G2 Reviews + AI Intelligence [$1.5💰] w/ EMAILS
Pricing
from $1.50 / 1,000 results
G2 Reviews + AI Intelligence [$1.5💰] w/ EMAILS
[💰$1.50/1K] G2 reviews, products & vendor data — plus an AI intelligence layer: one pass per product clusters its reviews into ranked pain points, missing features & quick wins ($0.05/product). Emails, pricing, competitor lists. Any G2 URL. Pure HTTP, no browser. Built for SaaS intel.
Pricing
from $1.50 / 1,000 results
Rating
5.0
(5)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
1
Bookmarked
159
Total users
70
Monthly active users
21 hours
Issues response
4 hours ago
Last modified
Categories
Share
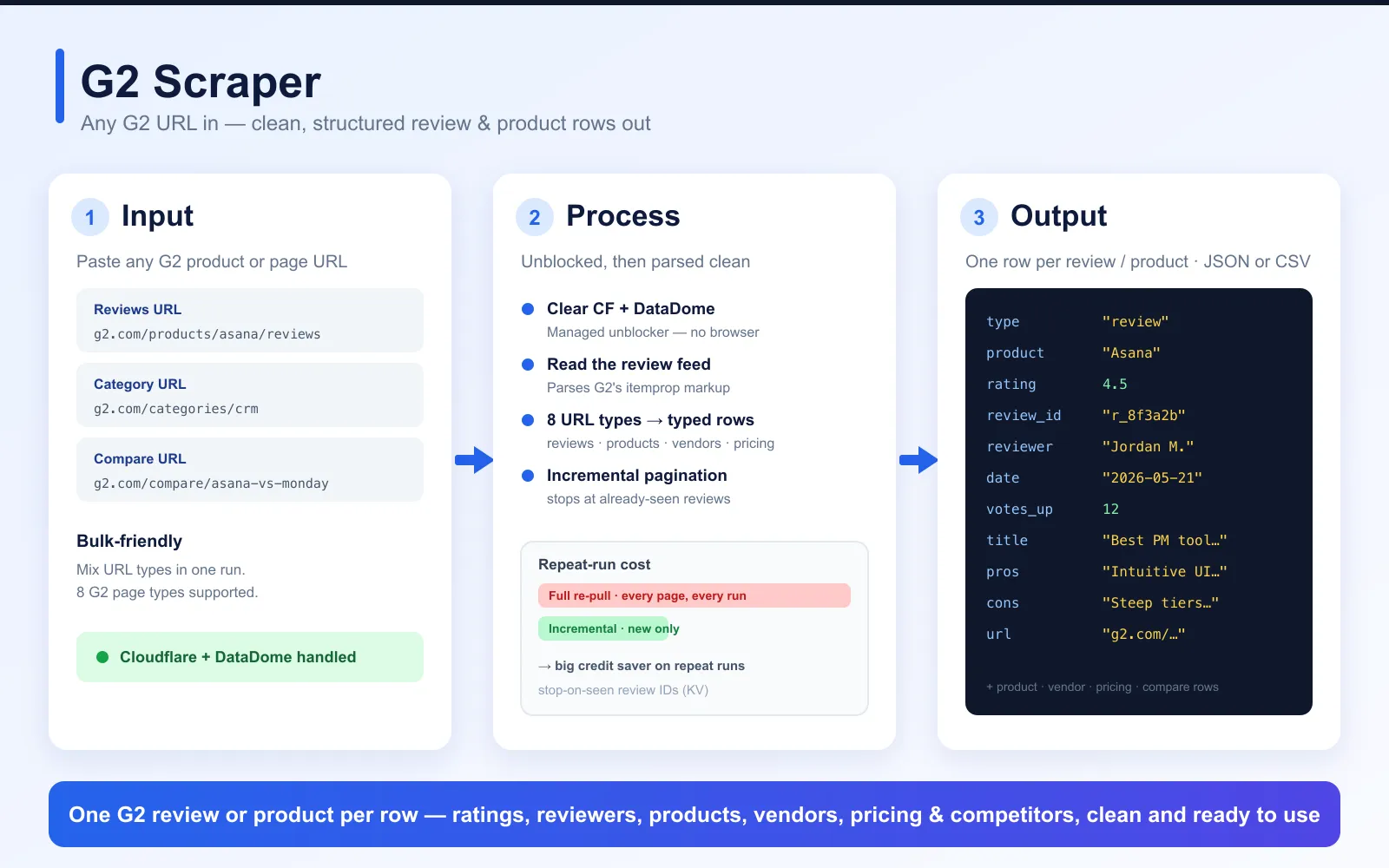
G2.com Software Scraper
How it works
Unlock the Full Power of G2.com Data — The only scraper you need to track, analyze, and understand the software landscape on G2.com with enterprise-grade reliability and precision. Whether you're benchmarking competitors, building a vendor shortlist, or monitoring user sentiment, our scraper turns G2's catalog into a structured dataset you can act on.
