation)
9. Service options / amenities
- Restaurants: Delivery, Takeout, Dine-in, Reservations, Outdoor Seating, Kids Menu, Vegan Options, Halal Food, Live Music, Cocktails, Wine, Breakfast, Brunch…
- Retail / Services: Accepts Credit Cards, Wheelchair Accessible, Wi-Fi, Free Parking, Pet-Friendly, LGBTQ+ Friendly, Good for Groups…
Over 60 service options detected.
10. Business status
operational / temporarily_closed / permanently_closed — so your sales list is never polluted with dead businesses.
11. Owner description ("from the owner")
The description the business owner wrote themselves on Google My Business. Perfect source for authentic voice and tone when personalizing outreach.
12. Industry & cuisine classification
Every business is classified into one of 14 coarse industry buckets (Food & Beverage, Healthcare, Legal Services, Beauty & Wellness, Fitness & Sports, …) and restaurants get a cuisine tag (Italian, Japanese, Mexican, BBQ, …). Makes filtering and segmentation trivial.
Core features
✅ Searches Google Maps by keyword + location (e.g., "dentists in London")
✅ Extracts: name, address, phone, WhatsApp, website, rating, review count, category, industry, cuisine, opening hours, price level
✅ GPS coordinates (latitude, longitude, plusCode) for mapping & geo-analysis
✅ Visits business websites to find emails via 5 independent extraction sources
✅ Crawls contact subpages in 10+ languages (/contact, /kapcsolat, /kontakt, /impressum, /contacto, /contatti, etc.)
✅ Decodes Cloudflare-obfuscated emails (data-cfemail attribute)
✅ Parses JSON-LD / schema.org structured data for contact info
✅ Deobfuscates text patterns like info [at] domain [dot] com, HTML entities, ROT13
✅ Ranks emails by relevance — primary email = domain match with business website
✅ WhatsApp Business number extraction from wa.me/ and api.whatsapp.com links
✅ Contact form detection — flags businesses that accept contact via form only
✅ Social profiles on Facebook, Instagram, LinkedIn, Twitter/X, YouTube, TikTok
✅ Menu URL and Reservation URL (OpenTable, Resy, Tock, TheFork)
✅ Multi-layer false-positive filtering (placeholder emails, tracking pixels, font authors)
✅ Works in any language — Hungarian, German, Spanish, English, etc.
✅ Proxy support with Apify residential proxies
✅ Export to JSON, CSV, Excel, or connect via API / webhook
Input
| Field | Type | Description | Default |
|---|---|---|---|
searchQueries | Array of strings | Search terms like "plumbers in Chicago" | [] |
startUrls | Array of URLs | Direct Google Maps URLs to scrape | [] |
maxResults | Integer | Max results per query (0 = unlimited). Default is 25 — enough to judge a real market, still under ~3 min. Production: 100–1000. | 25 |
geoGridTiles | Integer | 🎯 Geo-grid tiling: split each search into N×N tiles to bypass Google's ~120-result cap. 1=off, 3=9 tiles (mid-city), 5=25 tiles (big city), 10=100 tiles (mega-city). Geocoded via free OSM/Nominatim. | 1 |
autoExtend | Boolean | If run timeout is too short for requested maxResults, auto-spawns a fresh run with proper timeout — zero-touch UX | true |
validateEmails | Boolean | MX / SPF / DMARC / SMTP deliverability grading on every primary email | true |
extractWebSignals | Boolean | Lite Lighthouse: HTTPS / mobile-responsive / page size / Open Graph / structured data | true |
enrichMetaAds | Boolean | Extract Facebook numeric page ID + build Meta Ad Library URL for each business | false |
sinceDatasetId | String | Delta mode: pass a previous dataset ID to skip already-scraped places (pay $0 for duplicates) | — |
scrapeEmails | Boolean | Visit websites to find emails + tech stack | true |
scrapeSocials | Boolean | Extract social media links | true |
maxConcurrency | Integer | Parallel browser pages | 5 |
language | String | Google Maps language code | en |
proxyConfiguration | Object | Proxy settings | Apify residential |
Example input
Example: comprehensive city coverage with geo-grid tiling
This splits Manhattan into a 5×5 grid (25 tiles), scrapes each tile's ~120-result viewport, de-duplicates overlapping places by placeId, and returns up to ~1500 unique Italian restaurants with validated emails. Billing stays linear in unique leads — 1500 leads × $0.007 = $10.50 + $0.06 run-start fee. Without tiling you'd max out at ~120 results no matter how high you set maxResults.
