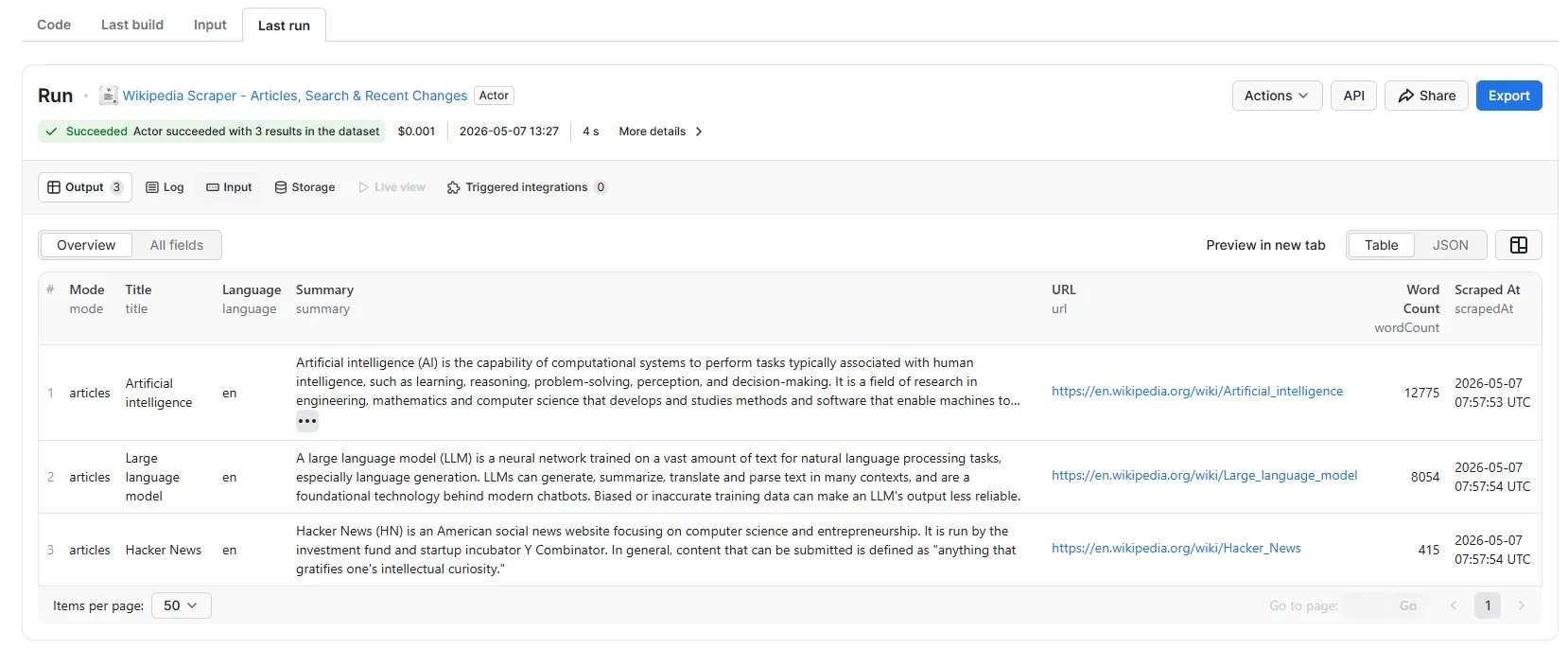
Wikipedia Scraper - Articles, Search & Recent Changes
Pricing
from $0.10 / 1,000 results
Wikipedia Scraper - Articles, Search & Recent Changes
Scrape Wikipedia articles by title, run keyword searches, pull recent changes, or extract entire categories — across any of 300+ language editions. Returns clean text, summaries, references, links, and metadata. Built for AI/LLM training datasets, NLP research, and knowledge-graph building.
Pricing
from $0.10 / 1,000 results
Rating
0.0
(0)
Developer
NIJ KANANI
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
0
Monthly active users
3 months ago
Last modified
Categories
Share
📚 Wikipedia Scraper
Scrape Wikipedia articles, search results, recent edits, and categories — across all 300+ language editions. Returns clean plain-text content, summaries, references, and rich metadata.