"From product listings to verified user reviews, we turn G2.com's data into your competitive advantage."
🧠 NEW: AI Pain-Point Analysis — reviews → product intel
Flip on painPointAnalysis and the scraper doesn't just return reviews — it tells you what to fix and build next. After scraping, one AI pass per product clusters every complaint into ranked themes and surfaces the features users keep asking for:
Postman, real run → Performance degradation & increasing bloat (severity 4, 30% of reviews) · Steep learning curve for advanced features (30%) · UI/UX complexity & feature bloat (20%) · missing: lightweight mode, performance optimization.
One painPointAnalysis row per product, straight from real G2 reviews — no prompts, no second tool. Paid plans only, billed per product analyzed.
Overview
The G2.com Software Scraper is your one-stop tool for extracting product, vendor, and review data from G2.com. Ideal for product managers, market analysts, sales teams, and researchers, it captures product metadata, ratings, review counts, vendor profiles, pricing indicators, category memberships, and full user reviews across thousands of software products. With easy setup and multiple export formats (JSON, CSV), it's perfect for anyone needing comprehensive G2 data at scale.
What does the G2 Software Scraper do?
The scraper supports five different G2 URL patterns out of the box and emits row-types you can split on:
Comprehensive Data Collection
- Search Results — extract product cards from G2 keyword searches
- Product name, vendor, rating, review count, categories, sponsorship status, thumbnail
- Product Reviews — paginate through a product's full review feed
- Reviewer profile, rating, publish date, written content, structured Q&A pairs
- Category Listings — paginate through
/categories/{slug}rankings- Same product card data as search PLUS position rank, entry-level price, list type
- Competitor Lists — extract a product's "Top 10 Alternatives & Competitors" page
- Ranked alternatives with name, vendor, rating, review count, description, pricing
- Product Detail Pages — extract a single product's full profile
- Full marketing description, aggregate rating, pricing tiers, vendor info, screenshot URLs, features text
Advanced Scraping Capabilities
- Search Scraping: Process G2 keyword searches and extract all matching products with full pagination
- Reviews Scraping: Hit a product's review URL → get every review with author + Q&A structure
- Category Scraping: Walk an entire G2 category (or subcategory) and extract its ranked product list
- Competitor Scraping: Hit
/products/{slug}/competitors→ get G2's curated Top 10 alternatives - Product Detail Scraping: Hit
/products/{slug}→ one row per product with full description, pricing tiers, images, and aggregate rating - Smart Anti-Bot Handling: Three TLS-impersonating clients race in parallel (impers, impit, got-scraping). Browser-quality session pool keeps Datadome/Cloudflare cookies fresh.
- Smart Pagination: Follows G2's "Next" links automatically and stops cleanly on the last page
- Humanlike Pacing: 8-15s jittered delays between page fetches to stay under rate limits
Flexible Scraping Options
- Search URLs:
https://www.g2.com/search?query=crm - Product Reviews URLs:
https://www.g2.com/products/postman/reviews - Category URLs:
https://www.g2.com/categories/crm(also subcategories like/categories/crm/sales-acceleration) - Competitors URLs:
https://www.g2.com/products/postman/competitors(also accepts/competitors/alternatives) - Product Detail URLs:
https://www.g2.com/products/postman(the bare product page — one row of rich metadata per product)
This tool is ideal for:
- Competitive intelligence and vendor shortlisting
- Market research across entire G2 categories
- Customer-voice analysis from verified reviews
- Lead generation by category or search keyword
- Sentiment monitoring over time on specific products
Features
- Five URL Types Supported: Search, individual product reviews, category listings, competitor lists, and product detail pages — each with its own optimized parser
- Full Anti-Bot Resilience:
- Browser-warmed session pool with rotating Datadome cookies
- Three independent TLS-impersonating HTTP clients raced in parallel
- Automatic session rotation, per-session usage tracking
- Falls back to legacy DataDome-cookie service if pool is empty
- Comprehensive Data Extraction: Detailed product metadata, ratings, full reviews, vendor profiles, category memberships, pricing
- Flexible Input: Mix all three URL types in a single run
- Automatic Pagination: Walks multi-page results until your
maxItemscap or the last page - Structured Output: One row per product or per review, discriminated by a
typefield for easy downstream filtering - Reliable Performance: Built-in retry mechanisms, exponential back-off, residential proxy support
Supported URL Types
The G2.com Software Scraper handles nine URL patterns. Mix them freely in a single startUrls array.
1. Search Result URLs
Extract products matching a keyword query, with automatic pagination.
