Competitive Digital Intelligence MCP Server
Pricing
Pay per event + usage
Competitive Digital Intelligence MCP Server
Multi-signal digital competitive analysis intelligence for AI agents via the Model Context Protocol.
Pricing
Pay per event + usage
Rating
0.0
(0)
Developer
Ryan Clinton
Maintained by CommunityActor stats
0
Bookmarked
4
Total users
1
Monthly active users
5.2 days
Issues response
2 months ago
Last modified
Categories
Share
Competitive Digital Intelligence MCP
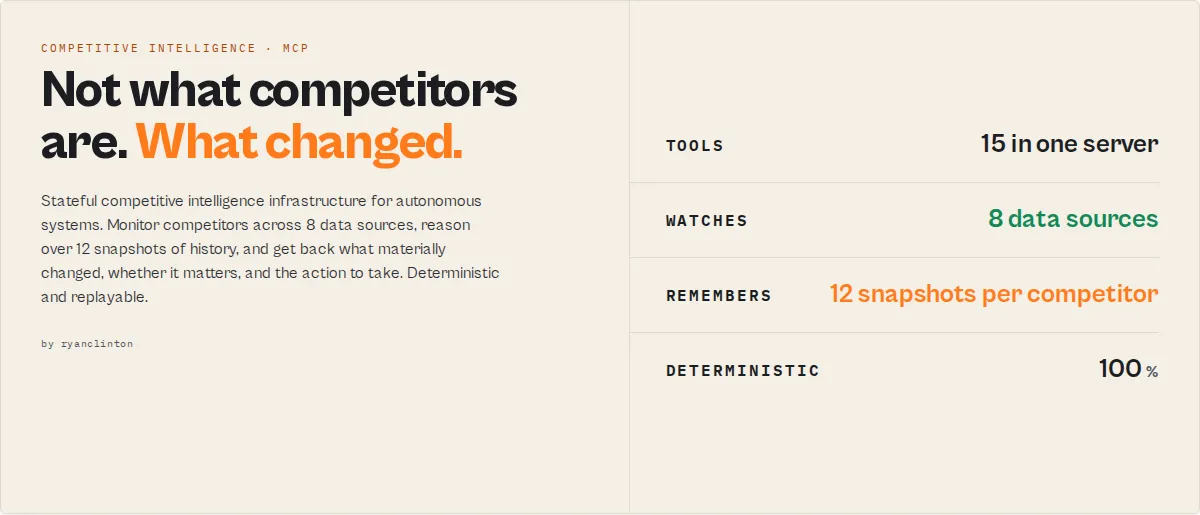
Competitive intelligence infrastructure for autonomous systems.
Monitor competitors, detect market shifts, forecast likely moves, and route only material change into AI workflows. Stateful competitive intelligence built as longitudinal infrastructure rather than a one-shot scraper or a black-box AI analyst.
This is not
- an AI summariser
- a dashboard
- a passive scraper
- a traffic-estimation panel
- a one-shot report generator
- a probabilistic forecaster
It is
- deterministic competitive intelligence infrastructure
- a stateful signal graph over persistent competitor memory
- a category-aware market shift detector
- an MCP-native agent contract
- governance-safe by construction
Most competitor intelligence tooling tells you what existed yesterday. This infrastructure tells autonomous systems what changed, whether it matters, and what action should happen next. No LLM scoring. No prompt drift. Every forecast, narrative, and alert is generated by deterministic rules over typed signals. Same input always produces the same verdict. Replayable months later for governance review.
Used by RevOps, product strategy, agency analysts, sales enablement, founders, market intelligence teams, and AI-agent builders for competitive monitoring, competitor tracking, competitor change detection, market intelligence automation, competitor alerts, market shift detection, SEO monitoring, pricing intelligence, reputation monitoring, longitudinal competitor intelligence, and category monitoring at the infrastructure level.
Common problems this solves
Buyer pains this competitive intelligence infrastructure was built to remove:
- Detect competitor pivots before quarterly planning
- Monitor competitor SEO expansion automatically
- Track pricing pressure across a market category
- Detect market-wide modernisation waves across your portfolio
- Alert only on material competitive change (no cron-tick spam)
- Build autonomous competitive monitoring agents on Claude Desktop / Cursor / Cline
- Route competitor intelligence into Slack, PagerDuty, SIEM, or SOAR
- Track overlap between your keywords and competitor SERP territory
- Detect reputation crises before they impact your sales cycle
- Replace manual weekly competitor sweeps assembled in Notion or Airtable
- Generate competitor battle cards on demand for sales calls
- Forecast a competitor's likely next strategic move deterministically
- Run governance-safe AI automation that compliance can audit
- Replay any historic verdict for regulator review
Which tool should I use?
| If you need... | Use |
|---|---|
| One competitor audit, fully scored | full_competitive_audit |
| Quiet scheduled monitoring (charges only on material change) | continuous_competitor_monitor |
| Category-wide movement across your portfolio | detect_market_shift (free) |
| Forecast of likely next strategic move | forecast_competitor_trajectory |
| Keyword territory overlap with this competitor | territory_overlap_analysis |
| Strategic-pivot check from history alone | detect_competitor_shift (free) |
| Portfolio rollup + priority queue + rebalancing | get_portfolio_intelligence (free) |
| Prior score history for one competitor | competitor_history (free) |
| Targeted single-axis analysis | tech_stack_analysis, seo_ranking_intelligence, ecommerce_competitive_analysis, reputation_monitor, price_intelligence, website_evolution_tracker |
| Side-by-side benchmarking against your domain | compare_competitors |
Teams using this
- RevOps teams monitoring competitive movement and routing alerts into Slack / PagerDuty
- Product strategy teams tracking market shifts and forecasting competitor trajectory
- Sales enablement teams generating battle cards on demand and refreshing them on a cadence
- Agencies automating competitor reporting across client portfolios
- AI-agent builders wiring deterministic competitor signals into autonomous orchestration loops
- Founders pre-launch running competitive landscape scans before naming a product category
- Market intelligence teams replacing manual weekly competitor sweeps and Airtable trackers
- Investors and M&A analysts running digital due diligence on target companies
- Brand managers monitoring reputation and detecting customer-sentiment shifts early
- Compliance and governance teams auditing AI automation that touches market-state decisions
Built for RevOps, strategy, product, sales, and AI-powered research agents that need machine-actionable competitive intelligence, not raw scraped data. Outputs are deterministic, replayable, and route-ready for Slack, Zapier, Make, n8n, Dify, Claude Desktop, Cursor, Cline, and any other MCP-compatible client.
