Reddit Subreddits V1 — Info, Browse, Join, Create (12 ops)
Pricing
from $1.99 / 1,000 results
Reddit Subreddits V1 — Info, Browse, Join, Create (12 ops)
Reddit subreddit toolkit — 8 anonymous lookups (info, rules, sidebar, browse, autocomplete, search names, popular feed, post listings) + 4 auth ops (my subreddits, join/leave, post requirements, create new). Use Reddit Vault or paste Token V2 + proxy.
Pricing
from $1.99 / 1,000 results
Rating
5.0
(3)
Developer
Red Crawler
Maintained by CommunityActor stats
3
Bookmarked
14
Total users
5
Monthly active users
2 months ago
Last modified
Categories
Share
Reddit Subreddits — Info, Browse, Join, Create
Twelve self-contained subreddit endpoints — info, rules, full sidebar, browse Reddit's directories, autocomplete, search names, popular feed, post listings, plus the 4 "My account" endpoints that require a signed-in Reddit account (your subscribed / contributed / moderated communities, join / leave, per-subreddit post requirements, create a new subreddit).
Pick the endpoint, fill the matching section, hit Start.
What you can fetch
Subreddit names accept AskReddit, r/AskReddit, /r/AskReddit, or the full subreddit URL — paste whichever you have.
Public endpoints (no Reddit account needed)
1. Subreddit Info — about / metadata
The standard "about" payload Reddit exposes for any community.
Input: subreddit name.
Returns: Reddit ID, fullname, display name (raw + prefixed), title, subscriber count, active user count, public + full description, created timestamp, language, type (public / private / restricted), NSFW flag, quarantine flag, URL, header / icon / banner / community-icon images, primary + key + banner-background colors, submit text, allowed submission types (videos / images / polls / galleries), spoilers-enabled flag, wiki-enabled flag.
Use it when: profiling a community in a single call, sizing audiences, importing a subreddit's settings into your own DB.
Example
Input
Output (one dataset record)
2. Subreddit Rules
The community's posted rules.
Input: subreddit name.
Returns per rule: subreddit, priority, short name, full description, violation reason, kind (link / comment / both), created timestamp.
Use it when: building rule-aware moderation pipelines, posting bots that need to respect each subreddit's rules, compliance audits, content classifiers.
Example
Input
Output (one dataset record per rule)
3. Subreddit Sidebar — full about payload
The full sidebar payload (a richer superset of Subreddit Info — includes the same metadata plus theme, banner styling, public description, submit guidelines, allowed post types, contributor flags, more).
Input: subreddit name.
Returns: complete subreddit settings record. Effectively a one-shot way to mirror a community's identity (theme, branding, posting permissions, allowed content types).
Use it when: theme audits, building branded clones / mirrors, capturing every public knob a subreddit has set.
Example
Input
Output (one dataset record)
4. Browse Subreddits — popular / new / default directory
Reddit's curated directories.
Inputs:
- Directory —
popular(default),new, ordefault. - Limit — 1 to 100 (default 25).
Returns: one Subreddit Info record per community, in the order Reddit ranks them.
Use it when: discovery dashboards, leaderboards (popular vs new vs Reddit's default seed list), competitive audits.
Example
Input
Output (one dataset record per subreddit — sample of the first row)
5. Autocomplete — match names by prefix
Subreddit name suggestions for a prefix string. Returns rich Subreddit Info records, not just names.
Inputs:
- Query — prefix to match (e.g.
ask). - Limit — 1 to 10 (default 10).
- Include NSFW results — off by default. Tick to include NSFW communities.
Returns: up to 10 Subreddit Info records ranked by relevance.
Use it when: building search-as-you-type pickers, validating that a subreddit exists, surfacing "did you mean…" suggestions.
Example
Input
Output (one dataset record per suggestion — sample of the first row)
6. Popular Posts — feed of r/popular
Posts directly from r/popular. Supports sort, time window, and country filter.
