Y Combinator Scraper
Pricing
from $10.00 / 1,000 results
Y Combinator Scraper
Extract startup leads, founder emails, LinkedIn profiles, hiring data, and more from YC companies and founders. Export scraped data, schedule via API, and integrate with other tools or AI workflows.
Pricing
from $10.00 / 1,000 results
Rating
5.0
(36)
Developer
Michael G
Maintained by CommunityActor stats
173
Bookmarked
1.5K
Total users
47
Monthly active users
0.34 hours
Issues response
5 days ago
Last modified
Categories
Share
What does Y Combinator Scraper do?
Y Combinator Scraper allows you to extract data about companies and founders from the Y Combinator directory: company name, description, batch, industry, subindustry, status, location, open jobs, website, founder name, founder emails, founder LinkedIn, and more.
About Y Combinator
Y Combinator is the leading startup accelerator for entrepreneurs. Since 2005, YC has invested in over 5,500 companies that have a combined valuation of over $600B, including Airbnb, Dropbox, Stripe, Reddit, Instacart, DoorDash, Apollo, and Coinbase. Today, YC has built the most powerful startup community in the world alongside the products and programs to support founders for the life of their company.
Because of this, the YC directory is one of the best public sources for discovering high-quality startups, founders, and startup hiring data.
Company data fields
| Field Name | Type | Description |
|---|---|---|
| Company Image | String (URL) | Company image URL |
| Company ID | Int | Company id provided by YC |
| Company Name | String | Company name |
| Url | String (URL) | Company profile URL on Y Combinator |
| Short Description | String | One-line company description |
| Long Description | String | Detailed company description |
| Batch | String | Batch name provided by YC |
| Industry | String | Primary industry |
| Sub-Industry | String | Sub-industry |
| Stage | String | Company growth stage |
| Status | String | Company status |
| Tags | List | Additional industry tags |
| Company Location | String | Company location |
| Regions | List | Company operating regions |
| Year Founded | String | Year the company was founded |
| Team Size | String | Number of employees |
| Primary Partner | String | Mentor for a company |
| Top Company | Boolean | YC top company flag |
| Nonprofit | Boolean | Nonprofit status |
| Website | String (URL) | Company website |
| Company LinkedIn | String (URL) | Company LinkedIn profile URL |
| Company X | String (URL) | Company X (Twitter) profile URL |
| Company Facebook | String (URL) | Company Facebook profile URL |
| Company Crunchbase | String (URL) | Company Crunchbase profile URL |
| Company GitHub | String (URL) | Company GitHub profile URL |
| Is Hiring | Boolean | Hiring status (true/false) |
| Number of Open Jobs | Int | Count of open job positions |
Open Jobs data fields
| Field Name | Type | Description |
|---|---|---|
| ID | Int | Job posting id provided by YC |
| Title | String | Job position title |
| Description URL | String (URL) | Detailed job posting URL |
| Description | String | Job requirements and details |
| Location | String | Required job location |
| Remote | Boolean | Remote work availability (true/false) |
| Type | String | Job type |
| Role | String | Job role/department |
| Salary | String | Salary range/compensation |
| Equity | String | Equity compensation range |
| Skills | List | Required skills |
| Years Experience | String | Required experience level |
| Visa | String | Visa requirements |
Founders data fields
| Field Name | Type | Description |
|---|---|---|
| ID | Int | Founder id provided by YC |
| Name | String | Founder name |
| Title | String | Founder title/role |
| Bio | String | Founder biography |
| Email Available | Boolean | Founder email availability (true/false) |
| String | Founder email address | |
| Email Status | String | Founder email status (verified/risky) |
| String (URL) | Founder LinkedIn URL | |
| X | String (URL) | Founder X (Twitter) URL |
Why scrape Y Combinator?
- Lead generation: identifying startups for potential collaboration, partnerships, sales, or investment.
- Founder outreach: collecting founder emails and LinkedIn profiles when available.