Why this exists
Most competitive intelligence is manual, stale, and answers the wrong question. Analysts open 6 dashboards, export 8 CSVs, normalise by hand, and produce a one-page snapshot that is 48 hours out of date by the time it lands in Slack. Executives and AI agents do not care what competitors ARE. They care:
- What materially changed since last week
- Why does it matter
- What should we do about it
- And is the decision safe enough to automate
This MCP answers those four questions in one call. The scoring is pure functions, the verdicts are stable enums, and the change-detection primitives turn a passive snapshot tool into an early-warning system.
Why deterministic scoring matters
Deterministic = same input always produces the same output. No LLM in the scoring path. No probabilistic models. Every weight and threshold is documented in the methodology MCP resource. Pair this with persistent competitive memory (the signal graph reasons across snapshot history) and you get stateful competitive intelligence: not a point-in-time snapshot, but a longitudinal reasoning system that knows what changed and when.
This is the foundation of every other guarantee in this actor:
- Reproducible audits. A score from 90 days ago can be recomputed today and will match exactly. Replay any historical verdict for governance review.
- Stable automation. Branch your agent on
decision.recommendedActionknowing the enum will not silently shift between identical inputs. - Governance-safe workflows. Compliance teams approve the rule cascade, not the verdict. Approvals stay valid as long as the rules stay stable.
- Explainable agent actions. Every score has a
topContributors[]array quoting the math. Auditors verify by reading the rationale, not by trusting the agent. - No drift from prompt variance. LLM-driven scoring shifts when the prompt changes. This actor's verdict shifts only when the data changes.
- Replayable historical analysis. Snapshot history is meaningful because every snapshot was produced by the same deterministic function as today's run.
When the scoring is a pure function, the operating-system framing earns its name: agents can build long-running infrastructure on top of it without worrying that the foundation will shift under them.
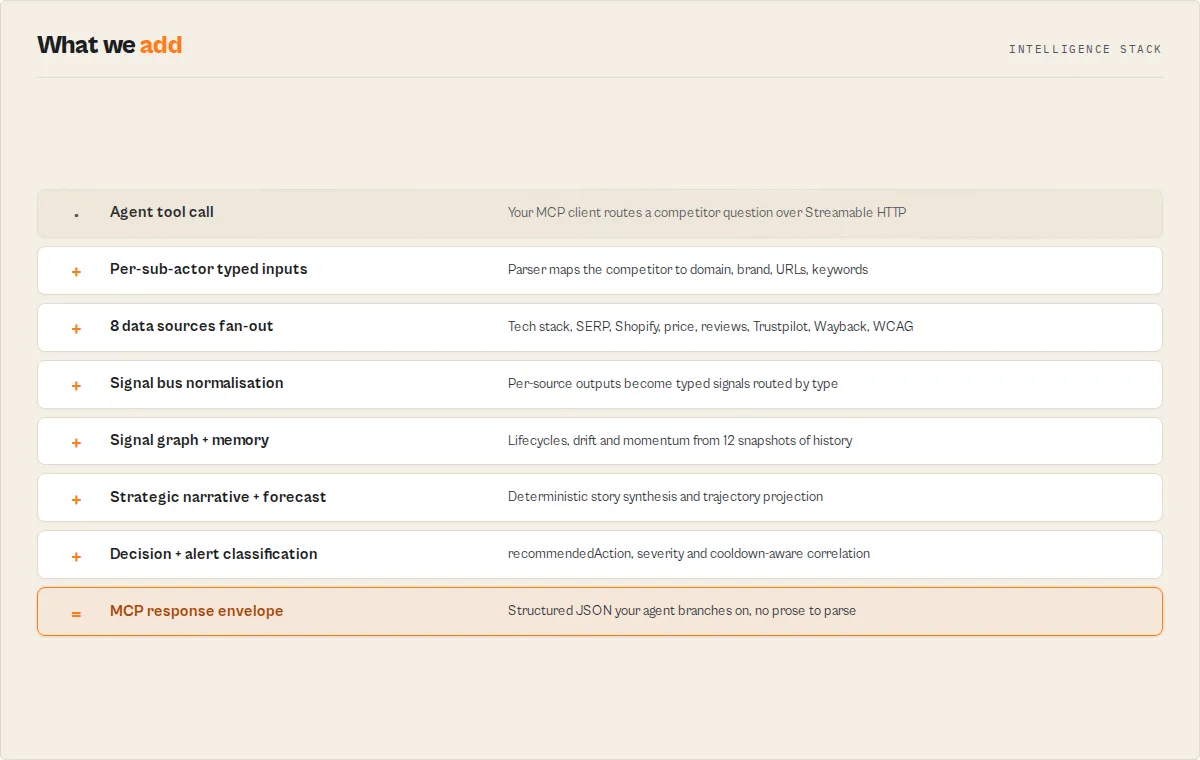
Canonical signal schema
Every sub-actor's output is normalised into a flat stream of typed signals (plain English: every data source's findings become uniform {signalType, severity, direction, confidence} records) before any derivation consumes them. Derivations subscribe to signal types via the bus instead of reading the raw sub-actor shapes. New sub-actors plug in by emitting signals; new derivations plug in by consuming the bus.
Why this matters: every value in the response (archetype, materialChanges, marketEvents, strategicNarrative, alertClassification, scoreExplanation) is derived from the same bus. There is no per-derivation re-parsing of sub-actor output shapes, so a sub-actor swap or a new data source plugs in once and everything downstream benefits.