Inputs:
- Sort —
hot(default),new,top,rising,best,controversial. - Time filter (optional) —
hour/day/week/month/year/all. Only used withtoporcontroversial. - Country (optional) —
GLOBALor any of 50 country codes (US,GB,CA,AU,DE,FR,JP,IN,BR, etc.). Only used withbestorhot. - Limit — 1 to 100 (default 25).
Returns per post: ID, fullname, title, body, author, subreddit, score, ups, comment count, created timestamp, permalink, URL, domain, flags, flair, thumbnail.
Use it when: trending feeds, geo-targeted listicles ("what's hot in Japan / Germany / Brazil right now"), regional newsfeeds, content syndication.
Example
Input
Output (one dataset record per post — sample of the first row)
7. Search Names — search subreddit names
Free-text search across subreddit names. Returns matching names (string list), faster than autocomplete for "is this name taken" checks.
Inputs:
- Search query — text to match (e.g.
python). - Include NSFW results — off by default.
Returns: one record per matching name.
Use it when: validating availability of a new community name, building a name resolver, surfacing communities matching a topic keyword.
Example
Input
Output (one dataset record per name — sample of the first row)
8. Post Listings — feed of posts from a given subreddit
Pull the post feed for any subreddit. Supports the same sort + time filter as Reddit's own subreddit pages.
Inputs:
- Subreddit — community name (e.g.
Wordpress). - Sort —
hot(default),new,top,rising,controversial. - Time filter (optional) —
hour/day/week/month/year/all. Only used withtoporcontroversial. - Limit — 1 to 100 (default 25).
Returns per post: ID, fullname, title, body / selftext, score, comment count, created timestamp, subreddit, permalink, URL, domain, flags (NSFW, spoiler, locked, stickied), flair, author.
Use it when: mirroring a subreddit's feed, building community dashboards, comparing competing communities, archiving daily top-of-sub posts.
Example
Input
Output (one dataset record per post — sample of the first row)
Account-required endpoints (need a Reddit account)
These need a Reddit Token V2 cookie + the proxy that minted it. Save once in the Reddit Vault and reuse by name, or paste directly per run.
9. My Subreddits — your subscribed / contributed / moderated communities
The signed-in user's communities, scoped to one of four lists.
Inputs:
- Which list —
subscriber(default) /contributor/moderator/streams. - Limit — 1 to 100 (default 25).
- Reddit credentials (saved account or Token V2 + proxy).
Returns per subreddit: the full Subreddit Info record (same shape as endpoint 1) for every community in the chosen list.
Use it when: mirroring your follow graph, auditing what an account moderates, exporting a community list for migration, building per-user dashboards.
Example
Input
Output (one dataset record per subreddit — sample of the first row)
10. Membership — join or leave a subreddit
Subscribe to or unsubscribe from a community on behalf of the signed-in account.
Inputs:
- Action —
joinorleave. - Subreddit — community name (e.g.
Wordpress). - Reddit credentials.
Returns: confirmation record with the action, target subreddit, and Reddit's success response.
Use it when: automated subscription management, bulk join / leave from a list, syncing your follow list with an external system.
Example
Input
Output (one dataset record)
11. Post Requirements — what a subreddit allows in posts
Returns the per-subreddit posting policy: required / blacklisted title strings, body length limits, allowed link domains, gallery rules, guideline text.
Input: subreddit name + Reddit credentials (Reddit requires bearer for this endpoint).
Returns: title rules (regex / required / blacklisted strings, min / max length), body rules (length, required / blacklisted strings, regex, restriction policy), link rules (whitelist / blacklist, repost age), gallery rules (min / max items, caption / URL requirements), flair-required flag, guidelines display policy + text.
Use it when: pre-flighting a post so the submit never gets rejected, auto-fitting titles to per-subreddit rules, building submission helpers / bots.
Example
Input
Output (one dataset record)
12. Create Subreddit — create a new subreddit
Create a brand-new community owned by the signed-in account. Reddit applies the same eligibility checks it shows in the "Create a community" UI (account age, karma minimums, etc.).