Output
Each result contains complete business contact information plus all the exclusive scoring and profiling fields:
Output fields reference
| Field | Description |
|---|---|
leadScore | 0-100 aggregate lead quality score — sort by this to prioritize outreach |
leadReadiness | hot / warm / cold / dead — readiness bucket derived from leadScore |
aiLeadProfile | Pre-built outreach profile with business summary, hooks, pain signals, personalization context — feeds directly into LLM prompts |
techStack | Array of detected technologies (CMS, e-commerce, analytics, marketing tools) |
industry | One of 14 coarse industry buckets |
cuisine | Cuisine tag for restaurants |
businessStatus | operational / temporarily_closed / permanently_closed |
businessDescription | Owner-written description from Google My Business |
serviceOptions | Array of delivery/amenity tags |
reviewKeywords | Array of keywords customers mention in reviews |
primaryEmail | Single best email — domain matches business website when possible |
emails | All found emails, ranked by relevance (primaryEmail is always emails[0]) |
bookingUrl | Reservation / booking URL (OpenTable, Resy, Tock, TheFork) |
menuUrl | Direct URL to the restaurant's menu |
hasContactForm | true if the site has a contact form (useful when primaryEmail is null) |
whatsapp | E.164 WhatsApp Business number |
websiteLanguage | ISO code of the website's primary language (en, hu, en-us, …) |
latitude / longitude | GPS coordinates for mapping and geo-analysis |
plusCode | Google's short location code |
placeId | Hex-pair Google Maps feature ID (0xHEX:0xHEX) — used by delta mode for dedup |
cid | 🔑 Google Customer ID (decimal) — stable cross-query primary key. https://maps.google.com/?cid={cid} opens the place page. |
How it works
- Google Maps Search — Uses a Playwright browser to search Google Maps, scroll through all results, and collect business listing URLs.
- Place Data Extraction — Visits each business page to extract name, address, phone, website, rating, review count, category, opening hours, GPS, price level, business status, owner description, service options, review keywords, menu URL, reservation URL, claimed status, plus code.
- Website Analysis — Uses a fast Cheerio crawler to visit each business website and extract emails from five independent sources:
mailto:anchor links- Cloudflare-obfuscated email tags (
data-cfemail) - JSON-LD / schema.org structured data
- Text deobfuscation (
info [at] domain [dot] com, HTML entities, ROT13) - Regex pattern matching on the rendered HTML
- Tech stack fingerprinting — Detects 40+ technologies from script URLs, meta generators, class names, and DOM attributes.
- Contact page fallback — If the homepage yields no email (or only third-party emails), the actor automatically follows
/contact,/kapcsolat,/kontakt,/impressum,/contacto,/contatti,/contactez-nous, etc. - Email ranking — Emails are ranked so the best one (matching the business domain) becomes
primaryEmail. - Scoring + profiling — Every record gets a
leadScore,leadReadinessbucket, and a fullaiLeadProfileready for LLM consumption. - Smart filtering — Removes placeholder emails (
user@domain.com), Sentry DSNs, font-author emails, image filenames, tracking URLs, and other common false positives.
How much will it cost to scrape {city} businesses?
PAY_PER_EVENT pricing is deterministic — you can calculate the max spend before starting a run:
Total = (leads × $0.007) + ($0.015 × run memory in GB) (the second term is the one-time actor-start fee — $0.06 on the 4 GB default)
Every delivered lead is $0.007 flat — includes Google Maps place data, website scraping, email extraction, email deliverability grading, tech-stack detection, web-quality signals, lead scoring, and AI-ready outreach profile. Delta mode filters duplicates before they're counted, so week-2 reruns with sinceDatasetId only charge for new leads.
The run-start fee covers the browser launch and Google Maps session warm-up that every run pays regardless of how much it returns. It is fixed, so the more leads per run, the less each lead costs you — see the effective-rate column below.
