LinkedIn Ads Scraper No Cookies
Pricing
from $5.00 / 1,000 results
LinkedIn Ads Scraper No Cookies
The LinkedIn Ads Scraper extracts ads from the public LinkedIn Ad Library at scale, no login or cookies required. Search by keyword or advertiser, you get data for every matching ad: creative variants, images, the advertiser and paying entity, run dates, estimated impressions and audience targeting.
Pricing
from $5.00 / 1,000 results
Rating
5.0
(1)
Developer
Goldmine
Maintained by CommunityActor stats
0
Bookmarked
4
Total users
1
Monthly active users
a month ago
Last modified
Share
LinkedIn Ads Scraper
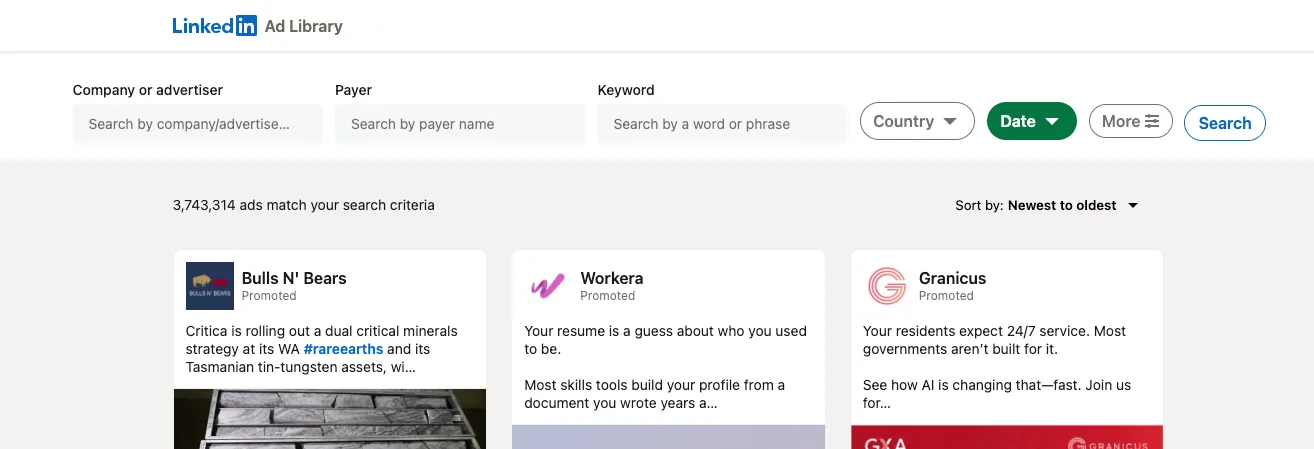
The LinkedIn Ads Scraper extracts ads from the LinkedIn Ad Library at scale. Search by keyword or advertiser and collect structured data for every matching ad: ad copy, creative variants, images, the advertiser and paying entity, run dates, estimated impressions and audience targeting. It is perfect for competitor research, ad creative inspiration, market analysis, brand monitoring and lead generation.
Features
- Search by Keyword or Advertiser: Find ads by a search term (e.g.
marketing) or by an advertiser / company name (e.g.Zalando). - Full Ad Details: Capture the complete ad copy, every creative variant, the advertiser, the paying entity, run dates, estimated impressions and targeting.
- Transparency Data: For regulated (e.g. EU) ads, collect total impressions, per-country impression breakdowns and the top targeting parameters selected by the advertiser.
- Creative Variants: Capture each variant of an ad with its body text, headline, call-to-action and image.
- Flexible Input: Provide ready-made LinkedIn Ad Library URLs or simply set a keyword / advertiser name and filters.
- Reliable at Scale: Collect large volumes of ads with built-in proxy support and rate control.
Inputs
| Field | Type | Description | Default |
|---|---|---|---|
startUrls | Array | LinkedIn Ad Library search URLs (e.g. https://www.linkedin.com/ad-library/search?keyword=nike). | Optional |
keyword | String | Keyword to search ads for (e.g. marketing). | Optional |
advertiserName | String | Advertiser / company name to search ads for (e.g. Zalando). | Optional |
countries | Array | ISO country codes to filter ads by audience country (e.g. US, GB, DE). | Optional |
dateOption | Select | Last 30 days, current month, last year or current year. | last-30-days |
scrapeAdDetails | Boolean | Collect full data for each ad (variants, dates, impressions, targeting). | true |
maxItems | Integer | Maximum number of ads to scrape per search. | 5 |
proxyConfiguration | Object | Proxy settings to scrape reliably. | Residential |
Provide either
startUrlsor akeyword/advertiserName.
Outputs
The scraper returns a dataset where each item is a single ad:
- Advertiser: Name, profile URL, logo and the paying entity.
- Creative: Ad format, headline, body text, image and every creative variant.
- Availability: The duration the ad ran, with parsed start and end dates.
- Performance: Estimated total impressions and a per-country impression breakdown (where available).
- Targeting: The top targeting parameters selected by the advertiser (where available).
- Context: The ad's Ad Library URL and the originating search URL.
Example Output:
How to Use
- Enter a keyword or advertiser name (or paste Ad Library search URLs).
- Choose your filters and how many ads to collect.
- Run the Actor and export the results as JSON, CSV or Excel.
Frequently Asked Questions (FAQ)
What is the LinkedIn Ad Library?
It is LinkedIn's public, free database of ads that have run on the platform. The LinkedIn Ads Scraper turns it into structured data you can export and analyze in bulk.
Do I need a LinkedIn account or login?
No. The scraper collects ads that are publicly available — no account, password or session is required.
How do I scrape all ads from a specific company?
Set the advertiserName input to the company's name (e.g. Zalando), or paste an Ad Library URL that targets that advertiser into startUrls.
How do I search ads by keyword?
Set the keyword input (e.g. marketing), or paste a keyword Ad Library URL into startUrls.
Why are some fields like impressions, run dates or targeting empty?
LinkedIn only publishes total impressions, per-country breakdowns and targeting for regulated ads (for example ads served in the EU). For other ads these fields are simply not available from the source, so they are returned as null or empty arrays.
Why are impressions returned as ranges instead of exact numbers?
LinkedIn publishes impressions as buckets (e.g. 5k-10k) rather than exact counts, so the scraper returns the range exactly as shown.
Does maxItems apply per search or globally?
Per search. If you pass three searches with maxItems: 50, you can collect up to 150 ads in total.
Can I filter by country or date range?
Yes. Use the countries input (ISO codes such as US, GB, DE) and the dateOption input (last 30 days, current month, last year or current year).
Do I need a proxy?
A proxy is recommended for reliable, larger runs. Residential proxies are enabled by default so collection stays reliable at scale.
In what formats can I export the data?
Results can be exported as JSON, CSV, Excel, or accessed via the Apify API.
Other Related Scrapers
Other related scrapers from goldmine:
Image Credit
Image credit: linkedin.com