Inputs:
- New subreddit name — 3–21 chars, letters / digits / underscores.
- Reddit credentials.
Returns: confirmation record with the new community's name and Reddit's creation response.
Use it when: programmatically spinning up communities (alt brands, regional spinoffs, project-specific subs), bulk-creating sandbox communities for testing.
Example
Input
Output (one dataset record)
Credentials
The 4 account-required endpoints (My Subreddits, Membership, Post Requirements, Create Subreddit) need a Reddit Token V2 cookie + the proxy that minted it. The first 8 endpoints ignore credentials entirely — leave the section blank for those.
Credential lifetime
| Credential | Lifetime | When to refresh |
|---|---|---|
Token V2 (token_v2 cookie) | ~24 hours | Daily — or save a Reddit Session in the Reddit Vault and let the vault auto-refresh the Token V2 from it (recommended). |
Reddit Session (reddit_session cookie) | ~180 days | Only needed if you save an account in the Reddit Vault — the vault uses it to auto-mint fresh Token V2 cookies every ~23 hours. Refresh roughly twice a year. |
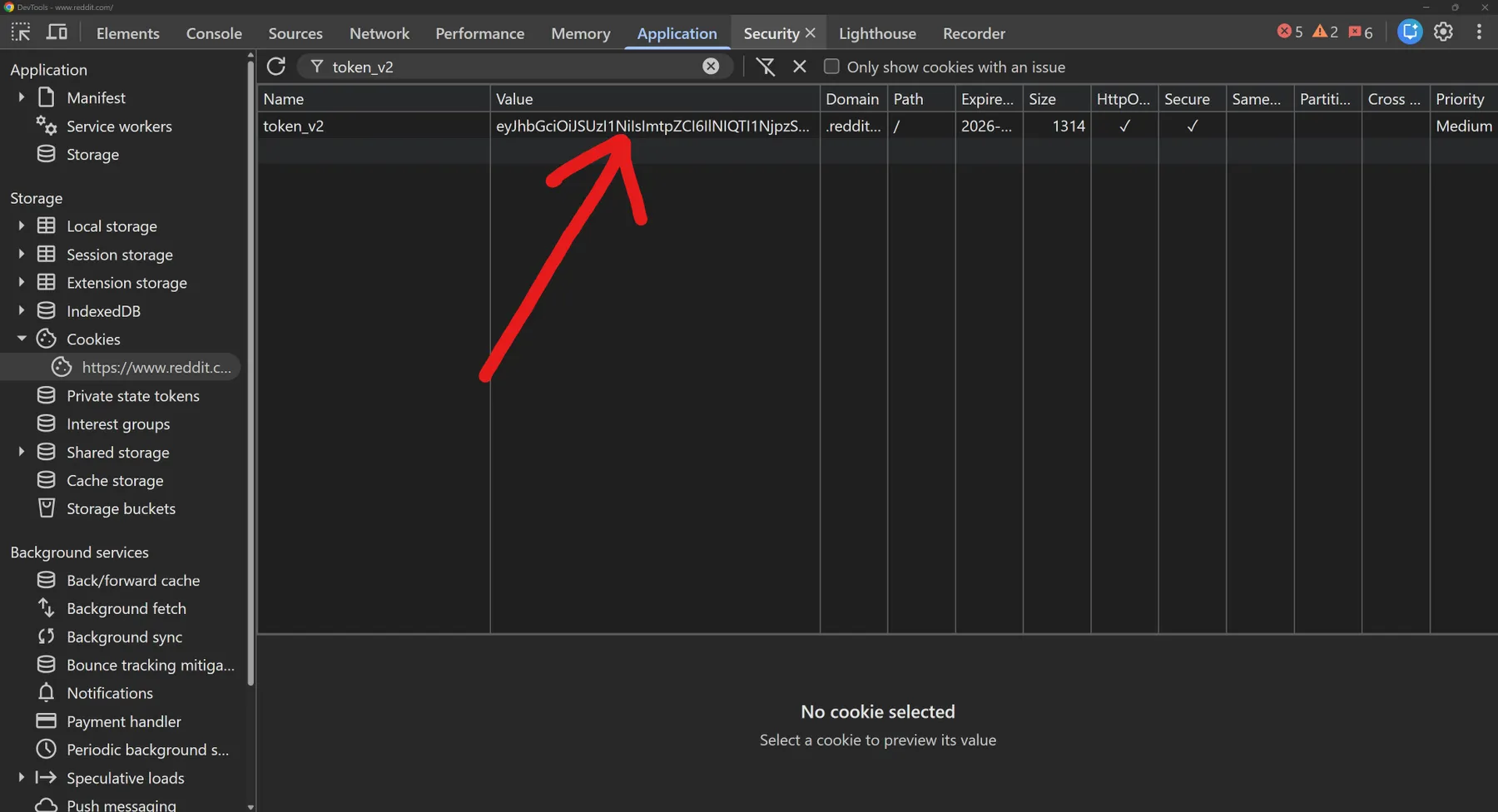
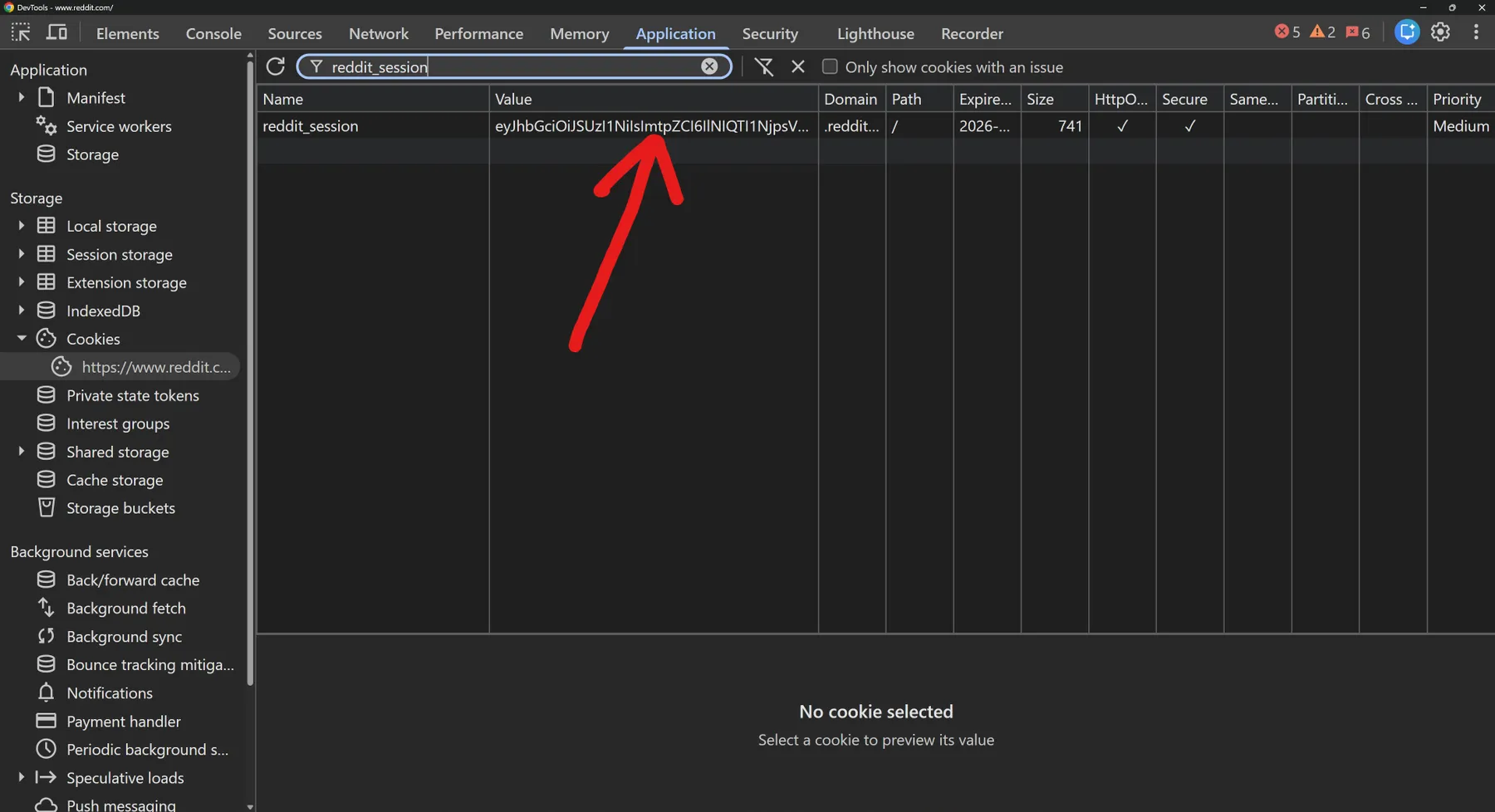
How to extract these from your browser: open Reddit in Chrome / Brave / Edge / Firefox, then DevTools → Application → Cookies →
https://www.reddit.com. Filter bytoken_v2(the Token V2) orreddit_session(the Reddit Session) and copy the Value column.
You have two options:
Option A — Use a saved account (recommended)
- Run the Reddit Vault actor once to store a Reddit account under a name you choose (e.g.
main,alt-account,burner1). The vault encrypts the Token V2 + matching proxy and stores them keyed by name. - In this actor, set Credential source = Use saved account (vault) and put the same name in Saved account name.
- Done — Token V2 + proxy load automatically. Refresh the vault entry whenever the Token V2 expires (~24 h lifetime).
Option B — Paste Token V2 + proxy directly
For one-off runs without setting up the vault:
- Set Credential source = Paste Token V2 + proxy.
- Paste your Reddit
token_v2cookie value (eyJ...) into Token V2. - Paste the matching proxy in
ip:port:user:passformat into Proxy.
Critical: Reddit IP-binds Token V2 cookies. The proxy MUST be the exact same IP that originally minted the Token V2 — otherwise Reddit returns 401 on every account-required call. Both fields are stored encrypted by Apify.
How to run
- Pick an endpoint in the "What to fetch" dropdown at the top. Public endpoints (1–8) are at the top of the list; account-required endpoints (9–12) are grouped at the bottom.
- Open the matching section below it and fill its fields.
- If your endpoint is account-required (9–12), fill the Reddit credentials section at the bottom.
- Click Start.
Each endpoint section is independent — fields outside your chosen section are ignored, so you can leave them as-is between runs. Default endpoint is Subreddit Info on AskReddit, so the actor runs out of the box.
Output
Results are pushed to the actor's default dataset. View them as a table or download as JSON / CSV / Excel / XML.
- Subreddit Info / Subreddit Sidebar / Membership / Post Requirements / Create Subreddit push one record per run.
- Subreddit Rules push one record per rule (typically 5–15).
- Browse / Autocomplete / Search Names / Popular Posts / Post Listings / My Subreddits push one record per item (up to your
limit).
The most useful columns are placed first (endpoint, id, name, display_name, title, subscribers, etc.) so the dataset Table view is readable without horizontal scrolling.
Common edge cases
- Private subreddits — not accessible. Reddit hides their about / rules / sidebar from anonymous calls.
- Quarantined subreddits — return Reddit's quarantine notice rather than full data.
- Banned subreddits — return an error stub.
- Lenient name matching —
AskReddit,r/AskReddit,/r/AskReddit, andhttps://www.reddit.com/r/AskReddit/all resolve to the same community. - Autocomplete / Search Names NSFW filter — by default NSFW results are excluded. Tick
Include NSFW resultsto include them. - Popular Posts country filter — only honored when sort is
bestorhot. With other sorts, Reddit returns the global feed regardless. - Empty results — return zero records. The actor reports an empty result rather than failing.
