TripAdvisor Reviews Scraper 💰$0.45/1k | Hotels Restaurants
Pricing
from $0.45 / 1,000 results
TripAdvisor Reviews Scraper 💰$0.45/1k | Hotels Restaurants
TripAdvisor Reviews Scraper at $0.45/1k — 4x cheaper than the leader. Pull hotel, restaurant & attraction reviews with place metadata (rating, address, geo, histogram) in every row. Filter by rating, language & date; add reviewer profiles. Search-query or URL input. JSON/CSV out.
Pricing
from $0.45 / 1,000 results
Rating
5.0
(2)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
0
Bookmarked
45
Total users
21
Monthly active users
19 hours ago
Last modified
Categories
Share

TripAdvisor Reviews Scraper — Hotels, Restaurants & Attractions
Scrape TripAdvisor reviews at $0.45 per 1,000 results — about 4x cheaper than the market leader, and one actor instead of a two-step funnel. Paste any hotel, restaurant, or attraction URL (or just a city name) and get clean, structured review rows — each already enriched with the place's full metadata (rating, address, geo, ranking, rating histogram). Filter by star rating, language, and date; optionally add reviewer profiles and contact emails. JSON, CSV, or Excel out.
Why Use This Scraper?
- ✅ Cheapest serious option — $0.45/1,000 results. The category leader charges around $1.90/1,000 at its entry tier. Same review data, a fraction of the bill.
- ✅ One actor, not two. Reviews and place snapshots come from the same run — no separate "find places" actor feeding a separate "reviews" actor.
- ✅ Hotels, restaurants, and attractions — all three place types, all through one input.
- ✅ Review + place metadata in every row. Each review already carries
placeInfo(rating, address, lat/lng, ranking, histogram). No follow-up enrichment step. - ✅ Server-side filters for star rating, language, per-place limit, plus an absolute or relative date cutoff.
- ✅ Search-query → geo expansion. Type
"Chicago"and let the actor discover hotels, restaurants, and attractions for that location. - ✅ Optional reviewer profiles and contact-email enrichment.
- ✅ Flat, nested, or place-only output for whatever your pipeline expects.
Overview
The TripAdvisor Reviews Scraper is built for reputation teams, market analysts, researchers, and agencies who need structured review data from TripAdvisor without stitching together multiple tools.
By default the output is review-shaped: one dataset row per review, each carrying a compact placeInfo block for the parent hotel/restaurant/attraction. That means even if you start from a listing URL (a city's restaurants hub) or a search query, the run still resolves down to a stream of review rows — not separate "listing" rows.
Two other shapes are available when you need them:
- Place-only snapshots (
scrapeReviews: false) — one rich row per place (ranking, amenities, category scores, nearby venues) and no reviews. Fast and low-cost for competitor monitoring. - Nested (
outputShape: "nested") — one row per place with areviews[]array inside.
Supported Inputs
URL types
| URL type | Pattern | Example |
|---|---|---|
| Hotel place | Hotel_Review-g{geo}-d{id}-Reviews-{slug}.html | https://www.tripadvisor.com/Hotel_Review-g60763-d208453-Reviews-Hilton_New_York_Times_Square-New_York_City_New_York.html |
| Restaurant place | Restaurant_Review-g{geo}-d{id}-Reviews-{slug}.html | https://www.tripadvisor.com/Restaurant_Review-g60763-d25324283-Reviews-Allora_Fifth_Ave-New_York_City_New_York.html |
| Attraction place | Attraction_Review-g{geo}-d{id}-Reviews-{slug}.html | https://www.tripadvisor.com/Attraction_Review-g60763-d105123-Reviews-Statue_of_Liberty-New_York_City_New_York.html |
| Restaurants GEO hub | Restaurants-g{geo}-…{City}.html | https://www.tripadvisor.com/Restaurants-g35805-Chicago_Illinois.html |
| Hotels GEO hub | Hotels-g{geo}-…-Hotels.html | https://www.tripadvisor.com/Hotels-g60763-New_York_City_New_York-Hotels.html |
| Attractions GEO hub | Attractions-g{geo}-Activities-…html | https://www.tripadvisor.com/Attractions-g60763-Activities-New_York_City_New_York.html |
| Restaurant finder | FindRestaurants?geo=…&establishmentTypes=… | https://www.tripadvisor.com/FindRestaurants?geo=188673&establishmentTypes=10591&broadened=false |
Listing/hub URLs expand (paginated, up to ~300 venues each) into individual place URLs, then each is scraped like a standalone place. maxItems applies per resolved place.