- Example:
https://www.g2.com/search?query=databricks - Example:
https://www.g2.com/search?query=crm+software - Output row shape:
itemType: "Software"(notypefield — historical schema)
2. Product Reviews URLs
Extract every review for a specific product. Walks G2's reviews_and_filters Turbo Frame endpoint with pagination. Emits one type: "review_summary" row up front (AI summary + top Pros/Cons with mention counts) followed by type: "review" rows for each individual review.
- Example:
https://www.g2.com/products/postman/reviews - Example:
https://www.g2.com/products/azure-databricks/reviews - Alias-redirect resolution: input slug may be a G2 alias (e.g.
/products/salesforce/reviewsresolves to/products/salesforce-customer-success/reviews); the scraper transparently follows. - Filter passthrough: append G2's own filter query params and they're forwarded verbatim. Examples:
https://www.g2.com/products/postman/reviews?filters[ratings]=5— lead with 5-starhttps://www.g2.com/products/postman/reviews?filters[company_size][]=Enterprise&order=most_recent- Whitelisted families:
filters[*],order,state,lang_iso,time,tag_ids[],media_type
- Output row shapes:
type: "review_summary"(one per URL, skipped when filters are used) +type: "review"(one per review)
3. Category Listing URLs
Walk an entire G2 category page (and any subcategory under it), ranked by G2 score. Each product row now carries a situationalAwards array — G2 Grid®-style quadrant winners ("Leader", "Highest Performer", "Easiest to Use", "Top Trending", "Best Free Software") for that category, pulled from the page's analytics markup.
- Example:
https://www.g2.com/categories/crm - Example:
https://www.g2.com/categories/crm/sales-acceleration - Output row shape:
type: "category_product"(withsituationalAwards: [...])
4. Competitor Lists URLs
Pull G2's curated "Top N Alternatives & Competitors" for a specific product. Fixed-size list (no pagination).
- Example:
https://www.g2.com/products/postman/competitors - Example:
https://www.g2.com/products/salesforce-sales-cloud/competitors/alternatives(canonical form — both are accepted and normalized) - Output row shape:
type: "competitor"
5. Product Detail URLs
Extract the full profile for a single product — one row per product. Includes the full marketing description (not just a snippet), all pricing tiers, screenshot URLs, vendor profile, and aggregate rating.
- Example:
https://www.g2.com/products/postman - Example:
https://www.g2.com/products/salesforce-sales-cloud - Output row shape:
type: "product"
6. Vendor / Seller Profile URLs
Extract a vendor's company profile and their entire product portfolio (rating + review count per product). One row per vendor, with an embedded products array.
- Example:
https://www.g2.com/sellers/salesforce - Example:
https://www.g2.com/sellers/postman - Output row shape:
type: "vendor"
7. Pricing Tab URLs
Extract a product's structured pricing — per-tier prices (with currency), the G2-curated "Key Insights" summary paragraph, and the pricing FAQs (Q&A pairs).
- Example:
https://www.g2.com/products/postman/pricing - Example:
https://www.g2.com/products/slack/pricing - Output row shape:
type: "pricing"
8. Compare URLs
Head-to-head product comparison: pulls each product's metadata (name, vendor, aggregate rating, review count) plus the full per-criterion ratings table (Meets Requirements, Ease of Use, Ease of Setup, Ease of Admin, Quality of Support, etc.) with score + sample size for each side, and the list of alternatives G2 surfaces.
- Example:
https://www.g2.com/compare/postman-vs-mulesoft-anypoint-platform - Multi-way comparisons are also supported:
https://www.g2.com/compare/a-vs-b-vs-c - Output row shape:
type: "compare"
9. Single Review URLs
Fetch one specific review as a single type: "review" row — same shape as the bulk review rows, parsed from the page's schema.org microdata.
- Example:
https://www.g2.com/products/postman/reviews/postman-review-9104210 - Output row shape:
type: "review"(one row)
Input shortcuts
- Bare product slugs: skip URL building entirely — set
"productSlugs": ["postman", "hubspot-marketing-hub"](or paste a bare slug as a start URL) and each maps to that product's reviews page. - Regional domains:
fr.g2.com,de.g2.com, and any other regional G2 host are normalized towww.g2.comautomatically.
Paste any G2 URL — product, reviews, category, compare, vendor or search. The actor fetches it over plain HTTP (a managed unblocker clears Cloudflare + DataDome — no headless browser, no third-party CAPTCHA service), parses the page into typed rows (reviews, products, vendors, pricing, competitors, categories), and streams clean records to the dataset in JSON, CSV or Excel.