Signal types
The signal bus exposes 18 stable signal types across the 8 sub-actors. Branch derivations on these, not on raw sub-actor fields.
| Signal type | Source | Meaning |
|---|---|---|
modern_tech_count | website-tech-stack-detector | Count of modern frameworks / runtimes detected |
legacy_tech_count | website-tech-stack-detector | Count of legacy frameworks indicating debt |
cve_risk_count | website-tech-stack-detector | CVE-flagged technologies with highest severity |
tech_diversity | website-tech-stack-detector | Total distinct technology count |
wayback_snapshot_count | wayback-machine-search | Web archive depth (longevity proxy) |
serp_top3_count | serp-rank-tracker | Keywords ranking in top 3 SERP positions |
serp_top10_count | serp-rank-tracker | Keywords ranking in top 10 |
serp_keyword_breadth | serp-rank-tracker | Total keywords with tracked rankings |
wcag_critical_violations | wcag-accessibility-auditor | Critical or serious accessibility violations |
product_count | shopify-store-intelligence | Total product catalog size |
discount_count | ecommerce-price-monitor | Products currently on discount |
shopify_confirmed | shopify-store-intelligence | Boolean — is this a Shopify storefront |
avg_price | ecommerce-price-monitor | Average product price |
trustpilot_rating | trustpilot-review-analyzer | Trustpilot star rating |
trustpilot_review_volume | trustpilot-review-analyzer | Trustpilot review count |
multi_platform_avg_rating | multi-review-analyzer | Cross-platform average rating |
negative_sentiment_share | multi-review-analyzer | Share of reviews tagged negative |
review_theme_cluster | multi-review-analyzer | Detected theme cluster (e.g. "shipping complaints") |
Core concepts
In one line: 11 named primitives form the ontology of this competitive intelligence infrastructure. Skim the names; come back for definitions when a field references one.
Named primitives the response shape and tool descriptions refer back to. Memorise these and every output field becomes legible.
Signal Bus
Per-request normalisation layer (plain English: typed signal stream). Every sub-actor's output is converted into a uniform NormalizedSignal stream so derivations subscribe to signal types rather than re-parsing raw sub-actor shapes.
Signal Graph
Longitudinal competitive memory (plain English: historical-change tracking layer). Reasons across snapshot history to compute lifecycles, narrative evolution, and recurring patterns. The architectural leap that turns this from snapshot intelligence into change intelligence.
Strategic Narrative
Deterministic synthesis of market posture (plain English: named story the competitor is telling). Rule cascade across materialChanges + marketEvents + drift + momentum + archetype. First match wins; same input always produces the same story.
Strategic Memory Graph
Recurring-pattern detection (plain English: "they do X every quarter" inference). Mines snapshot history for narratives that repeat and verdict transitions that cycle. Requires ≥4 snapshots; surfaces dominant historical narrative + occurrence counts.
Trajectory Forecast
Deterministic projection of likely next strategic move (plain English: rule-based next-move prediction). Votes across narrative + momentum + drift + signal lifecycles + material changes. Returns top move + alternatives + horizon days. NOT a probabilistic model.
Pressure Map
Directional competitive pressure by axis (plain English: where they're putting the heat on, and is it rising). Combines score + per-axis velocity + operator-context overlap. Different question than score; different field.
Attention Priority
Single score answering "should I care THIS week?" (plain English: one-number weekly triage). Composes capability + momentum + materialChanges + marketEvents + threat + territory overlap. Score + level enum + structured whyNow rationale.
Material Change
Structured event derived from current vs prior snapshot (plain English: what actually shifted since last run). Carries axis, changeType enum, severity, delta, impactScore, confidence. Drives change-intelligence rather than snapshot-intelligence workflows.
Market Event
Cross-source event heuristic (plain English: replatform / breakout / crisis inferred from multiple sub-actors moving together). Detectability requires snapshot history; surfaces with detectedFrom[] audit chain.
Alert Classification + Correlation
Operational alert metadata + cooldown-aware grouping (plain English: severity routing + cron-tick spam suppression). Severity, operatorImpact, requiresEscalation booleans plus a KV-persisted alert log that classifies alerts as isolated / correlated_burst / persistent_pattern / recovered. Critical severity always fires.
Constellation
Brand-family / parent / subsidiary / sister-brand roll-up (plain English: who's related to whom). Hybrid mode: auto-detects via OpenCorporates + WHOIS + Companies House + Wikipedia, plus accepts caller-supplied relatedDomains[] for known brand families.
Recipes
Starter patterns for common competitive-monitoring workflows. Each combines 1-2 tools + a transport + a config flag.
Monitor 20 competitors and alert only on material change
Tool charges and emits the full payload ONLY when materialChanges is non-empty or the first audit. Cron-tick spam is suppressed by design; PagerDuty / Slack receivers wake up only on alertClassification.requiresEscalation === true.
Detect category-wide SEO acceleration before a paid-search investment
Reads the entity index + all per-entity snapshots; returns a shiftType enum (category_seo_acceleration / category_pricing_war / category_modernization_wave / etc.) when ≥3 entities cross the same axis threshold. Free. KV-only. No upstream fetch.
Forecast a competitor's likely next move before quarterly planning
Deterministic rule cascade across narrative + momentum + drift + signal lifecycles + material changes. Pair with competitor_history (free) to verify the prior trajectory.
Build a sales battle card on demand
Quotes compare_competitors fields verbatim. Designed for paste into Slack or a Notion battle-card template.
Track keyword territory overlap before category expansion
Requires X-Serper-Api-Key header. Run before a paid-search expansion to know where you're competing on shared ground vs unclaimed territory.
Strategic-pivot check across a watchlist
Single-question answer: did they pivot? Drift verdict + dominant-axis change. Route only the strategicShiftDetected: true results to strategy.
30-second use cases
Catching a competitor breakout before quarterly planning
A SaaS company schedules continuous_competitor_monitor weekly across 14 watchlist competitors. For 11 weeks straight, every run returns a suppressed envelope. No charge. No alert. Week 12, one competitor triggers:
PagerDuty wakes the strategy lead before the quarterly planning meeting. They investigate, discover the competitor launched a major enterprise content expansion targeting their exact segment, and ship a counter-strategy in week 13 instead of finding out from a customer in month 4.
That is the difference between snapshot intelligence and signal intelligence.
