AI Search Visibility Tracker — ChatGPT, Perplexity, Gemini
Pricing
Pay per event
AI Search Visibility Tracker — ChatGPT, Perplexity, Gemini
Track brand citations in ChatGPT, Perplexity, Gemini, Google AI Overviews. Multilingual (24 languages incl. Hungarian, German, French, Polish, Czech). Bring-your-own-key — start FREE with Gemini's free tier. Daily diff. Pay-per-query, no monthly minimums. Cheapest GEO/AEO tracker on Apify.
AI Search Visibility Tracker — ChatGPT, Perplexity, Gemini, Google AIO
Track if your brand or domain gets cited in ChatGPT, Perplexity, Gemini, and Google AI Overviews — across 24 languages, with daily diff alerts and a stability score across multiple samples. Bring-your-own-key model — start at $0/month with Gemini's free tier.
⭐ If this actor saves you time, please rate it on Apify. Reviews raise its Store visibility and help the next person find it.
Table of contents
- Why this actor
- What it does
- Quick start ($0/month)
- Comparison vs Otterly / Profound / Peec / Semrush
- Engine support — Gemini, ChatGPT, Perplexity, Claude
- Output schema
- Stability score — filter out hallucinations
- Delta mode — week-over-week diff
- Recipes
- Use cases by persona
- Pricing
- FAQ
- Troubleshooting
- Local development
- Architecture
- Limitations / honest disclosure
- Roadmap
Why this actor
The Generative Engine Optimization (GEO) tracker market in 2026 is dominated by enterprise tools — Otterly ($29–489/mo), Profound ($99–2k+/mo, no free trial), Peec AI (€89–199/mo), Semrush AI Toolkit ($99–549/mo), Ahrefs Brand Radar ($328+/mo). They share three blind spots:
- Pricing locks out indie SEOs and small agencies — the cheapest viable tier is $29/mo for 15 prompts.
- Multilingual coverage is shallow — Semrush admits "US English only," Profound and Otterly are English-first.
- No bring-your-own-key option — you pay them, they pay the LLM vendors, and you can't see the underlying call.
This actor flips all three:
- $0/month entry point — supply your own free Gemini API key (250 queries/day on the free tier) and run end-to-end at zero marginal cost.
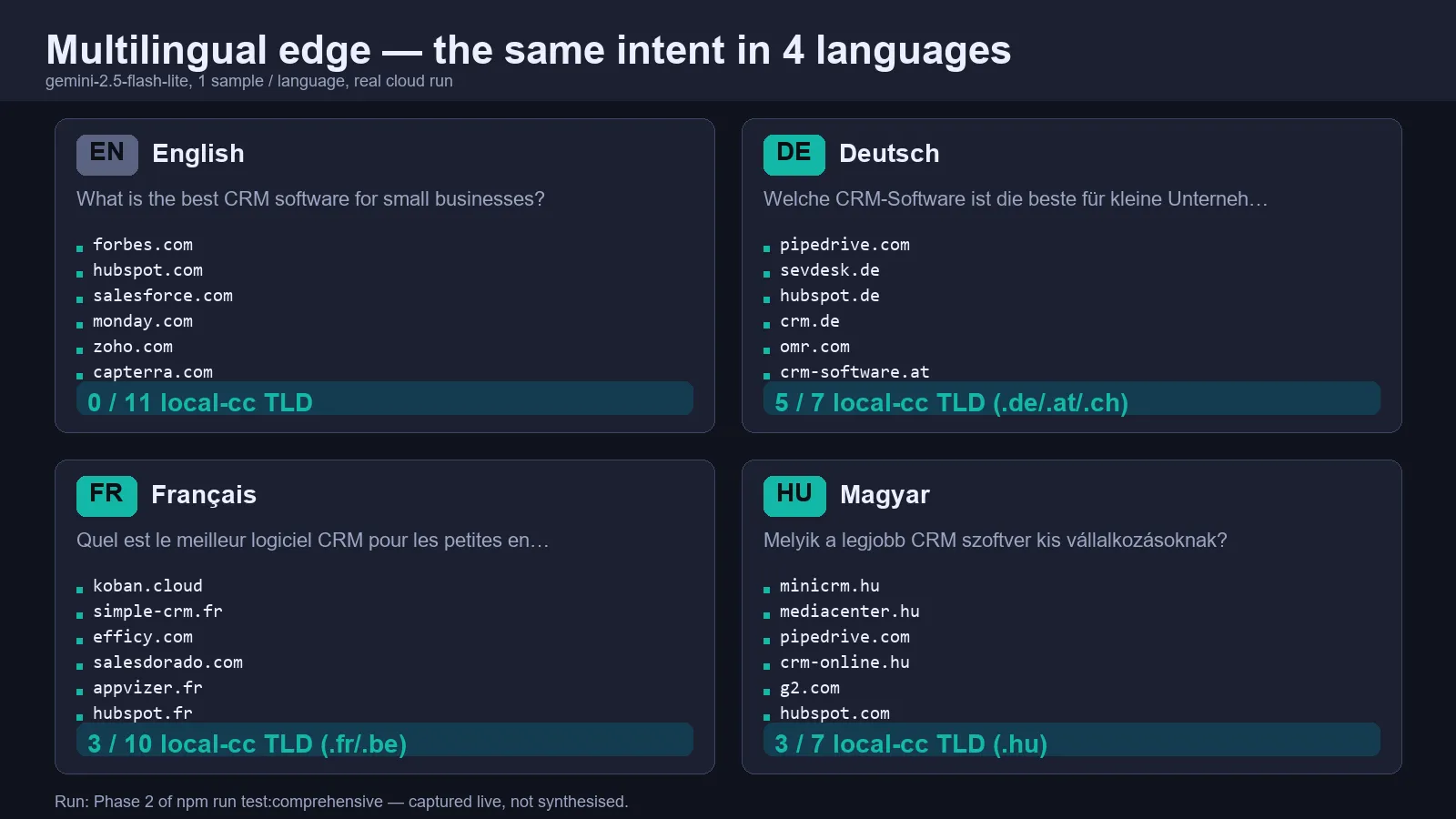
- 24 languages — Hungarian, German, French, Spanish, Italian, Polish, Czech, Romanian, Turkish, Japanese, Korean, Russian, Ukrainian, and 11 more.
- BYOK transparency — your OpenAI / Perplexity / Anthropic keys, your bills, your data. The actor never proxies your traffic through our account.