Quick Start
- Sign up for Apify: Create your free account at apify.com
- Find the Scraper: Search for "G2.com Software Scraper" in the Apify Store
- Configure Input: Provide one or more G2 URLs (any of the nine supported types — search, reviews, single review, categories, competitors, product detail, vendor profile, pricing tab, or head-to-head compare)
- Run the Scraper: Execute the scraper on the Apify platform
- Download Data: Export results in JSON, CSV, or Excel
Input Configuration
Here's an example mixing the URL types in one run:
Input Fields Explanation
startUrls(array, required): G2 URLs to scrape. Each entry is an object with aurlfield. You can mix search, reviews, and category URLs freely. Bare slugs and regional (fr.g2.com, …) URLs are accepted and normalized.productSlugs(array of strings, optional): shortcut — bare G2 product slugs (e.g."postman"), each expands to that product's reviews URL. Used in addition tostartUrls.sortOrder(string, optional): review ordering —g2_default|most_recent|most_helpful|highest_rated|lowest_rated. Combine with a lowmaxReviewsto grab e.g. "the 50 most recent reviews". A?order=param pasted in a URL wins for that URL.starFilterCondition+starFilterValue(optional): star filter for review rows.exactly/minimum/maximum+ a 1–5 value, e.g. minimum + 4 → only 4★ and 5★ reviews. (G2's star buckets include half-stars: the 4★ bucket spans 3.5–4.0.)lookbackDays(integer, optional): only reviews published in the last N days. Forces most-recent ordering and stops paginating at the cutoff — you pay only for pages inside the window.maxItems(integer, optional): Hard cap on total rows emitted across allstartUrls. Default100. Applies to product rows from search + category URLs, and (separately, whenmaxReviewsis not set) to review rows.maxReviews(integer, optional): Cap on review rows per product URL. Default falls back tomaxItemsif unset. Only applies to/products/.../reviewsURLs.maxConcurrency(integer, optional): Maximum concurrent page fetches. Default1. Keep low (1-3) for G2 because DataDome rate-limits aggressively per cookie.minConcurrency(integer, optional): Minimum concurrent page fetches. Default1.maxRequestRetries(integer, optional): Number of retries for failed requests. Default5.proxy(object, optional): Proxy configuration. Residential proxies strongly recommended for G2 — Datadome/Cloudflare flag datacenter IPs immediately.useApifyProxy: Use Apify's residential proxy service (recommended:true)apifyProxyGroups: Proxy groups (recommended:["RESIDENTIAL"])
slowMode(boolean, optional): Whentrue, adds extra warm-up delays and longer back-off between pages. Defaulttrue. Set tofalseonly if you've verified your proxy + IPs are clean.
Pricing
This actor uses the pay-per-event model:
| Event | Trigger | Price |
|---|---|---|
| Result | Every dataset row pushed (product or review) | $2.75 / 1000 |
| Review details | Each type: "review" row, on top of the Result charge | $1.50 / 1000 |
Effective per-row cost:
- Search / Category product row → $2.75 / 1000
- Review row → $4.25 / 1000 ($2.75 Result + $1.50 Review details)
For a run with 100 products from search + 50 reviews each (5,100 rows total): 100 × $0.00275 + 5,000 × $0.00425 ≈ $21.40.
Output Structure
The scraper writes nine row types to the dataset, distinguished by where the data came from:
| Source URL | Row marker | Description |
|---|---|---|
/search?query=... | itemType: "Software" | One row per product card in search results |
/products/{slug}/reviews | type: "review_summary" + type: "review" | One summary row (AI text + Pros/Cons) per URL, then one row per individual review |
/categories/{slug} | type: "category_product" | One row per product in a category listing (with situationalAwards: [...]) |
/products/{slug}/competitors | type: "competitor" | One row per competing product (Top N) |
/products/{slug} | type: "product" | One row per product detail page (full profile) |
/sellers/{slug} | type: "vendor" | One row per vendor with embedded products portfolio |
/products/{slug}/pricing | type: "pricing" | One row per product with pricing tiers + key insights + FAQs |
/compare/{a}-vs-{b} | type: "compare" | One row per comparison with per-criterion ratings |
You can split the dataset by these markers downstream, or use the join keys (productSlug, productUuid, vendorId) to merge across row types.
Sample Search Result Row
URL: https://www.g2.com/search?query=databricks
Sample Review Row
URL: https://www.g2.com/products/postman/reviews
Sample Product Detail Row
URL: https://www.g2.com/products/postman
Sample Competitor Row
URL: https://www.g2.com/products/postman/competitors
Sample Category Product Row
URL: https://www.g2.com/categories/crm
Sample Vendor Row
URL: https://www.g2.com/sellers/salesforce
Sample Review Summary Row
URL: https://www.g2.com/products/postman/reviews (emitted once, before individual review rows)
Sample Pricing Row
URL: https://www.g2.com/products/postman/pricing
Sample Compare Row
URL: https://www.g2.com/compare/postman-vs-mulesoft-anypoint-platform
Output Fields Detailed Explanation
Common Fields (all row types)
scrapedAt(string): ISO 8601 timestamp of when this row was extracted.productName(string): Official product name on G2.productSlug/productUrl/reviewsUrl: URL components for cross-linking back to G2 or joining rows together.thumbImageUrl(string | null): Product logo URL from G2's CDN. Some category-page images load lazily as SVG placeholders — those resolve tonull.