Cost-per-city examples (real benchmarks)
| Query | Leads | Email hit rate | Cost | Effective $/lead | Runtime |
|---|---|---|---|---|---|
| Coffee shops in Shoreditch, London (20) | 20 | 70% | $0.20 | $0.0100 | ~2.5 min |
| Italian restaurants in Manhattan (25) | 25 | 64% | $0.24 | $0.0094 | ~4 min |
| Restaurants in Budapest (50) | 50 | 60% | $0.41 | $0.0082 | ~8 min |
| Dentists in Berlin (50) | 50 | 85% | $0.41 | $0.0082 | ~9 min |
| Plumbers in Chicago (100) | 100 | 50-60% | $0.76 | $0.0076 | ~15 min |
| Dermatologists in LA (100) | 100 | 55% | $0.76 | $0.0076 | ~16 min |
| Real estate agents in Sydney (200) | 200 | 65% | $1.46 | $0.0073 | ~32 min |
| Law firms in New York City (300) | 300 | 70% | $2.16 | $0.0072 | ~50 min |
| 1000 leads / full unlimited run | 1000 | 55-65% | $7.06 | $0.0071 | ~2.5 h |
Cost estimation — architecture notes
- Flat per-lead pricing means no surprise bills regardless of how many enrichment sources we consult. If we visit 3 contact subpages in 4 languages to find the email, you still pay $0.007, not more.
- Delta mode = $0 for every duplicate (placeId match), perfect for weekly scheduled runs
- Preflight refuses impossible runs (0 events billed on refusal)
- You are never charged for failures, timeouts, or network errors — only for leads actually written to the dataset
- The run-start fee is charged once per GB of run memory. Lowering the run's memory lowers it, but the default 4 GB is what the crawler is tuned for — dropping below that trades $0.015 for a much slower run (measured: halving memory to 2 GB made the Maps phase 5.4× slower).
Use cases — what the new features unlock
🎯 Sales prospecting
Sort leads by leadScore desc → outreach only to hot leads. Filter by leadReadiness === 'hot' for instant prioritization.
🎯 Tech-stack targeted campaigns
→ businesses on Wix without e-commerce — perfect target for "upgrade to WooCommerce + Shopify" pitches.
🎯 AI cold-outreach at scale
Loop over records, feed aiLeadProfile into a GPT-4 prompt, generate personalized email in 1 LLM call per lead.
🎯 Agency lead-gen
Filter industry === 'Food & Beverage' && cuisine === 'Italian' && businessStatus === 'operational' && leadReadiness !== 'dead' → Italian restaurant leads ready for outreach.
🎯 Expansion research
Group by websiteLanguage + industry → map market coverage by language.
🎯 Dead-data filtering
Drop businessStatus === 'permanently_closed' automatically — no more wasted outreach.
Tips for best results
- Use specific queries — "Italian restaurants in Manhattan, NYC" works better than just "restaurants"
- Residential proxies recommended — Google Maps is more likely to block datacenter IPs
- Lower concurrency if blocked — Reduce
maxConcurrencyto 2-3 if you see failures - Use
leadScorefiltering — sort by score desc to focus on best prospects - Plug
aiLeadProfileinto your LLM — skip the data-wrangling step entirely - Check
hasContactForm— businesses without scrapable emails often still accept contact via form
Email hit rates by market (from real test runs)
| Market | Sample | Email Hit Rate | Primary-email Domain Match |
|---|---|---|---|
| US restaurants (Manhattan) | 20 | 65-70% | 50% |
| Hungarian dentists (Budapest) | 15 | 53-67% | 40% |
| European small businesses | — | 50-60% | 40% |
Business sites using contact-form-only UX (no email published anywhere) are the main reason for "no email" results — these are flagged as hasContactForm: true so you can still reach them.
Integrations
- Zapier / Make — Automate lead flow to any app
- Google Sheets — Export directly to spreadsheets
- API access — Fetch results programmatically via the Apify API
- Webhooks — Get notified when a run completes
- Direct LLM consumption — Feed
aiLeadProfileinto OpenAI / Anthropic APIs for cold-email generation
Legal & Compliance
Disclaimer: This section is general information, not legal advice. Consult qualified counsel for your specific use case and jurisdiction. The author is not responsible for how the extracted data is used.