What it does
Given a list of queries (e.g. "best CRM for small business", "top fogorvosok Budapesten") and one or more domains you care about, the actor:
- Fans out each query to every selected engine — Gemini, ChatGPT (gpt-4o-mini-search-preview), Perplexity Sonar, Anthropic Claude with web_search.
- Captures the answer text plus structured citations (URL + title + snippet).
- Detects whether each tracked domain appears — via citation OR via brand mention in the answer text.
- Computes citation share-of-voice across your domains and competitor domains.
- Optionally runs each query N times and reports a stability score (how consistently each source is cited — useful for filtering one-shot hallucinations).
- Optionally diffs against a previous run and surfaces gained/lost citations per query (delta mode).
Quick start ($0/month)
- Get a free Gemini key: https://aistudio.google.com/apikey (Google account, no credit card).
- Run the actor with this minimal input:
That's it. Free tier covers 250 queries/day on Gemini 2.5 Flash, ~1000 queries/day on Gemini 2.5 Flash-Lite — enough to track ~250-1000 prompts daily for $0.
Comparison vs Otterly / Profound / Peec / Semrush
| Feature | This actor | Otterly | Profound | Peec AI | Semrush AI | Ahrefs Brand Radar |
|---|---|---|---|---|---|---|
| Entry price | $0/mo (free Gemini tier) | $29/mo | $99/mo | €89/mo | $99/mo | $328/mo |
| Pay-per-query option | ✅ $0.02/query | ❌ | ❌ | ❌ | ❌ | ❌ |
| Bring-your-own-key | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| 24-language support | ✅ | ⚠️ EN-default | ⚠️ EN-default | ⚠️ partial | ❌ US-EN only | ⚠️ EN-default |
| Local-CC TLD source surfacing | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| Stability score across N samples | ✅ | ⚠️ | ✅ | ❌ | ❌ | ❌ |
| Week-over-week delta diff | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Free trial / no monthly minimum | ✅ | ⚠️ 15 prompts max | ❌ no free trial | ⚠️ | ⚠️ | ❌ |
| CSV export | ✅ via Apify | ✅ | ✅ | ✅ | ✅ | ✅ |
| Apify integration / programmatic API | ✅ native | ❌ | ❌ | ❌ | ❌ | ❌ |
| Open architecture (you see the prompts) | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
Bottom line: if you're an indie SEO, an agency running multi-country campaigns, or a B2B SaaS marketer in a non-English market, the wedge here is real. If you need an enterprise UI with 50 stakeholder seats, look at Profound.