Search-Specific Fields (itemType: "Software")
searchUrl(string): The G2 search URL used.query(string): Keyword that produced this result.resultRank(number): Position in the search results (1 = top).itemType(string): Almost always"Software"—"Service"occasionally.foundVia(string): Static"g2"source marker.isSponsored(boolean):trueif this is a paid promotion.pricingType(string | null): Pricing indicator like"Free Trial","Free", etc.productId/productUuid: G2's internal numeric ID and UUID.descriptionSnippet(string): First ~500 chars of the marketing description.vendorName/vendorId/sellerName/sellerUrl: Vendor profile data.ratingOutOfFive(number): 0-5 star rating (e.g.,4.5).ratingOutOfTen(number): Same rating normalized to 0-10.reviewCount(number): Total review count.relatedCategories(array of strings): Category names this product belongs to.categoriesDetailed(array of objects):{ id, name, url }for each category.
Review-Specific Fields (type: "review")
type(string): Always"review"for this row type.review_id(number): Yelp-style internal review identifier (numeric).review_title(string | null): Review headline (frequentlynull— many G2 reviews don't have a separate title).review_content(string): Main body of the review — concatenated from the "What do you like best" answer if a structured Q&A exists.review_question_answers(object | undefined): Structured Q&A pairs G2 collects from reviewers. Typical keys:"What do you like best about X?","What do you dislike about X?","What problems is X solving and how is that benefiting you?".review_rating(number): 1-5 star rating with half-star precision (e.g.,4.5). Note: numeric here, unlike the search row'sratingOutOfFivewhich is also numeric — review_rating is per-review, not aggregate.reviewer(object): Reviewer profile —reviewer_id(number | undefined): G2's stable reviewer identifier — dedupe/join reviews by the same personreviewer_name(string): "Suraj J." style abbreviated namereviewer_job_title(string): "Junior AI Engineer"business_size(string): "Small-Business(50 or fewer emp.)", "Mid-Market(51-1000 emp.)", "Enterprise(>1000 emp.)"
publish_date(string): ISO date the review was published (e.g.,"2026-05-04").video_review(boolean | undefined):truewhen the reviewer submitted a video review.product_slug/product_name: Join keys back to the product.product_id/product_uuid/vendor_id: G2's internal product and vendor identifiers — stable join keys across row types and runs.review_link(string): Direct URL to the individual review on G2.
Product-Specific Fields (type: "product")
type(string): Always"product"for this row type.productName(string): Official product name (e.g.,"Postman").productSlug(string): URL slug (e.g.,"postman").productUrl(string): Canonical product page URL.reviewsUrl/competitorsUrl(string): Convenience cross-links to the other URL types you can scrape for the same product.vendorName/vendorSlug/vendorUrl(string | null): Vendor / seller profile (e.g.,"Postman"→/sellers/postman).description(string): Full marketing description — typically 400-2000 chars. Sourced from[itemprop="description"]then<meta name="description">as fallback.ratingOutOfFive/ratingOutOfTen(number): Aggregate star rating from[itemprop="ratingValue"].reviewCount(number): Total review count from[itemprop="reviewCount"].pricingTiers(array of strings): Names of pricing tiers G2 displays (e.g.,["Free Plan", "Basic Plan", "Professional Plan"]). Extracted fromh3/h4headings inside the pricing section, filtered to known tier keywords (Plan, Tier, Pro, Enterprise, etc.).featuresText(string | null): Raw text dump of the features section (~2000 chars cap). Caller can split/parse downstream.images(array of strings): G2-CDN image URLs (logo, screenshots). Badges and award icons are filtered out.imageCount(number): Length ofimages.status(string):"SUCCEEDED"on a successful parse.
Note: categories aren't extracted from the product detail page because G2's nav menu mixes its global category list with the product's own categories. To get a product's categories, scrape its /products/{slug}/reviews URL (type: "review" rows don't carry them, but the search/category endpoints do) or use a /categories/{slug} listing.
Competitor-Specific Fields (type: "competitor")
type(string): Always"competitor"for this row type.sourceProductSlug(string): The slug of the product whose competitors were scraped (e.g.,"postman"). Lets you trace each row back to its source.competitorRank(number): Rank within the source product's competitors page (1 = top alternative). Numbers are clean 1..N — the source product itself is filtered out before ranking.productName/productSlug/productUrl/reviewsUrl: Standard product identifiers (same shape as in other row types).thumbImageUrl(string | null): Product logo URL. May benullfor lazy-loaded placeholders.descriptionSnippet(string): First ~600 chars of the product's marketing description.vendorName(string | null): Company that produces the product (e.g.,"Salesforce","Microsoft").ratingOutOfFive/ratingOutOfTen(number): Aggregate star rating.reviewCount(number): Total review count.entryLevelPrice(string | null): Pricing string when displayed ("$25.00 Per User Per Month","Free","Contact Us"),nullotherwise.