Weekly Slack alert when a competitor pivots
Schedule continuous_competitor_monitor on a cron. It runs a full audit, persists a snapshot, and stays silent. When materialChanges[] is non-empty (e.g. composite jumped 15 pts, new market event detected, drift in dominant axis), it charges and emits the full payload. Pipe to Slack via Apify webhook. Cron + suppression = no alert fatigue.
Battle-card production for sales calls
Register the competitor_battle_card MCP prompt in Claude Desktop. Ask the agent "build a battle card vs hubspot.com benchmarked against ourdomain.com". The agent quotes competitive.score, strength signals, and opportunity signals from compare_competitors verbatim. 30 seconds, paste-ready.
Strategic-pivot detection on a watchlist of 8 competitors
Schedule detect_competitor_shift (free) on each of your 8 watchlist competitors weekly. It reads persisted snapshots only — no upstream fetch, no charge. Returns strategicShiftDetected: true when their dominant axis flipped (e.g. ecommerce-led to SEO-led). Routes only the positive hits to your strategy channel.
Pre-launch competitive scan
Founder runs full_competitive_audit on 8 potential competitors before naming a product category. The response ranks them, names the strongest (MARKET_LEADER verdict + competitiveArchetype: aggressive_disruptor), and surfaces structural opportunities in strategicExposureGraph (their weakest axes + concrete attack vectors).
Territory overlap analysis before a paid-search investment
Marketing supplies their tracked keyword list and a competitor domain to territory_overlap_analysis. Response shows what % of their keywords the competitor already ranks for, the dominant shared clusters, and their own-only territory. Decide where to invest based on overlap, not on guessing.
Visual lifecycle
The v1.5 architectural shift: a signal graph layer (plain English: historical reasoning infrastructure over persistent competitor memory) sits between the per-call signal bus and the narrative + decision layers. The graph reasons longitudinally over snapshot history to surface lifecycles (signals strengthening or fading), evolution (narratives shifting between runs), recurring patterns ("they do X every quarter"), and forecasts (deterministic projections of the likely next move) that no point-in-time call can compute. This is stateful competitive intelligence by construction — the actor remembers and reasons across time, not just across sources.
In one sentence
Call one MCP tool, get a deterministic 0-100 competitor score across tech stack, SEO, ecommerce, and reputation with structured evidence, strategic archetype, material change detection, persona-tagged signals, agent-actionable decision enums, portfolio-level trend, and (when context supplied) threat-to-us and territory overlap. No LLM in the scoring path. Same input always produces the same verdict.
What you get from one full_competitive_audit call
In one line: five intelligence layers — core decision, signal graph, operator-context, forecasting, trust — plus the stable envelope. Agents subscribe to whichever layer matters for their prompt.
Every successful response carries five layers of intelligence plus the stable envelope. Layers are independent — agents can subscribe to whichever ones they need.
Core decision payload
- Composite score 0-100 + verdict enum (MARKET_LEADER, STRONG, ESTABLISHED, EMERGING, WEAK_COMPETITOR)
competitiveArchetype— 11-value enum (aggressive_disruptor, legacy_incumbent, seo_dominant, reputation_fragile, pricing_aggressive, stagnant_player, fast_follower, enterprise_trusted, growth_accelerating, technically_decaying, underspecified) with confidence + rationale- Per-dimension breakdown for tech, SEO, ecommerce, reputation
evidence[]— every finding carries source attribution, record type, count, category, audience tag, polarityrecommendations[]— audience-tagged opportunitiesnarrative— one-sentence deterministic prose (Slack-paste-ready)decisionprimitives withrecommendedActionenum (deep_research / strategy_review / monitor_weekly / monitor_monthly / no_action),monitoringPriority,urgency,rationaleagentInstructions—safeToAutoApprove,requiresHumanEscalation,nextBestAction,prerequisitesForAutonomyoperationalReadiness— automationSafe boolean + confidence band + blocking conditionsstateNarrative— operational impact + primary driverplaybook— ordered owner-tagged steps with hour estimates for the recommendedActiontopContributors— ranked dimensions with contributedPointsexposureMap— 0-1 normalised per-dimension heatmapstrategicExposureGraph— weakest axes ranked + concrete attack vector per axis
Signal graph intelligence (longitudinal reasoning over snapshot history)
signalLifecycles— per-signal phase enum (emerging / strengthening / persistent / decaying / resolved / absent) + durationDays + amplification + stabilitymaterialChanges[]— structured change events vs prior snapshot (composite_jump, verdict_escalation, dimension expansion / contraction, sentiment_swing, etc.)marketEvents[]— cross-source event heuristics (major_site_replatform, seo_breakout, reputation_crisis, tech_modernization, ecommerce_expansion)strategicNarrative— deterministic story synthesis (enterprise_expansion / aggressive_growth / market_pivot / price_war / defensive_modernization / consolidation / decline / breakout / crisis / stable_growth / no_dominant_narrative) with confidence and supportingSignalsnarrativeEvolution— current vs previous narrative + durationDays + transition enum (first_audit / unchanged / reaccelerated / reversed / shifted)strategicMemoryGraph— recurring patterns inferred from snapshot history (≥4 snapshots required); dominant historical narrative + occurrence countsvelocity— pointsPerDay, acceleration, days-until-MARKET_LEADER, days-until-WEAKmomentum— direction + strength + stability + confidence + basistrend— score delta, direction, volatility (from snapshot history)drift— dimension-rank shift since first snapshotpressureMap— per-axis pressure level (no / low / moderate / high / extreme_pressure) + direction (increasing / stable / decreasing)attentionPriority— one 0-100 score answering "should I look at this competitor THIS week?" with level enum (critical / high / moderate / low) and whyNow rationale arrayincidentTimeline— chronological events from snapshot history (verdict changes + composite jumps)portfolioBenchmark— percentile vs your own audited portfolio when ≥3 entities tracked. Renamed fromindustryBenchmarkin v1.4 to avoid implying market-wide cohort intelligence we do not have.
Operator-context intelligence (only when ourDomain / ourKeywords / ourVertical supplied)
threatAssessment— threat-to-us index amplified by operator-context overlapterritoryOverlap— keyword-set overlap with ourKeywords + dominant shared clustersconstellationAggregate— hybrid brand-family roll-up. Auto-detects parent / subsidiary / sister / acquired brands by fanning out to OpenCorporates (200M+ global companies), WHOIS / RDAP (registrant org), UK Companies House (UK registry), and Wikipedia (parent / subsidiary / acquired-by infobox fields). Caller-suppliedrelatedDomains[]adds known brand families the auto-detect might miss. Mode enum reports which path produced each member.
