douban
Pricing
Pay per usage
Go to Apify Store
douban
This actor can crawl data from douban. It can get data of top 10 book from [豆瓣读书](https://book.douban.com/). For more powerful actor, please check https://apify.com/kuaima/douban-book-pro
Apify Actor for douban free
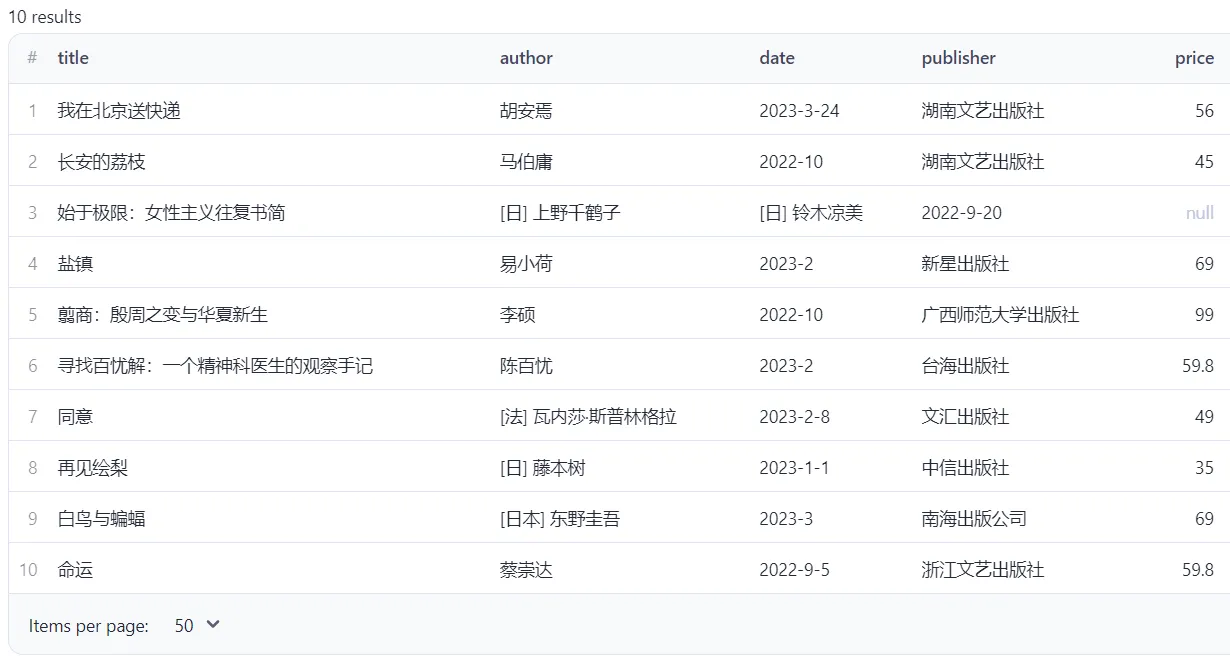
This actor can crawl data from douban. It can get data from 豆瓣读书 like this

And get data like this