Category-Specific Fields (type: "category_product")
type(string): Always"category_product"for this row type.categorySlug(string): The category slug from the URL (e.g.,"crm"or"crm/sales-acceleration").page(number): Which paginated page this product was found on (1-based).position(number): G2-assigned rank position in the category (1 = highest-scoring).listType(string | null): G2's internal list classifier —"sponsored","featured", etc., ornullfor standard listings.isSponsored(boolean):trueif this listing is paid promotion.productId/productUuid/productName/productSlug/productUrl: Same as in other row types.productCategory/productCategoryId(string / number): Category name and G2's internal category ID.vendorId/vendorSlug/vendorName: Vendor profile.ratingOutOfFive(number): Star rating extracted from the<div class="stars stars-N">CSS class (N/2 = rating).ratingOutOfTen(number): Same rating normalized to 0-10.reviewCount(number): Total review count for the product.entryLevelPrice(string | null): Pricing string like"Starting at $25.00 Per User Per Month","$15.00","Free","Contact Us", ornullif pricing isn't displayed on the card.descriptionSnippet(string): First ~600 chars of the product's marketing description.
Vendor-Specific Fields (type: "vendor")
type(string): Always"vendor"for this row type.vendorName(string): Company name (e.g.,"Salesforce").vendorSlug(string): URL slug used by G2 (e.g.,"salesforce").vendorUrl(string): Canonical vendor page URL.description(string): About / company description, capped at 2000 chars. Falls back to<meta name="description">if no "About" section is present.companyDetails(object): Sidebar facts pulled from the "Details" panel. Each field can benullif G2 doesn't display it for that vendor.founded(string | null): Year founded (e.g.,"1999").hqLocation(string | null): Headquarters location (e.g.,"San Francisco, CA").ownership(string | null): Ownership / ticker (e.g.,"NYSE:CRM","Private").totalRevenue(string | null): Total revenue (USD mm), where shown.employees(string | null): LinkedIn employee count, where shown.phone(string | null): Contact phone number, where shown.
products(array of objects): The vendor's product portfolio. Merges the "Featured Products" + "All Products & Services" sections, deduped by slug. Each entry:productSlug(string)productName(string)productUrl(string) — links to/products/{slug}/reviewsratingOutOfFive(number) — extracted from thestars-NCSS class (N/2)reviewCount(number) — parsed from the "{N,NNN} reviews" text on the carddescriptionSnippet(string) — usually empty on vendor cards; use/products/{slug}for full marketing copy
productCount(number): Length ofproducts.totalReviewsAcrossProducts(number): Aggregate review count across all of the vendor's products. Sourced from the page title (Read N Reviews on G2) when present; falls back to summing each product'sreviewCount.status(string):"SUCCEEDED"on a successful parse.
Review-Summary-Specific Fields (type: "review_summary")
Emitted once at the start of each /products/{slug}/reviews walk (skipped when filters are supplied).
type(string): Always"review_summary".productSlug/productUrl: Identifiers for joining withtype: "review"rows.summaryText(string): G2's AI-generated paragraph summarizing the review corpus. Capped at 2000 chars.pros(array of{ label, mentions }): Top mentioned positives, sorted by mention count.cons(array of{ label, mentions }): Top mentioned negatives, sorted by mention count.aggregateRating(number | null): Average star rating across all reviews (e.g., 4.6).totalReviews(number | null): Total review count from the schema.org markup.
Pricing-Specific Fields (type: "pricing")
type(string): Always"pricing".productSlug/productName/productUrl/pricingUrl: Standard product identifiers + link to the pricing tab.tiers(array of objects): One entry per pricing edition G2 displays.tierName(string): e.g.,"Free Plan","Basic Plan","Enterprise Plan".price(number | null): Numeric price extracted from schema.org<meta itemprop="price">.nullfor "Contact Us"-style tiers.currency(string | null): ISO currency code (e.g.,"USD").rawPrice(string): Human-readable price chunk including billing cadence (e.g.,"$14 / 1 per user/month, billed annually").
tierCount(number): Length oftiers.priceMin/priceMax(number | null): Min/max numeric price across all tiers — useful for quick range filtering.currency(string | null): Currency forpriceMin/priceMax.keyInsights(string): G2's "Pricing Key Insights" paragraph (e.g., "X offers 4 pricing editions, starting from $0 to $49…"). Capped at 2000 chars.faqs(array of{ question, answer }): Pricing FAQs G2 displays at the bottom of the page, parsed from the schema.orgQuestion/acceptedAnswermarkup.faqCount(number): Length offaqs.