What the scraper collects
| Data type | Privacy classification | Typical legal basis |
|---|---|---|
| Business name, address, phone, website, hours | Public business data | No special basis needed |
| Coordinates, ratings, review counts, categories | Public business data | No special basis needed |
Generic emails (info@, contact@, sales@) | Corporate contact info (GDPR Recital 14: not clearly "personal") | Legitimate interest (B2B) |
Personal emails (firstname.lastname@...) | Personal data under GDPR | Legitimate interest + opt-out, or consent |
ownerName | Personal data under GDPR | Legitimate interest + opt-out, or consent |
| Social media profile URLs | Mixed — often personal | Legitimate interest (if public profile) |
Is it legal to scrape Google Maps?
- Google's Terms of Service prohibit automated access — this is a contractual restriction, not criminal law. Enforcement is typically technical (IP / account bans), not legal action.
- Courts have ruled (notably hiQ Labs v. LinkedIn, U.S. 9th Circuit 2022) that scraping publicly accessible data is generally not a violation of computer-misuse statutes like the CFAA.
- EU case law (e.g. Ryanair v. PR Aviation) treats ToS violations as civil matters, not criminal.
Bottom line: scraping public business listings is not criminal in the U.S. or EU, but it does violate Google's ToS. Use residential proxies and respectful rate limits to minimize detection.
What you can do with the data
✅ Clearly permitted
- Internal market research — competitor analysis, territory planning, aggregate statistics
- B2B outreach to generic addresses (
info@,sales@,contact@) — covered by legitimate interest under GDPR Art. 6(1)(f), provided you include a clear opt-out - Lead qualification and CRM enrichment for your own business
- Academic / journalism research on market dynamics
⚠️ Requires careful compliance
- B2B outreach to personal work emails — requires documented Legitimate Interest Assessment (LIA) + clear opt-out + respect for prior opt-outs
- Reselling the dataset to third parties — you become a joint controller; proper contracts and data-subject rights required
- Processing data of EU / UK / California residents — GDPR / UK GDPR / CCPA apply; privacy notice and data-subject rights workflow required
❌ Do not do this
- Spam campaigns without opt-out — illegal under GDPR, CAN-SPAM (US), PECR (UK), Ekertv. (Hungary), CASL (Canada)
- Selling personal data without lawful basis — GDPR violations, fines up to €20M or 4% of global turnover
- Impersonating the data subject or using data for fraud / harassment
- Bypassing robots.txt or explicit opt-out signals on business websites
- Scraping facial or biometric data from social profiles (restricted globally)
Your responsibilities as the user
-
Be the controller: when you run this actor, you are the data controller under GDPR. The actor author / Apify is a processor at most. You are responsible for:
- Lawful basis (typically legitimate interest for B2B)
- Privacy notice accessible to data subjects
- Handling data-subject requests (access, erasure, objection)
- Data retention limits (don't keep forever — delete when no longer needed)
- Security of stored data
-
Document your Legitimate Interest Assessment if you rely on Art. 6(1)(f). A simple 3-test LIA template:
- Purpose test: Why do we need this data? (e.g. "prospecting for B2B sales")
- Necessity test: Is scraping the least intrusive way? (e.g. "yes — the data is already public")
- Balancing test: Do our interests outweigh the data subject's rights? (e.g. "yes for generic business contacts with opt-out; no for senior personal emails without prior relationship")
-
Include opt-out in every outreach: an unsubscribe link or a "reply STOP" mechanism on every message. Suppress replied-opt-outs across all future campaigns.
-
Respect suppression lists: never re-contact someone who has objected, even if they show up in a future scrape.
-
Local rules: some jurisdictions (France, Germany, Italy) require prior opt-in for cold email even in B2B — check your target market's rules.
For Apify Store users
If you run this actor via the Apify Store, the data controller is you (the user), not Apify or the actor author. The per-event pricing covers infrastructure only; it does not transfer legal responsibility.