Engine support — Gemini, ChatGPT, Perplexity, Claude

| Engine | Where to get a key | Approx cost / query | Free tier |
|---|---|---|---|
| Google Gemini | https://aistudio.google.com/apikey | $0 free / $0.005 paid | ✅ 250–1000/day |
| OpenAI / ChatGPT | https://platform.openai.com/api-keys | ~$0.025 | ❌ |
| Perplexity Sonar | https://www.perplexity.ai/settings/api | ~$0.005–0.015 | ❌ |
| Anthropic Claude | https://console.anthropic.com/ | ~$0.01–0.02 | ❌ |
A single query across all four engines costs you ~$0.05–0.08 in third-party API fees. You pay them directly. The actor itself charges $0.02 per citation record on the Apify Store (free until 2026-05-14, then PAY_PER_EVENT).
Output schema
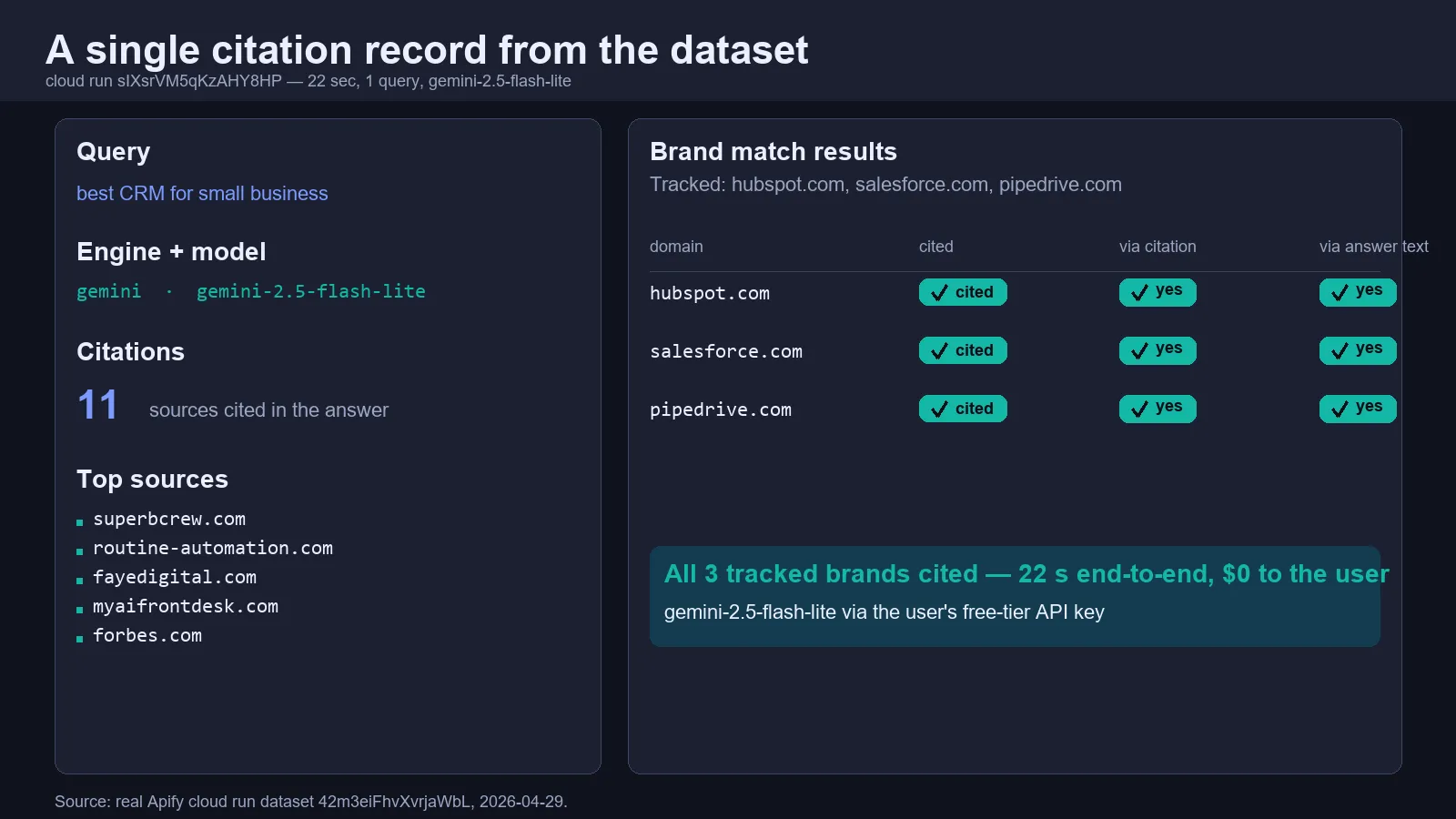
Each engine call writes one record to the dataset:
The actor also writes one stability record per (query, engine) when samplesPerQuery > 1, one delta record when previousRunDatasetId is set, and a final summary record closing every run.