- Market research: analyzing trends and popular niches in the startup ecosystem.
- Studying the startup landscape: understanding successful approaches, categories, and business models.
- Recruiting: discovering YC startups that are actively hiring across engineering and product roles.
- Finding inspiration: exploring ideas and innovations that could influence your own project.
Example Input
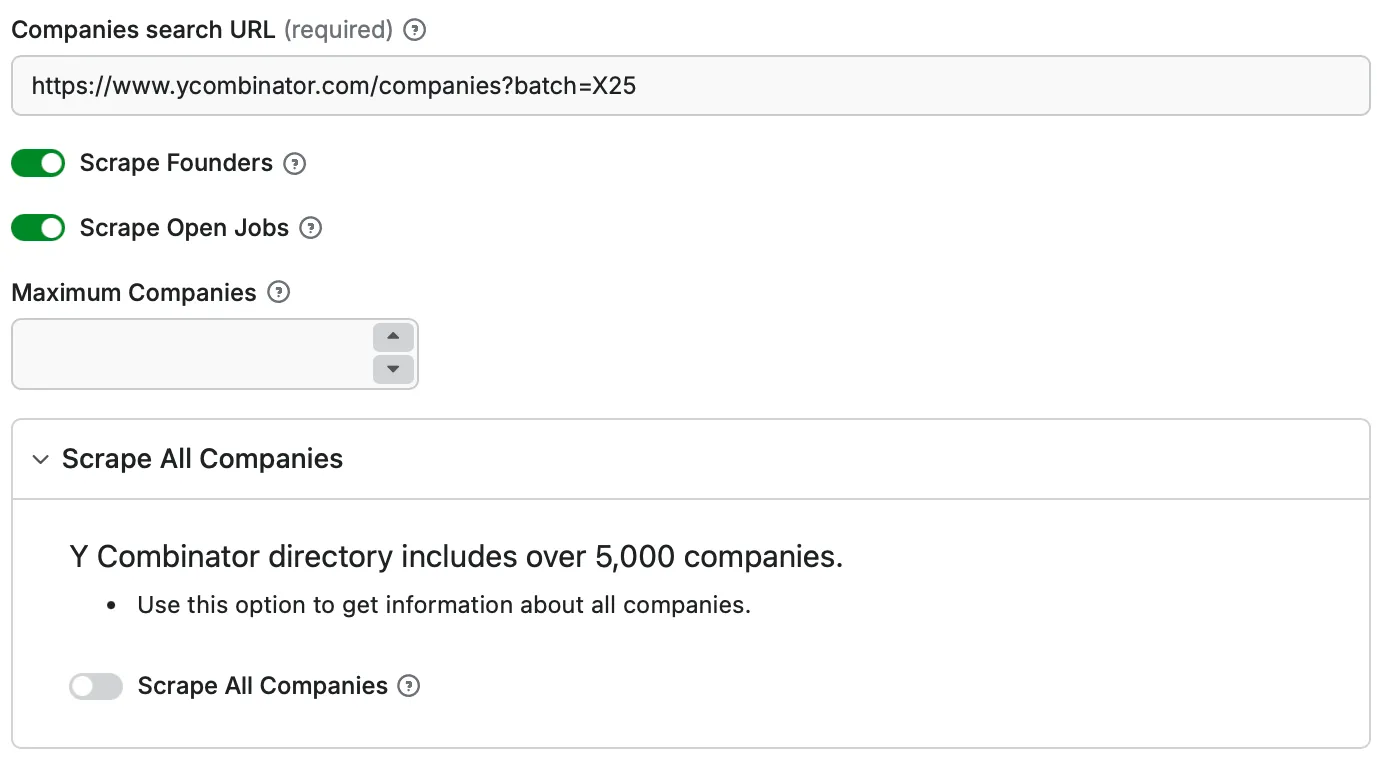
Companies search URL: https://www.ycombinator.com/companies?batch=X25
And here's the same, just in JSON.