Copy-pasteable startUrls
Search / keyword mode
Unsupported inputs
- ❌
tripadvisor.co.uk/tripadvisor.*country mirrors — usewww.tripadvisor.com. - ❌ Vacation rentals, tours/experiences, and flights products.
- ❌ Hotel booking price offers / room rates.
- ❌ Non-TripAdvisor hosts and login-gated content.
Use Cases
| Audience | Use case |
|---|---|
| Hotel & restaurant ops | Daily review monitoring and owner-response SLA tracking |
| Reputation managers | Multi-property dashboards with rating-histogram drift over time |
| Market analysts | Competitive benchmarks across cities or chains using placeInfo.rating + numberOfReviews |
| Content / NLP teams | Multilingual review corpora for sentiment and topic models, filtered by language and rating |
| Researchers | One-shot dataset exports for BI, lake, or warehouse ingestion |
| Agencies | Client-ready TripAdvisor datasets without writing or maintaining a scraper |
How It Works
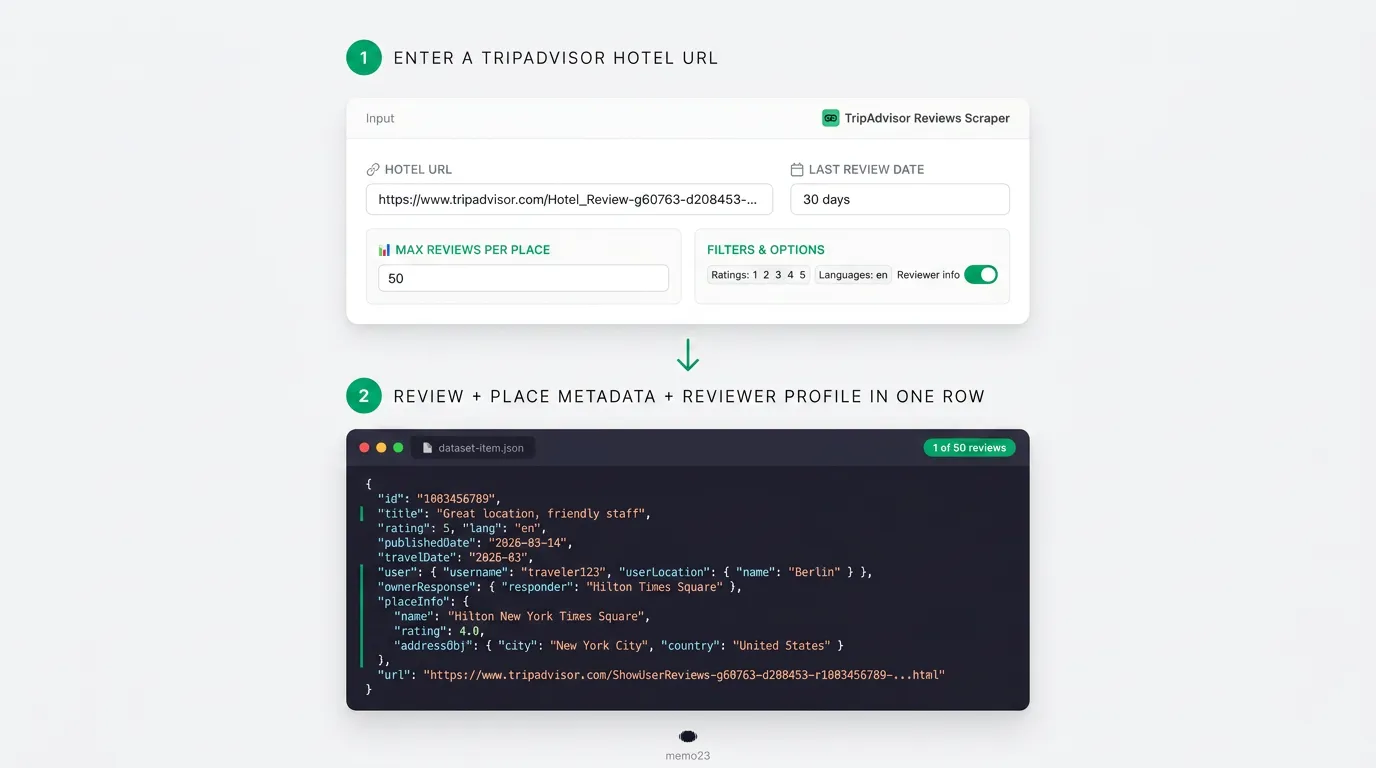
- Input — provide one or more TripAdvisor URLs, or a free-text
searchQuery(a city name). - Resolve — a
searchQuerybecomes a geoId, then expands into hotels, restaurants, and attractions per theinclude*toggles. Listing/hub URLs expand into place URLs. Plain place URLs are used directly. - Fetch place — load each place page (mobile-friendly HTML) and extract
placeInfofrom JSON-LD + meta (rating, review count, address, geo, ranking). - Page reviews — pull reviews from TripAdvisor GraphQL in concurrent batches, with
reviewRatings,reviewsLanguages, andmaxItemspushed into the request;lastReviewDateis applied per page with early-exit. - Optional enrichment — attach reviewer profiles (
scrapeReviewerInfo) and contact emails (enrichEmails). - Output — emit flat review rows (default), nested place rows, or place-only snapshots. Locations that yield 0 reviews or fail land in a side
tripadvisor-failuresdataset.
Input Configuration
| Field | Type | Default | Notes |
|---|---|---|---|
searchQuery | string | — | Free-text location (e.g. "Chicago"). Resolved to a geoId, then expanded by the include* toggles. Use with or instead of startUrls. |
startUrls | array of { url } | [] | Place URLs and/or listing/hub URLs. Listing URLs expand to venues; place URLs are scraped directly. |
maxItems | integer | 50 | Max reviews per place / per URL. 0 = unlimited (paginate every review). |
scrapeReviews | boolean | true | true → fetch reviews. false → emit one place-only snapshot row per place (no reviews). |