Useful references
- GDPR full text — Art. 6 (legal bases), Recital 47 (legitimate interest for direct marketing)
- ICO guidance on direct marketing (UK)
- FTC CAN-SPAM Act guide (US)
- hiQ Labs v. LinkedIn (scraping case law)
- NAIH (Hungarian DPA) — for Hungarian users
One-sentence summary
Public business data → OK to scrape; personal data → handle per GDPR; unsolicited spam → always illegal; you (not the tool) are responsible for the use.
FAQ — common questions
How does this differ from other Google Maps email scrapers on Apify?
Three concrete differences:
-
Email validation is built-in. Most scrapers return raw emails — you then pay $0.01–0.03 per email to a separate service like NeverBounce, ZeroBounce, or Bouncer to check deliverability. This actor performs MX-record probing, SPF and DMARC TXT lookups, optional SMTP RCPT-TO probe, and catch-all detection inline, and grades each email as
high,medium,low, orunknown. Filter onemailValidation.deliverability === "high"before you send your first cold email. -
Multilingual contact-page crawl. Most scrapers only fetch
/contactand/contact-us. This actor matches localized contact-page URLs in 10+ languages — Hungarian (kapcsolat,elérhetőség), German (kontakt,impressum,ansprechpartner), Spanish (contacto,contactenos), Italian (contatti,contattaci), French (contactez-nous,nous-contacter), Polish (kontakt-z-nami,kontakty), and others. Result: 50–70% email hit rate vs 0–15% for English-only crawlers, especially in EU markets. -
Delta mode pays $0 for re-scraped leads. Pass the previous run's dataset ID as
sinceDatasetId— already-seenplaceIdandcidvalues are skipped before any billable event triggers. Weekly schedules cost the same as one-off runs because you only pay for genuinely new leads.
Is the actor pay-per-result or pay-per-CPU?
Pay-per-result (PAY_PER_EVENT model). Flat $0.007 per delivered business lead + $0.015 per GB of run memory at start ($0.06 on the 4 GB default). No CU charges, no surprise bills from long crawls. Failed or timed-out runs cost $0 — you only pay for actual data.
What's the email hit rate?
Tested across multiple verticals:
| Market | Sample | Email Hit Rate | High Deliverability |
|---|---|---|---|
| Austin TX dentists (US) | 168 leads | 53% | 25% |
| Manhattan Italian restaurants (US) | 25 leads | 64% | 32% |
| Shoreditch coffee shops (UK) | 20 leads | 70% | 40% |
| Berlin Mitte dentists (DE) | 20 leads | 85% | 65% |
Regulated markets (medical/EU) tend to maintain higher email hygiene. See full demo datasets in the Examples section above.
Does it work for non-English locations?
Yes. The Google Maps query and the website crawl both work for any language and country. The contact-page localization built into the crawler covers Hungarian, German, French, Italian, Spanish, Portuguese, Polish, Dutch, and Czech URLs — so a search for "Zahnarzt Berlin" or "fogorvos Budapest" or "dentista Madrid" returns the same record schema as an English query.
Will my run hit the timeout?
Probably not — the preflight budget check estimates expected runtime based on geoGridTiles and historical calibration. If the estimate exceeds your actor timeout, the run refuses to start (zero events charged) and tells you exactly what to lower (or it auto-spawns a fresh run with a longer timeout if autoExtend: true, the default). You will not silently burn money on an impossible run.
Can I use the output in a CRM or AI workflow?
Yes — the per-record schema includes:
aiLeadProfile— drop straight into a GPT/Claude prompt to generate a personalized emailsuggestedOpener— pre-generated 1–2 sentence cold-email opener using review keywordsmetaAdLibraryUrl— check whether the prospect runs Facebook/Instagram adswebSignals—httpsOnly,mobileResponsive,pageSizeKb,hasStructuredDatafor tech-fit scoringleadScore(0–100) andleadReadiness(hot/warm/cold) for prioritization- All standard CRM fields (
name,address,phone,website,primaryEmail,category,industry,cuisine,rating,reviewCount, etc.)
Pipe the dataset into HubSpot, Salesforce, Pipedrive, Close, or any tool that ingests CSV / JSON.