Forecasting and simulation
trajectoryForecast— deterministic projection of likely next move (enterprise_content_expansion / aggressive_seo_push / pricing_war / tech_replatform / reputation_recovery_campaign / product_catalog_expansion / monetisation_shift / market_exit_or_decline / continued_breakout / sustained_growth / unclear) with confidence + horizon days + alternatives + supporting signals. NOT a probabilistic model.exposureSimulation— counterfactual scoring under hypothetical dimension changes. Caller-supplied scenarios viaexposureScenariosparam, or 4 default "what if they fully recover on each axis" scenariosseoDependenceRisk— ranking concentration riskreputationFragility— low review count + strong rating instabilitytechnologyRiskHorizon— modernization pressure (imminent / 12_months / 24_months / low)
Trust and governance
dimensionConfidenceper axis — share of expected sources that returned datadimensionVolatilityper axis — score swing across snapshot historyreviewThemes[]— theme clusters surfaced from multi-review-analyzer via signal bustrustLayer— whyThisScore, whichSourcesMattered, whichSourcesFailed, whatChangedscoreExplanation— largestPositive/Negative drivers + unstable signals + high-variance signalsalertClassification— severity + operatorImpact + requiresEscalation booleans for routing into SIEM, SOAR, Slack, PagerDutyalertCorrelation— cooldown-aware suppression + group classification (isolated / correlated_burst / persistent_pattern / recovered) so scheduled monitoring loops don't spam the same alert every cron tick. Critical severity always fires.
Plus the stable envelope on every response: schemaVersion, actorVersion, recordType, captureTimestamp, contentHash, runSummary, dataSourceErrors.
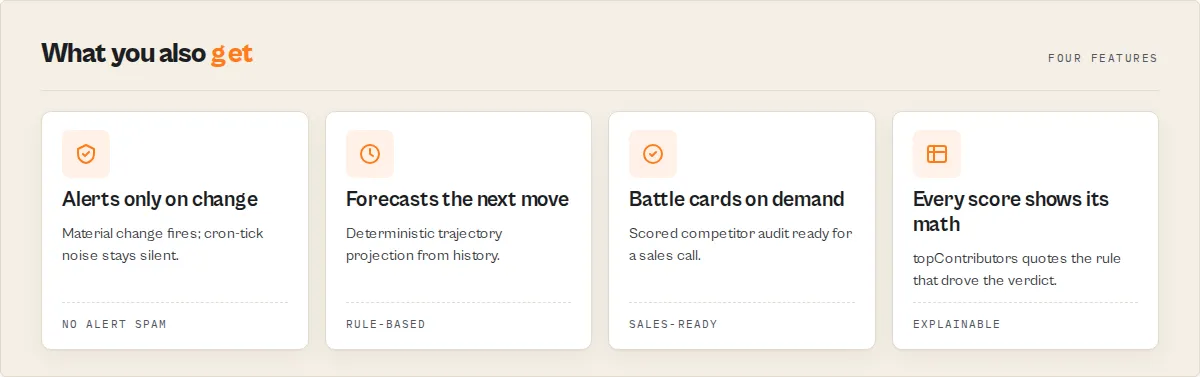
What makes this different
- Deterministic scoring. Same input always produces the same verdict. No LLM in the scoring path. Auditable formulas exposed via the
methodologyMCP resource. Built as competitive intelligence infrastructure, not a probabilistic AI summariser. - Competitive signal intelligence, not just point-in-time audits. Snapshots become structured material changes, market events, narrative evolution, drift, momentum, lifecycles. The result is competitor change detection as first-class infrastructure rather than an afterthought.
- Category intelligence, not just per-competitor scoring.
detect_market_shiftreads the entire audited portfolio and surfaces category-wide moves (SEO acceleration, modernisation wave, pricing war) when ≥3 entities cross the same threshold. Built for market intelligence teams as well as single-competitor sales prep. - Decision primitives, not just scores. Branch your agent on
decision.recommendedAction(5-value enum) andagentInstructions.safeToAutoApprove(single boolean). Skip parsing prose. Designed for AI competitor monitoring loops, not human dashboards. - Free portfolio and memory tools.
competitor_history,get_portfolio_intelligence,detect_competitor_shift,detect_market_shiftcost nothing per call. Track 20 competitors weekly without paying per query. Continuous competitive monitoring at zero marginal cost.
Alternative to
Use this competitive intelligence infrastructure in place of, or alongside:
- Semrush competitor monitoring ($120 / month) for SERP keyword tracking on a defined competitor set
- SimilarWeb Pro competitor tracking ($167 / month) for competitor digital posture overviews
- BuiltWith technology monitoring ($295 / month) for tech stack detection and change tracking
- Klue battle cards (enterprise-priced) for sales-enablement competitive content
- Crayon competitor alerts (enterprise-priced) for change-detection-style competitive intelligence
- VisualPing website monitoring (low-cost) for raw page-change detection without scoring or routing
- Wappalyzer tech-stack monitoring for one-off lookups (no longitudinal reasoning)
- Google Alerts for competitor news (no structured output, no routing primitives)
- Manual competitor research pipelines assembled by analysts in Notion / Airtable / spreadsheets
- Custom Python pipelines stitching together 6 scraper outputs with hand-rolled normalisation
- Internal competitive intelligence teams running weekly sweeps that arrive 48 hours stale
This MCP is built as competitive intelligence infrastructure. Pricing is pay-per-event ($0.06-$0.25 per call); free tier on Apify covers most light use; deterministic scoring lets enterprises audit and replay every verdict; AI-agent native via Streamable HTTP MCP transport.
Quick answers
Does this work with Claude Desktop / Cursor / Cline? Yes. StreamableHTTP MCP transport.
Does this work with Zapier / Make / n8n / Dify? Yes. Pass workflowProfile: 'zapier' | 'make' | 'dify' on any tool. The response is reshaped on the way out.