scrapeReviewerInfo | boolean | true | Populate each review's user object (username, hometown, contributions, avatar, profile link). false → user: null. |
includeReviewTags | boolean | true | Include placeInfo.reviewTags (theme phrases + counts) when TripAdvisor embeds them. |
includeHotels | boolean | true | With searchQuery, include hotels for the resolved geo. |
includeRestaurants | boolean | true | With searchQuery, include restaurants for the resolved geo. |
includeThingsToDo | boolean | true | With searchQuery, include attractions for the resolved geo. |
includeNearby | boolean | false | After each place, add up to 5 nearby venues as place-only snapshot rows (isNearbyResult: true). Depth capped at 1. |
outputShape | enum flat / nested | flat | flat = one row per review. nested = one row per place with reviews[]. No effect when scrapeReviews: false. |
lastReviewDate | string | — | Skip reviews before this date. Absolute YYYY-MM-DD or relative 22 days / 3 weeks / 6 months / 1 year. |
reviewRatings | array | ["ALL_REVIEW_RATINGS"] | Filter by star rating: "1"–"5" or ALL_REVIEW_RATINGS. |
reviewsLanguages | array | ["ALL_REVIEW_LANGUAGES"] | Filter by ISO 639-1 language code, or ALL_REVIEW_LANGUAGES. |
maxConcurrency | integer | 100 | Max pages processed concurrently. |
minConcurrency | integer | 1 | Min pages processed concurrently. |
maxRequestRetries | integer | 15 | Retries per failed request before giving up. |
proxy | object | Apify Residential | Proxy configuration. Residential is strongly recommended. |
enrichEmails | boolean | false | Find a contact email per place (from its website or by discovery). Adds contactEmail, contactWebsite, and an emailEnrichment object. Billed only when an email is found. |
Common scenarios
1. All reviews for a single hotel, with reviewer info
2. Recent 5-star English reviews across a city's restaurants
3. Place-only competitor snapshots (no reviews)
Output Overview
Each dataset item is, by default, one review row containing:
- Core —
id,url,title,text,rating,publishedDate,travelDate,tripType,lang - Reviewer —
userobject (username, hometown, contributions, avatar, profile link) whenscrapeReviewerInfo: true - Owner response —
ownerResponse(text + date) when the property replied - Extras —
subratings[],photos[],helpfulVotes - Parent place —
placeInfo(name, type, rating, web URL, and more)
When scrapeReviews: false, rows are { placeDetailOnly: true, placeInfo: {…} } with a much richer placeInfo (ranking, amenities, category scores, nearby venues, histogram).
