Metadata Extractor
Pricing
Pay per usage
Go to Store


Metadata Extractor

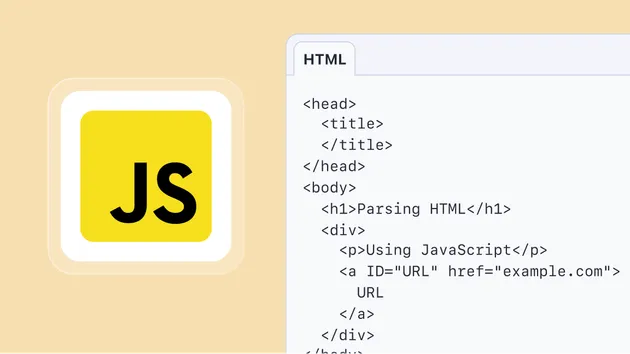
A small efficient actor that loads a web page, parses its HTML using Cheerio library and extracts the following meta-data from the <HEAD> tag, such as page title, description, author etc.
0.0 (0)
Pricing
Pay per usage
15
Total users
1.3K
Monthly users
33
Runs succeeded
88%
Last modified
2 years ago
get the count of words from url webbpage
Closed
Hi there,
I am looking for a scraper to scrape basic information from articles (from URLs). This one seems pretty good :) I just need another function. Is it possible to get a count of all the words in the article or on the webpage?
All the best Fabian
3 years ago
You can easily make a copy of the actor and add this function yourself.