Is the scoring deterministic? Yes. Pure functions, no LLM, no probabilistic models. The competitive-intel://methodology/scoring MCP resource exposes every weight and threshold.
Do I get charged when sources fail? No. Tools resolve data first, then charge. noData envelope if all sources return empty. No charge.
Do I get charged for history / portfolio / pivot queries? No. competitor_history, get_portfolio_intelligence, and detect_competitor_shift are free.
What if I only want to be alerted on material change? Use continuous_competitor_monitor, or pass materialChangesOnly: true to full_competitive_audit. Both suppress when nothing material changed, and continuous_competitor_monitor also skips the PPE charge on suppressed runs.
What if I want to know how dangerous they are to ME specifically? Pass ourDomain, ourKeywords, and/or ourVertical to full_competitive_audit. The response includes a threatAssessment block scaled by overlap with your context.
What if I want to know what keyword territory we share? Use territory_overlap_analysis with your ourKeywords list. Returns overlap percent, shared keyword sample, your-only territory, and dominant shared clusters.
Does this need any API keys? Two, both free. Pass them as HTTP headers in your MCP client config (NOT as env vars on the actor). X-Serper-Api-Key (free 2,500 queries / month at https://serper.dev) unlocks SEO ranking, territory overlap, and the Google reviews source. X-UK-Companies-House-Api-Key (free at https://developer.company-information.service.gov.uk/) unlocks the UK Companies House source inside constellation auto-detect (other constellation sources still run without it). Headers are read per request; every customer brings their own keys; the actor never reuses a key across customers.
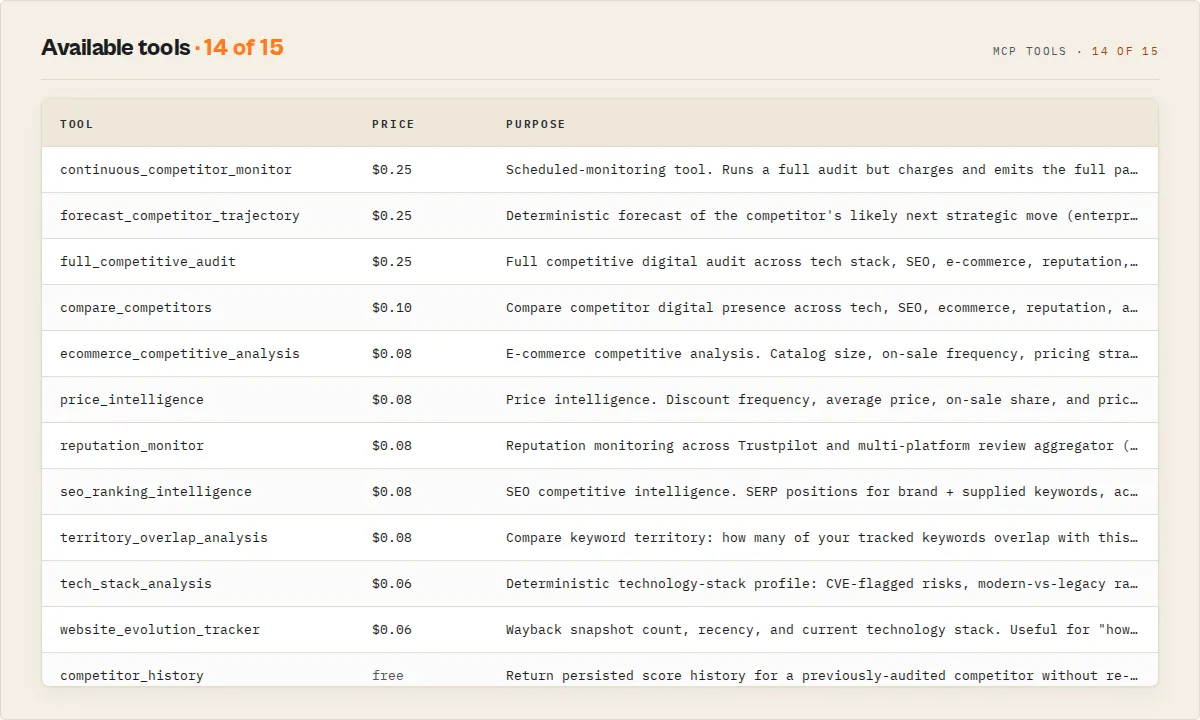
Tools
Fifteen tools total. Nine paid composite / targeted / forecast / monitor analyses, two paid mode-shifted (monitor + territory), four free memory accessors (history, portfolio, market shift, pivot detection). Every tool accepts mode (fast / accurate / audit) and workflowProfile (raw / zapier / make / dify).
