TeamBlind Reviews scraper
Pricing
from $2.80 / 1,000 results
TeamBlind Reviews scraper
Scrape every public review for any company on TeamBlind. Returns rating, full pros & cons, job title, tenure, date, and reviewer location — plus a per-company summary with logo, HQ, employee size, average ratings, and reviewer city/country. No login required. Proxies included.
Pricing
from $2.80 / 1,000 results
Rating
5.0
(1)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
0
Bookmarked
32
Total users
8
Monthly active users
3 days ago
Last modified
Categories
Share
Scrape every review for any company on TeamBlind — full pros, cons, ratings, job titles, dates. One row per review, one row per company. No login required, proxies included.
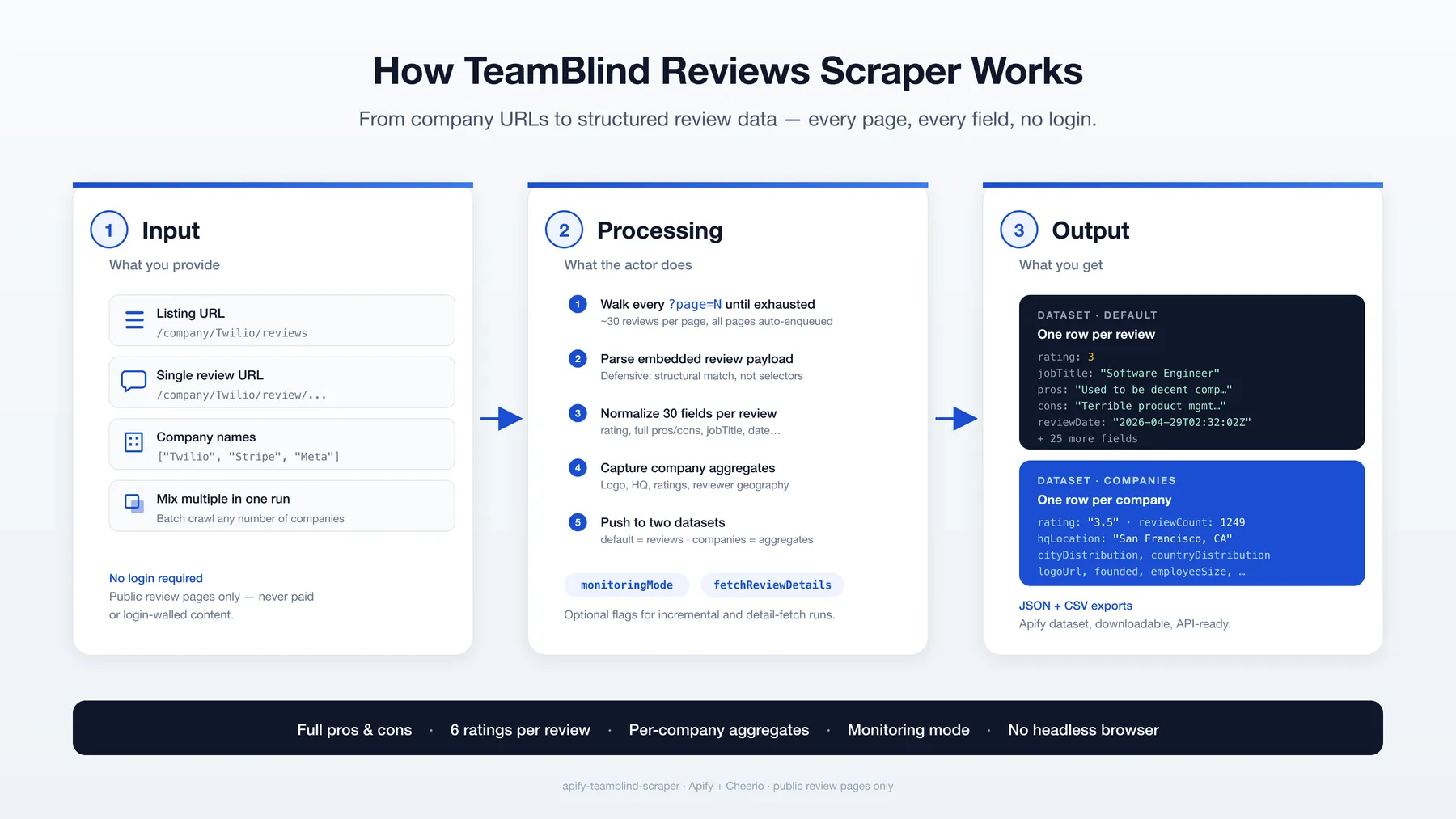
How it works
✨ Why use this scraper?