Stability score — filter out hallucinations
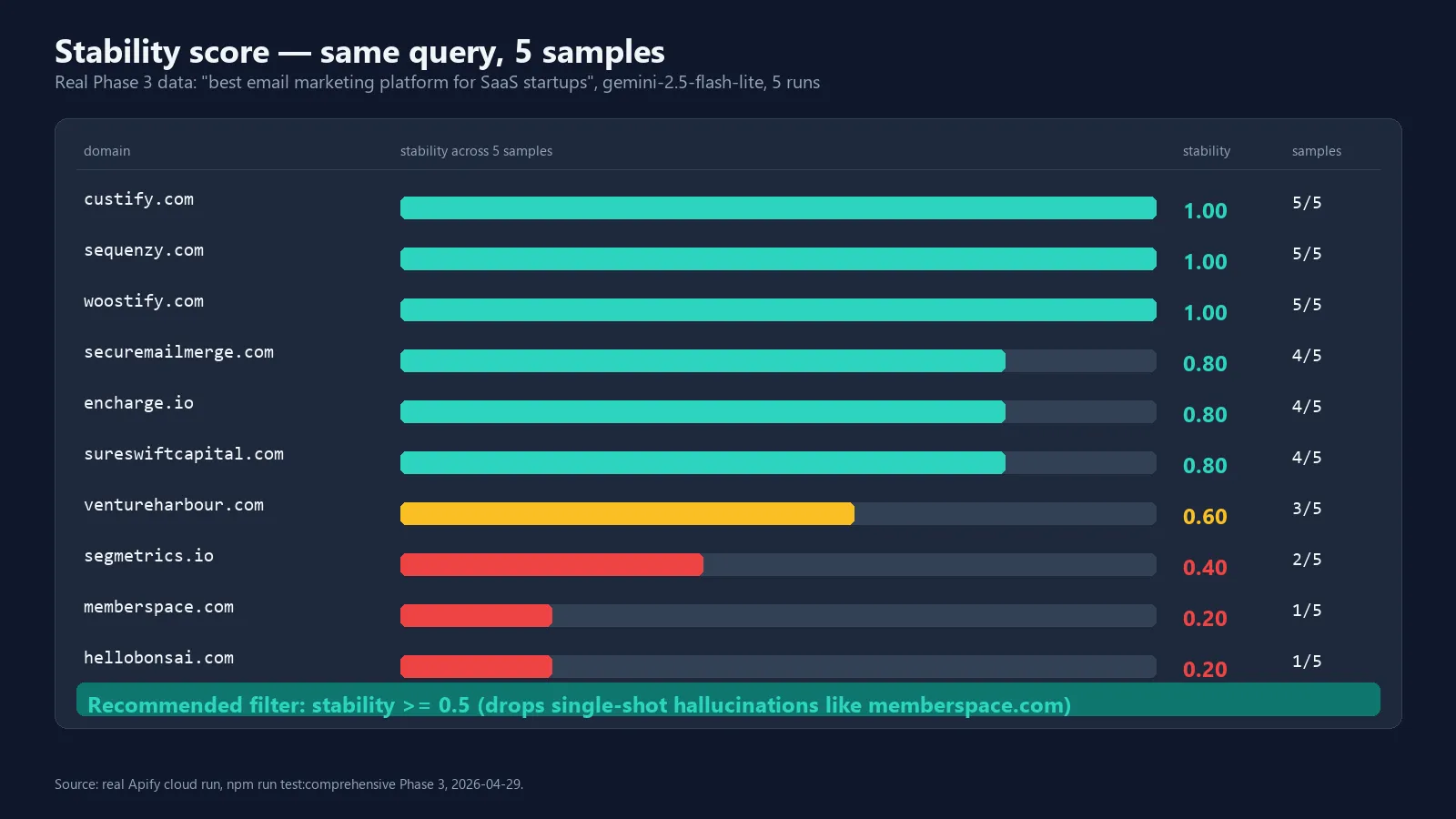
AI answers are not deterministic. Run the same query twice and you'll often get a different set of citations — Gemini and ChatGPT both vary 60–87% per run depending on the model.