Output sample
The results will be wrapped into a dataset which you can find in the Storage tab. Note that the output is organized in a table for viewing convenience. Here's an example of some of the output from the previous companies search URL:
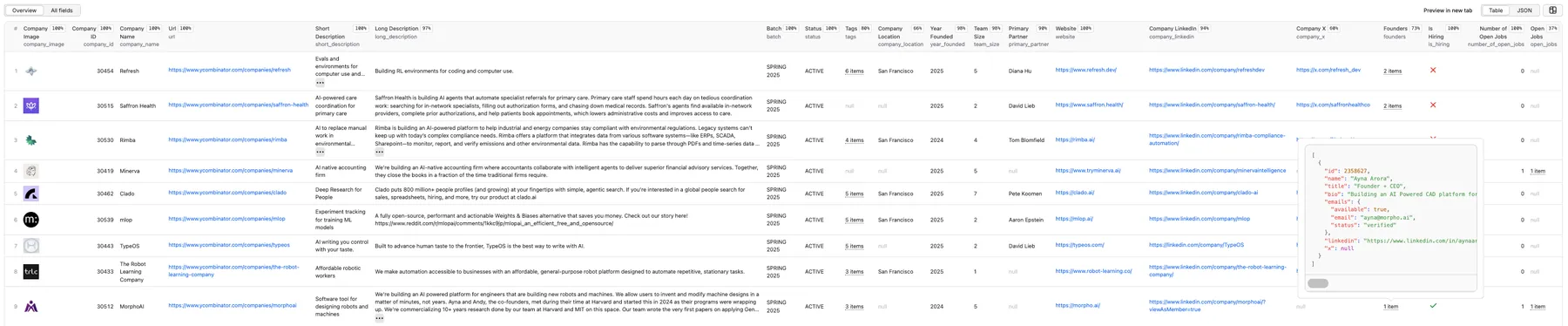
By clicking on the green Export button, you can download the dataset in XML, CSV, Excel, HTML, or JSON. See an example of a JSON file:
How do I use Y Combinator Scraper?
The Y Combinator Scraper is designed to help you easily extract contact details from the web, even if you have no prior experience. Follow these steps to scrape data on Y Combinator companies and their founders:
- Enter Search URL: Copy and paste the Y Combinator directory search URL directly into the scraper's input field.
- Run the Scraper: Click "Start" and wait for the data extraction to complete.
- Export your data in Excel, CSV, JSON, HTML, or via API.
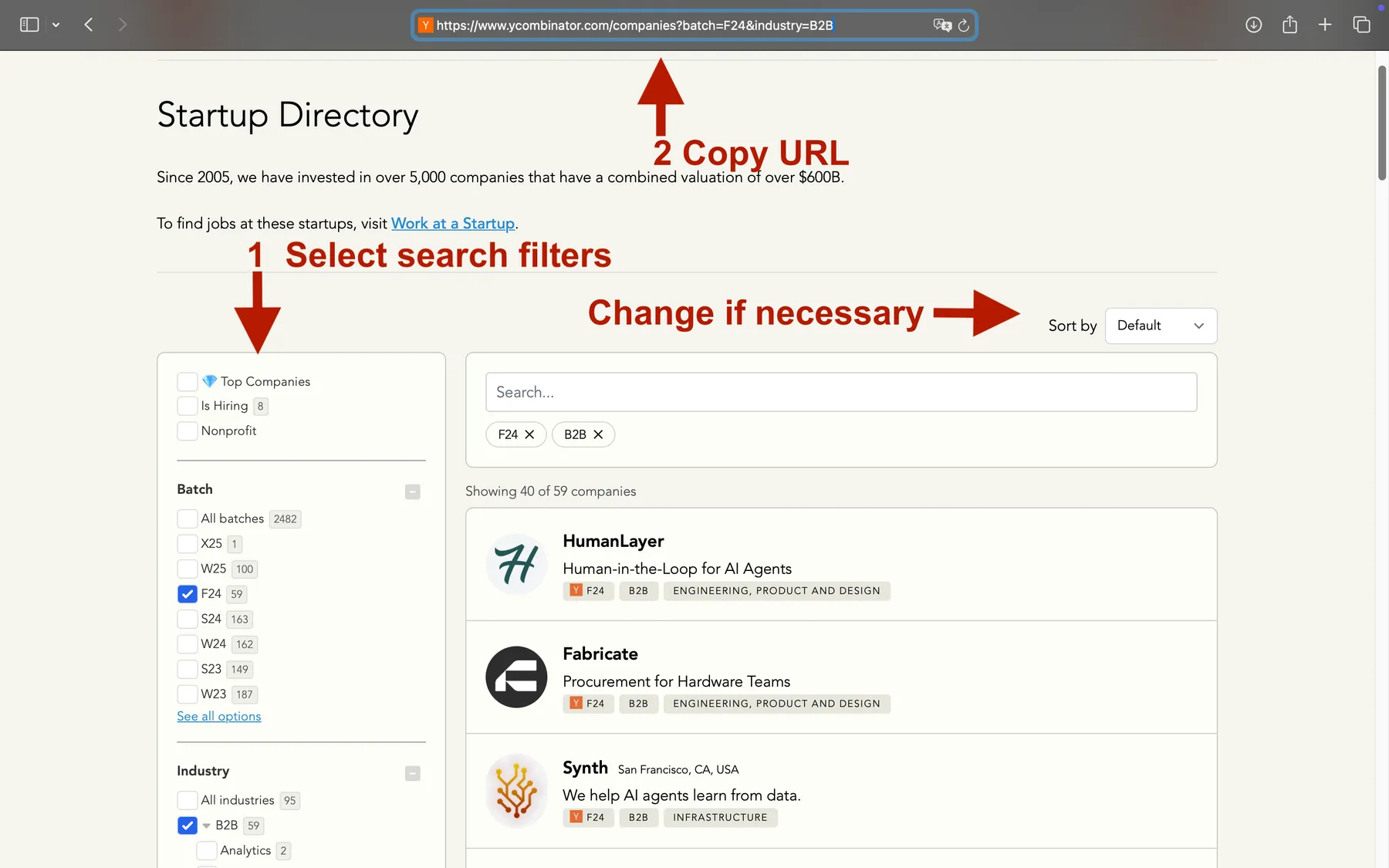
After selecting the necessary filters, the URL address may not update immediately from time to time. Therefore, please double-check it before pasting it into the scraper. Additionally, you can change the "Sort by" option as shown in the screenshot to ensure that the URL address updates promptly based on the filters you have selected.
Features
- Scrape Founders: Enable this option to gather detailed information about all founders from each company.
- Scrape Open Jobs: Set this feature to true if you want to get information about open job positions at the companies.
- Scrape All Companies: Set this feature to true if you want to get information about all companies (over 5,500) from all batches.
How much does Y Combinator Scraper scraping cost?
This scraper uses the Pay-per-result pricing model, so your costs can be easily calculated: it will cost you $15 to scrape 1,000 search results, which is $0.015 per item. Apify provides you with $5 in free usage credits every month on the Apify Free plan, allowing you to scrape over 30 search results from the Y Combinator directory for free using those credits.
For regular data extraction, consider upgrading to the $29/month Starter plan, which can get you over 1,700 search results every month.
Integrations and Y Combinator Scraper
Y Combinator Scraper can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate with Make, n8n, Zapier, Apollo, Clay, Slack, Airbyte, GitHub, Google Sheets, Google Drive, and more.
Your feedback
We're always working on improving the performance of our Actors. If you've got any technical feedback for Y Combinator Scraper or simply found a bug, please create an issue on the actor's Issues tab in Apify Console.