Tired of TeamBlind scrapers that break every other week? Glassdoor wrappers that miss half the fields? Tools that truncate pros/cons at 200 chars?
- 📝 Full pros and cons text. No truncation, no "read more" cut-offs. Every review delivered with the same text the reviewer wrote.
- ⭐ Six ratings per review. Headline overall rating plus career, work-life balance, compensation, culture, and management — each on the 1–5 scale.
- 👤 Reviewer context. Job title (mapped from
jobgroup), tenure years, location, country ISO code, current-vs-former employee flag. - 🏢 Per-company aggregates. A second dataset row per company with logo, HQ, founded year, employee size, industry, average ratings, and reviewer city/country histogram.
- 🔁 Monitoring mode. Skip reviews already scraped in earlier runs. Useful for incremental tracking.
- ⚡ Fast by default. Built on the
impitHTTP client with sliding-window concurrency and parallel pagination. ~3.6 s for 100 reviews of one company on the test machine. - 🛡 Login-wall bypass for pros/cons. TeamBlind serves real review text only on page 1 to logged-out viewers and replaces page-2+ content with
Lorem ipsum…. The scraper detects this automatically and recovers the real text from each review's permalink page. No auth needed. No flag to flip. - 🚫 No auth, no headless browser. Pure HTTP + Cheerio. Public review pages only — no login walls, no paid features touched.
🎯 Use cases
| Team | What they build |
|---|---|
| HR / Recruiting | Employer-reputation dashboards; surface what current and former employees say about pay and management. |
| Market research | Company-vs-company sentiment benchmarks across industries. |
| Competitive intel | Track tone shifts at a competitor over time (combined with monitoring mode). |
| Investors / analysts | Workforce-sentiment signals as a leading indicator alongside financials. |
| Journalists | Source-rich workplace stories with verifiable, structured pros/cons text. |
| Internal teams (anonymous read-back) | Pull your own company's reviews into a BI tool without manual copy-paste. |
✅ Supported inputs
The scraper accepts two URL types and one shorthand:
| Input | Example | Result |
|---|---|---|
| Listing URL | https://www.teamblind.com/company/Twilio/reviews | All reviews for Twilio, paginated through every ?page=N. |
| Single-review URL | https://www.teamblind.com/company/Twilio/review/z-eM7ygC89 | Just that one review. |
| Company name shorthand | ["Twilio", "Stripe", "Meta"] (via companyNames) | Built into listing URLs automatically. |
Not supported (intentionally — outside client scope or behind a login):
- ❌ Salary URLs (
/company/{co}/salaries) - ❌ Benefits URLs (
/company/{co}/benefits) - ❌ Article / channel URLs (
/article/{id},/channels/{name}) - ❌ User profile URLs
- ❌ Anything requiring TeamBlind login (verified-employee discussion threads)
🔁 How the flow works
- You provide one or more company review URLs (or just company names).
- The scraper walks every page of reviews for each company until exhausted or
maxItemsis reached. - For each review, it captures rating, full pros/cons, job title, date, and ~25 supporting fields.
- For each company, it writes one row to a separate
companiesdataset with logo, HQ, employee size, average ratings, and reviewer geography. - Optional
monitoringModeskips reviews already collected in earlier runs.
Engine
The scraper uses the impit HTTP client (Firefox TLS fingerprint, HTTP/3 when no proxy) with a global sliding-window concurrency pattern. Page 1 is fetched first to learn totalCount, then pages 2..N are fanned out in parallel. ~3.6 s for 100 reviews on the test machine. No headless browser, no Crawlee request queue overhead.
📥 Input parameters
Start
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
startUrls | array | * | — | TeamBlind URLs to scrape: listing URLs or single-review URLs. |
companyNames | array | * | — | Company names (case-sensitive, exactly as in TeamBlind URLs). Each becomes https://www.teamblind.com/company/{name}/reviews. |
* Either startUrls or companyNames is required.
Options
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
maxItems | integer | No | 1000 | Hard cap on reviews scraped across all start URLs in this run. |
monitoringMode | boolean | No | false | Skip reviews seen in earlier runs (per-user key-value store). |
fetchReviewDetails | boolean | No | false | Make one extra HTTP call per review to its permalink. The listing already contains everything, so this is opt-in for redundancy. |
maxConcurrency | integer | No | 10 | Maximum simultaneous page fetches. |
minConcurrency | integer | No | 1 | Minimum simultaneous page fetches. |
maxRequestRetries | integer | No | 5 | Retry attempts on failed requests. |
proxy | object | No | Apify residential | Proxy configuration. Apify residential recommended. |
📊 Output overview
The actor writes to two datasets:
default— one row per review (~30 fields). This is the main output.companies— one row per company crawled (~18 fields), pushed when page 1 of that company's reviews is processed.