| Tool | Price | Sources | Description |
|---|---|---|---|
full_competitive_audit | $0.25 | All 8 | Composite audit with full v1.5 payload (5 intelligence layers: core decision + signal graph + operator-context + forecasting + trust). Includes archetype, materialChanges, marketEvents, drift, momentum, scoreExplanation, signalLifecycles, narrativeEvolution, strategicMemoryGraph, pressureMap, attentionPriority, exposureSimulation, trajectoryForecast, constellation auto-detect, threat + territory + portfolioBenchmark when relevant context supplied. |
continuous_competitor_monitor | $0.25 (only on event) | All 8 | Scheduled monitoring. Persists snapshot every call. Charges + emits full payload ONLY when materialChanges is non-empty or this is the first audit. Event payload includes alertClassification (severity / operatorImpact / requiresEscalation) and strategicNarrative (deterministic story synthesis). No-event runs are free. |
tech_stack_analysis | $0.06 | Tech Stack + Wayback | Tech sophistication score, CVE-flagged risks, modern-vs-legacy ratio |
seo_ranking_intelligence | $0.08 | SERP + WCAG | SERP positions plus accessibility-as-SEO impact |
ecommerce_competitive_analysis | $0.08 | Shopify + Price Monitor | Catalog size, discount frequency, ecommerce maturity |
reputation_monitor | $0.08 | Multi-Review + Trustpilot | Cross-platform sentiment, reputation grade, divergence |
price_intelligence | $0.08 | Price Monitor + Shopify | Discount frequency, average price, pricing strategy |
website_evolution_tracker | $0.06 | Wayback + Tech Stack | Snapshot count + current tech stack |
compare_competitors | $0.10 | 5 sources | Benchmarking summary with optional side-by-side delta against your domain |
territory_overlap_analysis | $0.08 | SERP only | Caller supplies keywords; returns overlap with competitor's rankings + dominant shared clusters |
competitor_history | Free | KV store | Persisted score history. No upstream fetch. |
detect_competitor_shift | Free | KV store | Did they strategically pivot? Reads snapshot history, returns drift verdict + dominant-axis change. |
get_portfolio_intelligence | Free | KV store | Portfolio rollup, priority queue, rebalancing hints across every previously-audited competitor. |
detect_market_shift | Free | KV store | Category-wide shift detection. Reads snapshot history across the entire portfolio, returns shiftType enum (category_seo_acceleration / category_pricing_war / category_modernization_wave / category_reputation_pressure / category_catalog_expansion / category_consolidation / mixed_signals / no_shift_detected) when ≥3 entities cross the same axis threshold. KV-only. |
forecast_competitor_trajectory | $0.25 | All 8 | Deterministic projection of the competitor's likely next strategic move via rule cascade over narrative + momentum + drift + signal lifecycles + material changes. Returns top move + alternatives + horizon days + supporting signals. Deterministic, not probabilistic. |
How to connect this MCP server
Claude Desktop
Configure the MCP server with your Apify token AND your free Serper / Companies House keys as HTTP headers. The MCP forwards each key to the matching sub-actor on a per-request basis — every customer brings their own keys; the actor never reuses a key across customers.
X-Serper-Api-Key unlocks seo_ranking_intelligence, territory_overlap_analysis, and the Google reviews source inside reputation_monitor. Get a free key (2,500 queries / month free tier) at https://serper.dev.
X-UK-Companies-House-Api-Key unlocks the UK Companies House source inside the constellation auto-detect path. The other constellation sources (OpenCorporates, WHOIS, Wikipedia) run without this key. Get a free key at https://developer.company-information.service.gov.uk/.
Cursor / Windsurf / Cline
Same header block as Claude Desktop. Each IDE's MCP configuration panel supports a headers map.
Zapier / Make / n8n / Dify
Pass workflowProfile in the tool arguments:
zapierflattens nested keys with_, stringifies arrays of objects, nulls to empty strings.makeflattens with., stringifies arrays of objects, preserves nulls.difyprojects decision-ready top-level fields (compositeScore,verdict,narrative,decision_recommendedAction,decision_monitoringPriority, etc.) so if/else nodes branch on a single key.
Programmatic HTTP
API keys (customer-supplied HTTP headers)
Sub-actor API keys travel as request headers, not as env vars or actor input. Each MCP client config carries the keys; the actor reads them per request and forwards each to the matching sub-actor. This is the canonical pattern documented at docs.apify.com/platform/integrations/mcp. Customers bring their own keys; the actor never reuses a key across customers.
| Header | Required for | How to get it |
|---|---|---|
Authorization: Bearer <APIFY_TOKEN> | All tool calls | Your Apify token from console.apify.com. |
X-Serper-Api-Key | seo_ranking_intelligence, territory_overlap_analysis, Google reviews source inside reputation_monitor | Free at https://serper.dev (2,500 queries / month free tier). |
X-UK-Companies-House-Api-Key | Optional. Unlocks UK Companies House inside the constellation auto-detect path. Other constellation sources (OpenCorporates, WHOIS, Wikipedia) run without it. | Free at https://developer.company-information.service.gov.uk/. |
When a required header is missing, the affected tool returns a structured { isError: true, failureType: 'missing-credential', message: '<which header to set, where to get the key>' }. Other tools that don't need that key continue working.
Environment variables
| Variable | Purpose |
|---|---|
STANDBY_IDLE_TIMEOUT_SECS | Optional. Default 300. Seconds of inactivity before standby exits to release platform compute. Next request cold-starts a fresh instance transparently. |
SERPER_API_KEY | DEV fallback only. Used by local ms actor serve and single-tenant deploys when no X-Serper-Api-Key header is supplied. Header always wins. |
UK_COMPANIES_HOUSE_API_KEY | DEV fallback only. Same role as above for the Companies House sub-actor. |
Tool parameters
full_competitive_audit
| Parameter | Type | Required | Description |
|---|---|---|---|
competitor | string | yes | Competitor domain or brand name |
industry | string | no | Industry context (echoed back, not scored) |
ourDomain | string | no | Your domain. Pair with ourVertical / ourKeywords to enable threat assessment. |
ourKeywords | string[] | no | Your tracked keywords. Enables territoryOverlap block. Max 100. |
ourVertical | string | no | Your vertical / industry. Amplifies threat-to-us scoring. |
relatedDomains | string[] | no | Brand-family / sister-brand / acquired domains the operator already knows about. Enables constellationAggregate roll-up. Max 20. |
exposureScenarios | object[] | no | Caller-supplied counterfactual scenarios [{ axis, hypotheticalScore }]. Max 8. When omitted, the actor runs 4 default "what if they recover on each axis" scenarios. |
materialChangesOnly | boolean | no | When true, return noData envelope without charging when nothing material changed vs prior snapshot. |
mode | enum | no | fast / accurate (default) / audit |
workflowProfile | enum | no | raw (default) / zapier / make / dify |
continuous_competitor_monitor
| Parameter | Type | Required | Description |
|---|---|---|---|
competitor | string | yes | Competitor domain or brand name |
ourDomain | string | no | For threat assessment in event payload |
ourKeywords | string[] | no | For threat assessment |
ourVertical | string | no | For threat assessment |
mode | enum | no | fast / accurate / audit |
workflowProfile | enum | no | raw / zapier / make / dify |
Charges and emits the full payload ONLY when materialChanges is non-empty OR this is the first audit on this competitor. Suppressed runs still persist a snapshot (so trend math stays accurate) but skip the PPE charge.
detect_competitor_shift
| Parameter | Type | Required | Description |
|---|---|---|---|
competitor | string | yes | Competitor previously audited by full_competitive_audit |
lookbackDays | integer 7-365 | no | Limit drift analysis to snapshots within this many days |
workflowProfile | enum | no | raw / zapier / make / dify |
Free. Requires at least 2 prior snapshots; returns noData envelope with reason if insufficient history.