The stability score solves this. Set samplesPerQuery: 3 (or 5 for high-confidence work) and the actor:
- Runs the query N times against each engine.
- Counts how many of the N samples cite each domain.
- Reports a
stabilityvalue: 1.0 = cited every time, 0.5 = half the time, 0.2 = one-shot.
Recommended filter: ignore citations with stability < 0.5. These are likely hallucinations rather than real AI rankings. The actor never auto-filters — it surfaces the score so you decide.
Delta mode — week-over-week diff

The delta mode makes monitoring meaningful. Two runs alone tell you a snapshot — what matters is what changed.
Pass the previous week's dataset ID as previousRunDatasetId in the input, and the actor writes a delta record:
A single run with delta mode gives you both today's snapshot AND the diff vs last week — perfect for weekly Slack alerts ("salesforce.com dropped out of 'best CRM' citations this week").
Recipes
Daily monitoring with weekly diff
Schedule the actor daily via Apify schedules. Pass last week's defaultDatasetId as previousRunDatasetId to get a weekly diff alongside today's snapshot.
Multilingual brand share-of-voice
Set language: "hu" (or de, fr, …) and Gemini will reply in that language and prefer same-language sources. Especially useful for European B2B SaaS, agencies running multi-country pipelines, or local SEO consultants.
Stability filter for hallucinations
Set samplesPerQuery: 3 and ignore citations whose stability < 0.5 — these are likely one-shot hallucinations rather than reliable AI rankings.
Multi-engine consensus tracking
To find sources cited consistently across all 4 engines (the strongest signal), select all 4 engines and look for citations that appear in every engine's record:
Use cases by persona
SEO agency lead (10–50-person shop)
You manage GEO for 5–30 client brands. Otterly's $189/mo plan caps you at 100 prompts (~3 prompts per client). Profound and Peec scale linearly with cost.
With this actor: pay-per-query at $0.02 with white-label CSV export. 30 clients × 50 prompts/month = 1,500 queries × $0.02 = $30/month total. Charge each client $50–100 for the report — that's $1,500–3,000/month margin.
In-house SEO at B2B SaaS
Your CMO asks weekly: "Are we showing up in ChatGPT?" You don't need a $499/mo dashboard — you need a daily snapshot dropped into Slack.
With this actor: schedule the actor daily, parse the delta record, fire a Slack webhook on lost citations. Total tooling cost: $30–60/month for 50 prompts × 30 days × $0.02 (3 samples for stability).
PR / Comms team
Crisis-monitoring AI search results — "are negative articles getting cited when people ask about us?"
With this actor: run nightly with a sentiment-pass downstream (any LLM you wire up). Pay-per-query is perfect for the bursty workload.
Indie SEO / consultant
You charge clients $300–600/month for SEO consulting. GEO is the new add-on. Otterly Lite is $29 for 15 prompts — barely enough for one client.
With this actor: $0 entry, $0.02/prompt above the Gemini free tier. One Gemini key handles 5 clients comfortably; mark up the cost 10× and you've added $150/client/month with no tool overhead.
Hungarian / German / French / Polish B2B brand
The Otterly/Profound/Peec stack treats your market as an afterthought. Same prompt in your language surfaces a completely different set of sources — and that's the rendering your prospects see.
With this actor: run all your queries in your language, surface .hu/.de/.fr/.pl sources, build a positioning brief that matches your local prospect's actual search experience.
Pricing
The actor uses PAY_PER_EVENT pricing on the Apify Store:
| Event | Charge | Description |
|---|---|---|
apify-actor-start | $0.0001 | Per run start. Tiny platform overhead. |
citation-record | $0.02 | Per citation record delivered (one engine × one query × one sample). |
error / stability / delta / summary | $0 | Not billed. |
Pricing activates 2026-05-14. Until then, the actor runs free under Apify's "Free" billing model — the user only pays Apify's standard compute/proxy fees on their own subscription, and the actor itself is $0.