Both formats export to JSON and CSV. Different start URLs for the same company produce a single deduped company row.
📊 Output samples
Review row (default dataset)
Real row from https://www.teamblind.com/company/Twilio/reviews:
Company row (companies dataset)
🗂️ Key output fields
Review identifiers
| Field | Type | Description |
|---|---|---|
id | integer | TeamBlind's internal review ID. Stable across runs. |
urlAlias | string | Short slug used in the review permalink (e.g. z-eM7ygC89). |
sourceUrl | string | Direct permalink to the review on TeamBlind. |
Ratings
| Field | Type | Description |
|---|---|---|
rating | integer (1–5) | Headline overall rating. |
ratingsBreakdown.career | integer (1–5) | Career opportunities / growth. |
ratingsBreakdown.balance | integer (1–5) | Work-life balance. |
ratingsBreakdown.compensation | integer (1–5) | Pay and benefits. |
ratingsBreakdown.culture | integer (1–5) | Company culture. |
ratingsBreakdown.management | integer (1–5) | Quality of management. |
Review content
| Field | Type | Description |
|---|---|---|
pros | string | Full "what's good" text. Newlines preserved. Never truncated. |
cons | string | Full "what's bad" text. Never truncated. |
summary | string | Reviewer-supplied one-line headline. |
reasonResign | string | null | Why the reviewer left. Usually null for current employees. |
Reviewer / job info
| Field | Type | Description |
|---|---|---|
jobTitle | string | Job title as shown on TeamBlind (mapped from jobgroup — TeamBlind's own jobTitle is always null). |
memberJobgroupId | integer | Numeric job-group ID. Useful for grouping across companies. |
jobFamilyId | integer | Higher-level job family ID (e.g. 6 = Engineering). |
memberLocation | string | City+state or country (e.g. San Francisco, CA, Ireland). |
memberLocationCountryIsoCode | string | ISO-3166 alpha-2 country code. |
memberStart | integer | Year the reviewer started. |
memberEnd | integer | null | Year they left. null for current employees. |
isCurrentEmployee | boolean | Derived: true when memberEnd is null. |
nickname | string | Anonymized nickname (e.g. u*****). TeamBlind masks all but the first character. |
memberId | integer | TeamBlind's internal numeric ID for the reviewer. |
Timestamps
| Field | Type | Description |
|---|---|---|
reviewDate | ISO 8601 | When the review was posted. |
updatedAt | ISO 8601 | Last edit (equal to reviewDate when never edited). |
approvedAt | ISO 8601 | Moderation approval timestamp. |
Engagement & moderation
| Field | Type | Description |
|---|---|---|
helpfulCnt | integer | Number of "helpful" votes. |
companyResponse | string | null | Official company reply text, when present. |
companyResponseAt | ISO 8601 | null | Timestamp of the company reply. |
isPinned | Y / N | Pinned at the top of the company list. |
isFeatured | boolean | null | Featured in TeamBlind editorial. |
status | string | Moderation status (A = active). |
Company references
| Field | Type | Description |
|---|---|---|
companyName | string | Display name of the company. |
companyPageId | integer | Internal numeric page ID. |
companyChannelId | integer | Internal channel ID (different from companyPageId). |
Company-row fields (companies dataset)
| Field | Type | Description |
|---|---|---|
urlAlias, companyId, companyName | id + display | Identifiers. |
logoUrl, bgImgUrl | URL | Company logo and industry banner. |
webSiteUrl | string | Homepage (no protocol, e.g. www.twilio.com). |
founded, employeeSize, hqLocation | string | "2008", "1,001 to 5,000 employees", "San Francisco, CA". |
industryId, industryName | id + name | E.g. 247, "Internet". |
description | string | Company blurb. |
plan, isPremium | string | TeamBlind subscription state. |
rating | string | Headline overall rating (e.g. "3.5"). |
ratingsBreakdown | object | Sub-rating averages, string values like "3.2". |
reviewCount | integer | Total reviews on TeamBlind for this company. |
cityDistribution | array | [{ name, count }, …] reviewer city histogram, sorted by count. |
countryDistribution | array | [{ isoCode, name, count }, …] country histogram. |
sourceUrl | string | The listing URL we crawled. |
🚀 Examples
Scrape one company
Scrape several companies by name
Pull a single review
Incremental monitoring run
💻 Integrations
Python
JavaScript
💡 Tips for best results
- Start with
maxItems: 30to test. That's roughly one page of reviews. Verify the output before running large jobs. - Use
companyNamesfor batches. It's faster than typing every URL and dedupes the company-summary row automatically. - Skip
fetchReviewDetailsunless you need it. The listing payload already has every field. Enabling it doubles requests for no extra data. - Use
monitoringModefor daily/weekly tracking. Combined with a scheduled run, it gives you only-new-reviews delivery. - Pair the two datasets. Join review rows on
companyNameto the company row to get rating context per review.