Compare-Specific Fields (type: "compare")
type(string): Always"compare".compareUrl(string): Canonical compare URL (G2 may reorder slug segments).combinedSlug(string): Slug section from the URL (e.g.,"postman-vs-mulesoft-anypoint-platform").products(array of objects): One entry per product in the comparison.productSlug/productName/productUrlvendorName(string | null)ratingOutOfFive(number) — aggregate G2 ratingreviewCount(number)
productCount(number): Length ofproducts.ratings(array of objects): One entry per ratings criterion shown on the page.criterion(string): e.g.,"Meets Requirements","Ease of Use","Ease of Setup","Quality of Support".perProduct(array): Aligned with theproductsarray. Each entry has:score(number | null): 0–10 score (e.g., 8.8).nullif G2 shows "Not enough data".sampleSize(number | null): Number of reviewers contributing to the score.note(string | null): Optional annotation like"won by default"or"Not enough data".
ratingsCount(number): Length ofratings.alternativesShown(array of{ productSlug, productName, productUrl }): Products G2 surfaces in the sidebar as alternative comparisons.
situationalAwards (on type: "category_product")
Array of strings — G2 Grid®-style quadrant winners for the source category. Possible values:
"Leader"— top-right quadrant (high market presence + high satisfaction)"Highest Performer"— top-left quadrant (high satisfaction)"Easiest to Use"— top of the easiest-to-use list"Top Trending"— fastest-growing in the category"Best Free Software"— leader among free-plan offerings
Most products have an empty array; only a handful per category carry awards. Source: G2 marks these via data-event-options analytics payloads ("Situational Best / X: Product Card Clicked").
Use Cases
1. Competitive Vendor Shortlist
Walk a G2 category and rank vendors by review count + rating.
2. Customer-Voice Analysis on a Single Product
Pull every review for a product to feed into sentiment/NPS analysis.
3. Market Research Across Subcategories
Aggregate everyone in a niche category.
4. Brand Monitoring via Keyword Search
Track which products show up for specific search terms.
5. Competitor Discovery for a Specific Product
Pull G2's curated Top 10 alternatives to your product (or your competitor's).
6. Product Profile Extraction
Pull a single product's full profile (description, pricing, rating, screenshots) — useful as a feed source for product databases.
7. Full Competitor Deep-Dive
Mix all nine URL types — category overview, search peer set, curated competitor list, product profile, vendor portfolio, review feed, pricing tab, and a head-to-head compare — in a single run.
8. Vendor Portfolio Snapshot
Pull a vendor's full product portfolio in one row — company facts (HQ, ownership, phone) plus rating + review count for every product the vendor sells. Useful for competitive intelligence on multi-product vendors.
9. Pricing Intelligence
Pull structured pricing tiers + key insights for a set of competitors. Each row gives you per-tier price, currency, billing cadence, and G2's curated pricing FAQs.
10. Head-to-Head Comparisons
Pull G2's per-criterion comparison data (Meets Requirements, Ease of Use, Ease of Setup, Quality of Support, etc.) for product matchups — same data G2 publishes on its /compare/ pages.
11. Filtered Review Slice
Use G2's native filter syntax to grab just the slice of reviews you need — e.g., enterprise reviewers only, 5-star only, latest first.
12. G2 Grid® Quadrant Awards by Category
Walk a category to capture which products are G2's "Leader", "Highest Performer", "Easiest to Use", "Top Trending", and "Best Free Software" — the same labels G2 displays on its Grid® reports.
Filter the output by situationalAwards.length > 0 to surface only the awarded products.
Performance & Limits
- Rate Limiting: Built-in 8-15s jittered delays between page fetches. Don't set
maxConcurrencyhigher than 3 — G2's DataDome rate-limits per cookie. - Pagination depth: Tested cleanly to 100 pages on a single product reviews URL (1,000 reviews) with zero blocks.
- Memory: Each product row is ~1-3 KB; each review row is ~1-2 KB.
- Speed:
- Search / category: ~5-7 products per page, ~10s per page → ~30-40 products/min
- Reviews: ~10 reviews per page, ~10s per page → ~60 reviews/min
- Proxy Requirement: Residential proxies strongly recommended. Datacenter IPs are blocked on first request.
Error Handling
The scraper includes comprehensive error handling:
- Multi-Client TLS Race: Three independent HTTP clients (impers/impit/got-scraping) race in parallel — different TLS fingerprints survive different blocks.
- Session Pool with Rotation: Pre-warmed browser sessions with valid Datadome cookies, automatically rotated round-robin to stay under per-cookie rate limits.
- Legacy Fallback: If the session pool is empty, falls back to a DataDome-cookie service flow that races the three clients with fresh fingerprints.
- Exponential Back-off: Failed requests back off exponentially (10s → 15s → 22s → ...) with jitter. Hard short-circuit after 10 consecutive blocks to avoid retry storms.