What countries / verticals work best?
| Vertical | Markets where this excels |
|---|---|
| Local services (dentists, plumbers, electricians, salons) | EU especially (high email hygiene + regulated industries) |
| Restaurants / hospitality | Tourist cities (London, Manhattan, Barcelona, Berlin) — high website coverage |
| B2B services (agencies, consultancies, law firms) | Anywhere with claimed Google Business Profiles |
| Auto / repair | Mid-size US/EU cities — high phone coverage even when emails sparse |
| Healthcare | EU (DACH/Iberia) — 80%+ email hit rates seen in tests |
Can it scrape reviews / ratings as well?
Yes — the standard output includes rating, reviewCount, and reviewKeywords (top customer-mentioned terms — "authentic pasta", "great service", "cozy", etc.). Use these to:
- Filter for highly-rated businesses (
rating >= 4.5) - Sort by social proof (
reviewCount > 50) - Personalize cold-email openers using the prospect's own review keywords
How do I run a recurring scrape that doesn't pay for duplicates?
Schedule a weekly run with sinceDatasetId set to your previous run's dataset ID. The actor uses dual-key matching (placeId + cid) to skip already-seen places before any billable event fires. Same per-lead rate as a one-off run, but only new businesses incur a charge.
Is the actor open-source?
The published actor is closed-source on Apify — the source is hidden via isSourceCodeHidden: true. You can see the README, run the actor, and read the dataset schema, but the implementation is the author's IP.
What does it NOT do?
Honest list of limitations:
- No phone validation — phones are extracted as Google Maps lists them, no carrier-lookup or live ping
- No social-engagement scraping — extracts social URLs, but not follower counts, post engagement, or DMs
- No bulk export to CSV/XLSX from inside the actor — but Apify Store has built-in export tooling on the dataset page (CSV, Excel, JSON, JSONL, XML, RSS, HTML)
- No CAPTCHA bypass for Google Maps — uses standard residential-proxy-based crawling; if Google blocks, the actor backs off (you don't pay for blocked requests)
- No phone scraping from contact pages if the page hides phones behind JS or images (rare)
How this compares to other Google Maps scrapers
| Feature | This actor | Compass GMS | Lukas Krivka | Most others |
|---|---|---|---|---|
| Email extraction | ✅ | ✅ (paid add-on) | ✅ | ✅ |
| Email deliverability validation (MX/SPF/DMARC) | ✅ inline | ❌ | ❌ | ❌ |
| Catch-all detection | ✅ | ❌ | ❌ | ❌ |
| Multilingual contact-page crawl (10+ langs) | ✅ | partial | ❌ | ❌ |
| Lead scoring 0-100 | ✅ | ❌ | ❌ | ❌ |
| Delta mode (pay $0 for duplicates) | ✅ | ❌ | ❌ | ❌ |
| Preflight budget check (refuses wasteful runs) | ✅ | ❌ | ❌ | ❌ |
AI-ready outreach profile (aiLeadProfile) | ✅ | ❌ | ❌ | ❌ |
| Meta Ad Library URL | ✅ | ❌ | ❌ | ❌ |
| Tech-stack signals (HTTPS, responsive, page weight) | ✅ | ❌ | ❌ | ❌ |
| Pricing model | PPE flat $0.007/lead + $0.06/run | CU-based + add-ons | CU-based | CU-based |
| Reviews on Apify Store | building | 1242 (4.76★) | 176 (4.32★) | varied |
If you only need raw emails and you're scraping at million-record scale, Compass GMS is the established giant — well-tested, supported by the Apify team. If you need validated, scored, AI-ready B2B leads with EU multilingual coverage, this actor is built specifically for that workflow.
Use the right tool for the job
| If you want… | Use |
|---|---|
| Massive volume (1M+ leads), raw data, no validation | Compass crawler-google-places |
| Email + basic contact details only, English markets | Lukas Krivka google-maps-with-contact-details |
| Validated, deliverable B2B emails for cold outreach | This actor |
| Multilingual EU markets (HU/DE/FR/IT/ES) | This actor |
| Recurring scrapes with $0 duplicate cost | This actor |
| Lead scoring + AI-personalized outreach | This actor |