❓ FAQ
Which TeamBlind URLs are supported?
Listing URLs (/company/{co}/reviews) and single-review URLs (/company/{co}/review/{alias}). Plus the companyNames shorthand which is converted to listing URLs.
Does this scrape salaries or benefits? No — only reviews. That matches the original client scope. Salary and benefits pages have different shapes and would need a separate scraper.
Are pros and cons truncated? No. The full text is returned exactly as written. Newlines are preserved.
Why was I getting "Lorem ipsum dolor sit amet…" as pros/cons in older runs?
TeamBlind shows the first 30 reviews (page 1) with full content for unauthenticated viewers, then replaces every review's pros/cons with the standard Lorem ipsum… boilerplate from page 2 onwards to gate content behind a sign-in wall. Other fields (rating, job title, date, location) come back correct on every page. The scraper now detects this automatically and recovers the real pros/cons by fetching each gated review's detail page (/company/{co}/review/{alias}), which is not gated — no auth required. You'll see [bypass] N/30 reviews on this page are Lorem-gated — fetching detail pages in parallel in the logs. This adds one HTTP request per gated review, parallelized so wall-clock impact is small.
Does it require a TeamBlind login? No. The actor only hits public review pages. No verified-employee discussion threads, no login wall content.
Why are reviewer names masked like u*****?
That's how TeamBlind anonymizes reviewers on the public page. We pass through what they show.
Why is the actual jobTitle field always null in the raw payload?
TeamBlind has both a jobTitle field (always null on public reviews) and a jobgroup field (populated, e.g. "Software Engineer"). The actor maps jobgroup → jobTitle so the output uses the field name you'd expect.
What happens when TeamBlind changes their layout?
The parser walks every script tag and finds review-shaped objects by structural matching, not by fragile component names. If the embedded payload disappears entirely, the actor logs a clear "could not locate reviews payload — TeamBlind layout may have changed" warning instead of silently producing empty rows.
Can I scrape multiple companies in one run?
Yes. Pass either multiple startUrls or multiple companyNames. Each company gets its own row in the companies dataset.
What about rate limits and blocks? The actor uses Apify's session pool with proxy rotation. Apify residential proxy is recommended for production runs.
💻 Local development
Edit storage/key_value_stores/default/INPUT.json to change inputs. Outputs land in storage/datasets/default/*.json (reviews) and storage/datasets/companies/*.json (per-company aggregates), plus data.csv / data.json exports in the project root.
📬 Support
- For issues or feature requests, please use the Issues section of this actor on the Apify platform.
- Author's website: https://muhamed-didovic.github.io/
- Email: muhamed.didovic@gmail.com
Response time: usually under 24 hours.
🔧 Additional services
- Custom modifications, whole-dataset exports, scheduled deliveries: muhamed.didovic@gmail.com
- Need something else scraped? Email above.
- API services for this scraper (no Apify fee, just usage fee): contact muhamed.didovic@gmail.com
🔍 Explore more scrapers
If you found this useful, check out our other Apify actors at memo23's Apify profile — including scrapers for Dice.com, LandSearch, Bayut, and more.
⚠️ Disclaimer
This Actor is an independent tool and is not affiliated with, endorsed by, or sponsored by Team Blind, Inc. or any of its subsidiaries. All trademarks mentioned are the property of their respective owners.
The scraper accesses only publicly available review pages — no authenticated endpoints, paid features, or content behind the TeamBlind login wall. Users are responsible for ensuring their use complies with TeamBlind's Terms of Service, applicable data-protection law (GDPR, CCPA, etc.), and any contractual obligations of their own organization.
SEO Keywords
teamblind scraper, scrape teamblind, teamblind reviews scraper, teamblind API, employee reviews scraper, anonymous workplace reviews scraper, company reviews scraper, glassdoor alternative scraper, teamblind.com scraper, Apify teamblind, scrape company reviews, employer reputation data, workplace sentiment scraper, blind app scraper, tech company reviews scraper, employee feedback scraper, pros and cons scraper, employer ratings scraper, anonymous employee reviews, company culture data, teamblind data export