Your true cost per query depends on which engines you select:
- Gemini-only, free tier → $0 LLM + $0.02 actor = $0.02/query (or $0 if pricing hasn't activated yet)
- Gemini-only, paid tier → $0.005 LLM + $0.02 actor = ~$0.025/query
- All 4 engines paid → $0.05–0.08 LLM + $0.02–0.08 actor (one citation record per engine) = $0.10–0.16/query
For comparison, Otterly's effective per-prompt rate is $1.93 (= $29/15 prompts on the Lite plan). This actor is 95–99% cheaper.
FAQ
Q: Do I have to use Gemini? Can I run only on ChatGPT?
A: Yes. You can supply only the OpenAI key and select engines: ["openai"]. The actor will skip Gemini gracefully. Same for any engine combo — if a key is missing, the engine is skipped with a warning.
Q: Is my API key safe?
A: Yes. The Apify input-schema marks all key fields as isSecret: true. They're encrypted at rest and never logged. You can also store the key in your Apify account's secret store and reference it via {{secrets.geminiApiKey}} in the input.
Q: How is this different from running ChatGPT manually? A: Three things: (1) automated scheduled runs with diff alerts; (2) consistent multi-engine + multilingual coverage; (3) structured dataset output you can pipe into your BI / CRM / SEO dashboard.
Q: Why doesn't it scrape ChatGPT.com directly?
A: Two reasons. First, OpenAI's ToS forbids automated extraction. Second, the official Responses API with the web_search_preview tool returns the same answer quality plus structured citations — and is BYOK-compliant.
Q: Why no Google AI Overviews in v0.1?
A: Google AIO scraping is its own can of worms (DMCA litigation against SerpApi, SearchGuard anti-bot, fragile DOM). Gemini grounding is functionally equivalent (same Google search index, same LLM brain) for citation tracking. v0.2 will add literal AIO via Apify's apify/google-search-scraper actor when stable.
Q: How do I track citations from Bing Chat / Copilot / Grok?
A: Not in v0.1. The architecture supports adding engines (one file under src/engines/); roadmap items.
Q: Will this work for Hungarian / Polish / Turkish keywords?
A: Yes. Set language: "hu" (or pl, tr, …). Gemini, ChatGPT, Perplexity all handle these languages natively. The citation-parser is language-agnostic — it works on URLs and domains, not text.
Q: What if a query returns no citations?
A: The record is still written with citationCount: 0 and citations: []. The brand-matching logic also checks the answer text for the brand name, so you'll still see viaText: true/false even when no URLs are returned.
Q: How do I export to CSV?
A: From the Apify dataset UI: open the run → Storage → Export → CSV. Or via API: https://api.apify.com/v2/datasets/<id>/items?format=csv.
Q: Can I run this on a schedule? A: Yes. Apify schedules are free up to 100 schedules per account. Set up a daily/weekly cron in the Apify Console.
Q: Why is the GEO/AEO market so crowded if multilingual is unsolved? A: Most enterprise tooling vendors are based in the US — their default assumption is English-default. The European market is small enough that the dominant US players don't prioritize it, but big enough that an indie tool can carve a niche. That's the wedge.
Q: Will the actor still work after Gemini changes its model names?
A: Yes. The default model is configurable via geminiModel input. If gemini-2.5-flash is renamed, you set geminiModel: "gemini-3-flash" (or whatever) without a code change. Same for OpenAI / Perplexity / Anthropic models.
Q: Does it support paid Gemini tiers (gemini-2.5-pro, gemini-3-flash-preview)?
A: Yes. Set geminiModel: "gemini-2.5-pro" or any model accessible to your key. The free Gemini tier covers gemini-2.5-flash and gemini-2.5-flash-lite only — paid models require billing enabled on your Google AI Studio account.
Q: Why does my run cost $0 right now? A: Pricing activates 2026-05-14 (Apify-mandated 14-day notice on price changes). Until then, every run is free for both you and the actor owner.
Troubleshooting
Problem: All citations return google.com host.
Cause: Old build. Gemini's grounding API returns redirect URLs that look like vertexaisearch.cloud.google.com/grounding-api-redirect/.... v0.1.1+ extracts the real source from the web.title field. Make sure you're running the latest build.