- Bearer expired — Reddit Token V2 cookies live ~24 h. If you get an
error_kind: bearer_expiredresponse, refresh the Token V2 in your vault entry (or paste a fresh one in manual mode) and re-run. - Create Subreddit eligibility — Reddit enforces account-age and karma minimums; brand-new accounts will get a clear error explaining the missing requirement.
- Membership idempotency — joining a community you're already in, or leaving one you're not, both return success with no state change.
Why this actor is fast
- Speed — 1–3 seconds per call, end-to-end. Pure HTTP to Reddit's API. No browser to boot, no Playwright / Selenium / Puppeteer overhead. Competing browser-based scrapers typically take 15–60 seconds per call.
- Reliability — zero browser flakiness. No headless-Chromium crashes. No JS-render timeouts. No captcha pages. No surprise mid-run failures from a browser quirk.
- Footprint — under 100 MB RAM per run. Most browser-based scrapers need 1–4 GB. Built for reliability behind the scenes — just paste your inputs and run.
Status & error reference
Run status (Apify-side, shown on the run page)
| Status | Apify message | Meaning | What to do |
|---|---|---|---|
| "Actor succeeded with N results in the dataset" | Run finished. Some or zero records pushed. | Open the dataset to view results. | |
| "The Actor process failed…" | Validation error or upstream Reddit fault. | Check the run log. You are NOT charged for failed runs. | |
| "The Actor timed out. You can resurrect it with a longer timeout to continue where you left off." | Run exceeded its timeout. | Re-run with a smaller limit or fewer inputs. | |
| "The Actor process was aborted. You can resurrect it to continue where you left off." | You stopped the run manually. | No charge for unpushed results. |
Common in-run conditions (visible in run log)
| Condition | Cause | Result |
|---|---|---|
| Empty result set | No matching data for the chosen endpoint. | Run SUCCEEDED, 0 records, no charge. |
| Private / quarantined subreddit | Reddit hides these from anonymous reads. | Run SUCCEEDED, those rows skipped. |
| Banned subreddit | Subreddit has been banned by Reddit. | Run SUCCEEDED, 0 records for that input. |
| Bearer expired | Token V2 past ~24 h, no vault session for auto-refresh. | Run SUCCEEDED, failure row with error_kind: bearer_expired. |
Validation error: missing subreddit | Required input not provided. | Run FAILED immediately, no charge. |
Pricing
Pay-per-result. You're only charged for records actually pushed to the dataset — failed runs, validation errors, and empty results cost nothing.
| Event | Trigger | Price (per 1,000) |
|---|---|---|
result | Each subreddit / rule / suggestion / post / membership / requirement record pushed to the dataset | $1.99 |
Need a different shape of data?
- Reddit Users V2 — single-user lookups (profile, trophies, posts, comments) plus your-own-account endpoints
- Reddit Search V2 — search Reddit by query (posts, comments, communities, users)
- Reddit Bulk Scrape V2 — paste up to 1500 IDs / names / URLs in a single run
- Reddit Scraper V2 — single & bulk reads for posts, comments, profiles, communities
- Reddit Posts V1 — front-page feed, crosspost duplicates, pinned posts
- Reddit Wiki, Emojis & Widgets — wiki pages, custom emojis, sidebar widgets
- Reddit Vault — save Reddit accounts once, call them by name from this actor (free)
Support and feedback
Found a bug, want a feature, hit a Reddit error code we don't translate clearly? Open an issue via the actor's Apify Console feedback link, or reach out at the RedCrawler support channel.
Reddit Subreddits is part of the RedCrawler family of Reddit actors. RedCrawler is independent — not affiliated with, endorsed by, or sponsored by Reddit, Inc. Use it within Reddit's API terms.