Output Samples
Flat review row (default)
Place-only snapshot (scrapeReviews: false)
Key Output Fields
Review core
id,url,title,text,rating,lang,helpfulVotes
Dates & trip
publishedDate,publishedPlatform,travelDate,stayDate,tripType
Reviewer (scrapeReviewerInfo: true)
user.name,user.username,user.userLocation.name,user.contributions.totalContributions,user.avatar.image,user.link
Owner response & extras
ownerResponse.text,ownerResponse.publishedDate,subratings[],photos[]
Parent place (placeInfo)
placeInfo.name,placeInfo.type(HOTEL/EATERY/ATTRACTION),placeInfo.rating,placeInfo.webUrl- Place-only rows add:
numberOfReviews,rankingString,address,latitude,longitude,ratingHistogram,categoryReviewScores[],amenities[],nearbyLocations[]
Email enrichment (enrichEmails: true)
contactEmail,contactWebsite,emailEnrichment
How This Compares
| Capability | Category leader (two-actor funnel) | This actor |
|---|---|---|
| Price per 1,000 results | ~$1.90/1k at entry tier | $0.45/1k (~4x cheaper) |
| Places + reviews | Separate "find places" actor feeding a separate "reviews" actor | One actor does both |
| Hotels / restaurants / attractions | Split across actors | All three, one input |
| Review + place metadata in one row | Usually separate outputs | Yes — placeInfo on every review |
| Search-query → geo expansion | Varies | Built in (searchQuery) |
| Rating / language / date filters | Partial | Yes, pushed server-side |
| Reviewer profiles | Add-on | Optional (scrapeReviewerInfo) |
| Contact-email enrichment | No | Optional (enrichEmails, pay-on-hit) |
Honest scope: this actor does not cover vacation rentals, tours/experiences, flights, hotel price offers, or
sortBy/traveler-type filters. If you need those, it isn't the right tool.
FAQ
Which TripAdvisor URLs are supported?
Hotel, restaurant, and attraction place pages (…-g{geo}-d{id}-Reviews-…), plus GEO listing hubs (Restaurants-g…, Hotels-g…, Attractions-g…) and the FindRestaurants?geo=… finder. Listing URLs expand to individual venues. Use www.tripadvisor.com, not the tripadvisor.co.* mirrors.
Do I get review rows or place rows?
Review rows by default — one per review, each carrying a compact placeInfo. Set scrapeReviews: false for one place-only snapshot per place, or outputShape: "nested" for one place row with reviews[] nested.
How does maxItems work?
It caps reviews per place, applied independently to each URL and each venue discovered from a listing. Use 0 for unlimited.
Can I filter by rating, language, or date?