🎯 Built for AI/LLM training datasets, NLP research, knowledge-graph construction, journalism, and education.
✨ What you can do
- 📄 Fetch articles by title — clean plain-text body, summary, sections, references
- 🔎 Search — full-text search across an entire language edition
- 📡 Recent changes — live feed of edits (title, user, comment, revid)
- 📁 Pull entire categories — all members of
Category:Machine_learning, etc. - 🌐 Any language —
en,es,fr,de,ja,zh,hi,ar, etc. - 📦 Rich output: links (internal+external), categories, sections, last-modified
🚀 Quick start
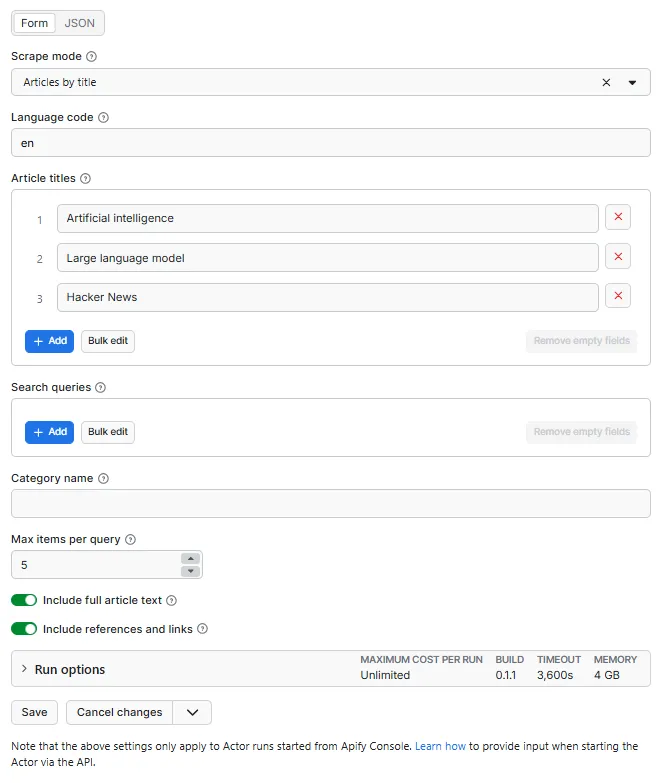
📥 Input
| Field | Used in mode | Description |
|---|---|---|
mode | all | articles / search / recentchanges / category |
language | all | Wiki edition code (en, de, ja...) |
titles | articles | Article titles |
searchQueries | search | Keywords or phrases |
category | category | Category name without Category: prefix |
maxItems | all | Cap per query |
includeContent | articles, search, category | Full plain-text body |
includeReferences | articles, search, category | External + internal links + sections |
📤 Output (per item)
🎯 Use cases
| Who | Why |
|---|---|
| 🤖 LLM teams | Pretraining + fine-tuning datasets across languages |
| 📚 NLP researchers | Multilingual corpora, named-entity benchmarks |
| 📰 Journalists | Topic deep-dives + fact-checking pipelines |
| 🎓 Educators | Auto-build study material from any topic |
| 🧠 Knowledge graphs | Wikipedia as an entity backbone |
⚙️ Tech notes
- Uses MediaWiki's official Action API + REST Summary API
- No login, no key, no rate limits (within fair use)
- Plain-text extraction via
explaintext=1— already cleaned, no HTML/wikitext - Recent-changes uses
rctype=edit|newto skip log noise
❓ FAQ
Are full Wikipedia dumps better? For one-shot pre-training, yes (free at dumps.wikimedia.org). This Actor is for targeted scrapes — specific topics, ongoing freshness, multi-language slices, or recent-changes monitoring.
Schedule it? Yes. Recent changes mode is perfect for hourly Apify Schedules.
Hits rate limits? Almost never. MediaWiki's anonymous limit is generous and we add automatic retries with backoff.