Problem: "Quota exceeded for metric: generativelanguage.googleapis.com/generate_content_free_tier_requests"
Cause: You're hitting Gemini's free-tier daily limit (250 RPD on gemini-2.5-flash, ~1000 RPD on gemini-2.5-flash-lite). Solutions: (a) wait 24 hours for reset, (b) switch to geminiModel: "gemini-2.5-flash-lite" for higher quota, (c) enable billing on your Google AI Studio account, (d) supply an OpenAI/Perplexity/Anthropic key as fallback.
Problem: Citations vary on every run.
Cause: AI answers are non-deterministic. This is expected. Solution: set samplesPerQuery: 3 (or 5) and use the stability score to filter out one-shot citations.
Problem: "Engine 'X' selected but no API key supplied — skipping."
Cause: You selected an engine in engines but didn't provide its API key. Add the key, or remove the engine from the selection.
Problem: "Invalid value provided in updatedActor: description must be at most 300 characters long." Not a runtime issue — this is an Apify Store metadata constraint. Doesn't affect actor execution.
Problem: Run succeeds but the dataset is empty.
Cause: All engine calls failed silently (likely all keys missing or invalid). Check the run log — error records should still be in the dataset, and the summary record's stats.failed field tells you the error count.
Problem: 503 errors on Gemini. Cause: Vendor-side overload. This is transient. The actor doesn't auto-retry on 503 in v0.1 — re-run the same input after a few minutes.
Problem: Apify Store page shows old README / icon. Cause: Apify Store CDN cache — typically 10–30 minutes after a build. Hard-refresh the public page or wait.
Local development
scripts/test-utils.js validates the citation parser, brand-detector, share-of-voice math, stability computation and delta diff with hand-crafted fixtures — runs in under 100ms with no network.
scripts/smoke.js calls each engine for which a key is set and prints a compact citation report. Useful for verifying the adapters still work after API surface changes.
scripts/test-comprehensive.js is a 6-phase live integration runner that verifies all engine adapters with billing-aware error handling. Used to certify each release.
Architecture
The four engine adapters share the same return shape so main.js doesn't care which engine produced a record. Adding a new engine = one file under src/engines/ plus one entry in engineAdapters in main.js.
Limitations / honest disclosure
- AI answers are non-deterministic. A single sample of a single query can miss citations that appear most of the time — that's why we expose
samplesPerQueryand a stability score. Don't make business decisions on asamplesPerQuery: 1snapshot; use 3+ for monitoring you trust. - Free Gemini tier has rate limits. 10 RPM, 250 RPD on
gemini-2.5-flash; ~15-20 RPM, ~1000 RPD ongemini-2.5-flash-lite. Anything beyond that requires paid Gemini API tier or fallback to other engines. - Google AI Overviews are not yet covered in v0.1. Gemini grounded answers are a strong proxy (same underlying LLM and search index) but the literal SERP AIO block is a separate feature. v0.2 will add it via Apify's
apify/google-search-scraperactor. - Engines may shift their APIs. OpenAI's
web_search_previewand Anthropic'sweb_search_20250305are explicitly versioned tools. We pin sensible defaults; if a vendor breaks compatibility, the relevant adapter file is the only file that needs to change. - Only
gemini-2.5-flashandgemini-2.5-flash-liteare truly free despite Gemini's API listing 38 models. The rest require billing enabled on your Google account — the adapter dispatches the request correctly but the vendor returns 429. - No SEO ranking guarantees. This actor measures what AI engines cite — not what to do about it. If the data shows you don't appear, the next steps (improve content, build links, target citation-friendly keywords) are still SEO 101.
Roadmap
- v0.2 — Google AI Overview capture via the existing
apify/google-search-scraperactor (chained, BYOK Apify proxy). - v0.3 — Slack / Discord / webhook alerting on citation gains/losses (delta mode hooks).
- v0.4 — White-label CSV export with agency branding and per-client dashboards.
- v0.5 — Public weekly leaderboards (e.g. "Top 50 brands cited in ChatGPT for project management software, EN/DE/HU") generated from aggregated runs of consenting users — distribution / SEO play.
- v0.6 — Sentiment classification on the answer text (positive / neutral / negative mentions).
- v0.7 — Microsoft Copilot, You.com, Grok engine adapters.
License
ISC. Use it, fork it, ship it. Pull requests welcome — see https://github.com/highbrow_fame/ai-search-visibility-tracker if you'd like to contribute (TODO: open-source the repo).