- Automatic Retries: Failed requests retry up to
maxRequestRetriestimes. - Smart Pagination: Stops automatically when reaching the last page or when no results appear.
- Graceful Failures: Continues scraping even if individual pages fail.
Troubleshooting
No Results Returned
- Check the URL opens correctly in a browser — G2 occasionally redirects category slugs.
- Verify residential proxies are enabled.
- Lower
maxConcurrencyto1and try again.
Scraper Stops Early on Reviews
- Check the run's logs for
[fetchG2] anti-bot signalpatterns. If you see >5 in a row, the session pool is exhausted — the warmer schedule needs to fire to refresh it. - Set
slowMode: truefor tighter rate-limit avoidance.
Missing or Mangled Fields
entryLevelPriceisnullwhen G2 doesn't display pricing on the category card.review_titleis frequentlynull— G2's modern review layout doesn't have separate titles.thumbImageUrlisnullfor products whose images are still lazy-loaded SVG placeholders when the page renders.
Support & Contact
For custom solutions, bulk scraping, or support:
- 📧 Email: muhamed.didovic@gmail.com
- 🌐 Website: https://muhamed-didovic.github.io/
- 🏪 Apify Store: Search for "G2.com Software Scraper"
- 💬 Apify Support: Contact through Apify platform
Explore More Scrapers
If you found this Apify Scraper useful, be sure to check out our other powerful scrapers and actors at memo23's Apify profile. We offer a wide range of tools to enhance your web scraping and automation needs across various platforms and use cases.
Legal & Ethical Use
- This scraper is intended for legitimate business and research purposes only.
- Respect G2.com Terms of Service.
- Use responsibly and ethically.
- Do not overload servers with excessive requests.
- Consider using data for analysis and research within legal boundaries.
FAQ
Q: How many products / reviews can I scrape per run? A: Tested cleanly to 1,000+ reviews per product in a single run. Total run capacity scales with how many fresh sessions the warmer has populated in the pool. Free Apify users have a per-run row cap.
Q: Do I need to provide DataDome cookies? A: No. The actor uses a self-managed session pool that pre-captures cookies via a headless browser warmer, refreshed every 10 minutes. The cookies are completely transparent to you.
Q: Can I mix all five URL types in one run?
A: Yes — that's exactly what startUrls supports. Each URL is dispatched to the correct handler based on its path.
Q: How many competitors does each /competitors URL return?
A: G2 renders a fixed "Top N" (typically 9-10) per source product. There's no pagination — one run per source product gives you the complete curated list.
Q: Why is review_title always null?
A: G2's modern review layout merged the title with the "What do you like best" Q&A answer. The review_question_answers.{"What do you like best about X?"} field carries that content.
Q: How fresh is the data? A: Real-time — every URL is fetched live on each run. No caching.
⚠️ Disclaimer
This actor collects only publicly available information from G2.com. It does not log in, bypass authentication, or access private or personal data. You are responsible for ensuring your use of the scraped data complies with G2's Terms of Service, applicable robots directives, and all relevant laws and regulations (including data-protection laws such as GDPR and CCPA where personal data is involved). This is an independent tool and is not affiliated with, endorsed by, or sponsored by G2.com, Inc. "G2" and all related names and marks are trademarks of their respective owners and are used here for descriptive purposes only. Use this actor for lawful research, analytics, and market-intelligence purposes.
SEO Keywords
g2 scraper, g2.com scraper, g2 reviews scraper, g2 software reviews, g2 ratings scraper, g2 product data, g2 vendor data, g2 category scraper, g2 pricing scraper, g2 compare scraper, g2 competitor analysis, software reviews api, saas reviews scraper, b2b software data, software market research, product reviews scraper, review aggregator scraper, g2 crowd scraper, software comparison data, vendor intelligence
Built with ❤️ by Muhamed Didovic
Last Updated: June 2026
More Review Scrapers
Need reviews from other platforms? Same author, same export format:
- Trustpilot — business & product reviews: apify.com/memo23/trustpilot-scraper-ppe
- Capterra — software reviews & product profiles: apify.com/memo23/capterra-scraper
- Gartner — enterprise software reviews: apify.com/memo23/apify-gartner-scraper-ppr
- Yelp — local business reviews & ratings: apify.com/memo23/yelp-scraper
🤖 Related MCP servers for AI agents
Building an AI agent, or using Claude, Cursor or ChatGPT? Skip the scraping setup — connect our hosted MCP servers (no API keys, billed per call):
- Reviews MCP Server — search companies, read real Trustpilot review texts, and pull multi‑platform ratings (Trustpilot + App Store + Google Play) straight from your assistant.
- Reddit MCP Server — search Reddit, browse subreddits, read comment threads.
- Email Finder & Verifier MCP — find and verify company emails.
- Video Transcripts MCP — full YouTube & TikTok transcripts.