Yes. reviewRatings and reviewsLanguages are pushed into the TripAdvisor GraphQL request; lastReviewDate (absolute or relative) is applied per page with an early exit once a page is fully older than the cutoff.
Are reviewer profiles and emails always present?
user is populated when scrapeReviewerInfo: true (the default). Contact emails require enrichEmails: true and only appear when one is actually found — you are never charged for a miss.
What isn't supported?
Vacation rentals, tours/experiences, and flights products; hotel booking price offers; sortBy and traveler-type filters; and country-mirror domains. This actor focuses on hotel/restaurant/attraction reviews and place snapshots.
Can I scrape private or login-gated content?
No. The actor only reads publicly available TripAdvisor pages.
What about blocks and rate limits?
The actor uses a hardened anti-bot path (mobile Safari fallback, real-browser fingerprinting for GraphQL, single-shot DataDome detection). Residential proxies are strongly recommended. Blocked or empty locations are recorded in the tripadvisor-failures dataset rather than lost.
Support
Found a bug or need a new feature? Open an issue on the Issues tab or email muhamed.didovic@gmail.com.
Additional Services
Need a custom output shape, a new URL type, extra fields, or scheduled monitoring? I build tailored scrapers and data pipelines — email muhamed.didovic@gmail.com.
Explore More Scrapers
If you found this useful, you might also like:
- Capterra Scraper — software listings + reviews
- TrustRadius Scraper — B2B product reviews
- Google Maps Reviews — local business reviews and place data
Full list at apify.com/memo23.
🤖 For AI Agents & LLM Apps
Compact reference for AI agents calling this actor via the Apify MCP server or the Apify API (actor: memo23/tripadvisor-scraper).
Purpose: Scrape TripAdvisor hotel, restaurant, and attraction reviews (plus place snapshots) from any place/listing URL or a city search query — every review row carries parent-place metadata.
Minimal input:
Output: one dataset row per review — id, title, text, rating, lang, publishedDate, travelDate, tripType, helpfulVotes, user {name, username, userLocation, contributions, link}, ownerResponse, subratings[], photos[], placeInfo {id, name, type, rating, webUrl}. With scrapeReviews:false, rows are {placeDetailOnly:true, placeInfo{…}}.
Behaviors an agent should know:
- Always set
maxItems(it caps reviews per place);maxItems:0means unlimited and can be very large for popular places. startUrlsandsearchQuerycan be combined;searchQueryexpands viaincludeHotels/includeRestaurants/includeThingsToDo.outputShape:"nested"returns one row per place withreviews[];scrapeReviews:falsereturns place-only snapshots.- Billing: $0.45 / 1,000 results (per dataset item) + $0.0001 per additional-data item + $0.007 actor start (per GB).
enrichEmailsis billed only when an email is found. - Not supported: vacation rentals, tours, flights, hotel price offers,
sortBy/traveler-type filters, andtripadvisor.co.*mirrors.
⚠️ Disclaimer
This Actor is an independent tool and is not affiliated with, endorsed by, or sponsored by Tripadvisor LLC or any of its subsidiaries. All trademarks mentioned are the property of their respective owners.
The scraper accesses only publicly available TripAdvisor pages — no authenticated endpoints, paid features, or content behind the tripadvisor.com login wall. Users are responsible for ensuring their use complies with TripAdvisor's Terms of Service, applicable data-protection law (GDPR, CCPA, etc.), and any contractual obligations of their own organization.
SEO Keywords
tripadvisor reviews scraper, tripadvisor scraper, scrape tripadvisor, tripadvisor api, tripadvisor.com scraper, Apify tripadvisor, hotel reviews scraper, restaurant reviews scraper, attraction reviews scraper, tripadvisor hotel data, tripadvisor restaurant data, reviewer profile scraper, review sentiment data, reputation monitoring data, hospitality market research, travel reviews export, tripadvisor json export, tripadvisor csv export, competitive review intelligence, place metadata scraper