territory_overlap_analysis
| Parameter | Type | Required | Description |
|---|---|---|---|
competitor | string | yes | Competitor domain |
ourKeywords | string[] | yes | Your tracked keywords. Min 1, max 200. |
workflowProfile | enum | no | raw / zapier / make / dify |
Requires X-Serper-Api-Key request header.
compare_competitors
| Parameter | Type | Required | Description |
|---|---|---|---|
competitor | string | yes | Competitor to analyse |
benchmark | string | no | Your domain for side-by-side delta |
mode / workflowProfile | enum | no | Same as other tools |
forecast_competitor_trajectory
| Parameter | Type | Required | Description |
|---|---|---|---|
competitor | string | yes | Competitor domain or brand |
mode | enum | no | fast / accurate (default) / audit |
workflowProfile | enum | no | raw / zapier / make / dify |
Why both forecast_competitor_trajectory and full_competitive_audit contain a trajectory forecast. The audit ships the forecast as one field in a 5-layer composite payload — useful when the agent is gathering complete context. The dedicated forecast tool answers the specific question "what's the likely next move?" with the forecast as the headline response (less to parse, designed for if/else routing). Same scoring engine, same deterministic rules, different response shape and discovery surface in tools/list.
detect_market_shift
| Parameter | Type | Required | Description |
|---|---|---|---|
workflowProfile | enum | no | raw / zapier / make / dify |
Free. Reads only from KV (entity index + snapshot history per indexed entity). Requires ≥3 entities indexed for meaningful output.
Other tools
tech_stack_analysis, seo_ranking_intelligence, ecommerce_competitive_analysis, reputation_monitor, price_intelligence, website_evolution_tracker each take their primary input string (domain / competitor / brand / product) plus optional mode and workflowProfile.
competitor_history, get_portfolio_intelligence, detect_competitor_shift, detect_market_shift are free KV-only tools.
Operational modes
Pass mode on any tool to trade coverage vs latency. Composite weights are unchanged across modes; mode only controls which sources are called.
fastskips Wayback and WCAG on composite tools. Roughly half the wall-clock time.accurate(default) calls every source the tool needs.auditcalls every source plus attachesperSourceMsandperSourceItemCounttorunSummaryfor diagnostic visibility.
Workflow profiles
raw(default) returns the full nested envelope unchanged.zapierflattens nested keys with_, stringifies arrays of objects, converts nulls to empty strings.makeflattens with., stringifies arrays of objects, preserves nulls.difyprojects decision-ready fields to top-level for if/else branching.
Response envelope
Every successful response carries the same envelope:
| Field | Description |
|---|---|
schemaVersion | Stable enum. Bumps on breaking shape changes. Current: 2.3 |
actorVersion | Bumps on any deploy. Current: 1.5.0 |
recordType | Per-tool stable enum (full_competitive_audit, portfolio_intelligence, competitor_shift, territory_overlap, tech_stack_analysis_no_data, seo_ranking_intelligence_error, etc.) |
captureTimestamp | ISO 8601. Excluded from contentHash. |
schemaMode | Always strict in this version |
contentHash | sha256:<16-char-hex> of the payload. Stable across runs producing identical results. Use for dedup. |
runSummary | Per-tool telemetry: mode, workflowProfile, elapsedMs, sourcesAttempted, sourcesReturnedData, sourcesFailed, sourcesSkipped |
dataSourceErrors | Present when any source failed or was skipped. |
MCP resources
Three resources registered so agents can inspect methodology and contracts before any paid call.
competitive-intel://methodology/scoring— per-dimension formulas, weights, and verdict thresholds. Confirms deterministic + no-LLM scoring.competitive-intel://coverage/source-map— sub-actor source name to canonical upstream URL.competitive-intel://schemas/decision-contract— enum surface for every decision-relevant output field (verdict, recommendedAction, monitoringPriority, urgency, velocity direction / acceleration, narrative dominantAxis, materiality, mode, workflowProfile, signal types).
MCP prompts
Three canonical instruction templates AI agents can invoke directly.
weekly_competitor_brief— callsfull_competitive_audit, composes a 4-bullet Slack brief quoting fields verbatim.competitor_battle_card— callscompare_competitorswith a benchmark domain, builds a 3-section battle card.portfolio_strategy_review— callsget_portfolio_intelligence, composes a strategist brief.
AI-agent-friendly design
In one line: designed as an MCP-native agent contract — stable enums, deterministic branching, governance-safe long-running loops, customer-supplied keys per request.
Built for AI agents and autonomous orchestration loops, not human dashboards. Specifically optimised for:
- Tool discovery via
tools/list— 15 tools registered, each with a description that names the use case in the first sentence so LLMs match user prompts to the right tool deterministically. - Deterministic enum routing — every decision-shaped field (
verdict,recommendedAction,monitoringPriority,urgency,velocity.direction,momentum.strength,narrative.story,archetype,alertClassification.severity,trajectoryForecast.likelyNextMove) is a stable string enum. Agents branch on the enum value; the enum surface is published in thecompetitive-intel://schemas/decision-contractMCP resource. - Workflow branching —
workflowProfile: difyprojects decision-ready fields to top level so if/else nodes branch on a single key. - Autonomous monitoring loops —
continuous_competitor_monitorcharges and emits ONLY on material change so cron-tick spam is suppressed by design. Long-running agents can poll without burning credit. - Slack / SIEM / SOAR / PagerDuty routing —
alertClassificationprovides severity / operatorImpact / requiresEscalation booleans andalertCorrelationprovides cooldown-aware suppression so receiver pipelines stay clean. - Long-running governance-safe agents — every verdict is replayable (deterministic scoring + content hash + stable schema version) so compliance review approves the rule cascade once and the approval stays valid as long as the rules stay stable.
- Customer-supplied API keys via HTTP headers — every customer brings their own keys; the actor never reuses a key across customers. Multi-tenant by default.
- MCP resources for methodology + source map + decision contract — agents inspect
resources/listbefore any paid call to read the formulas, source mapping, and enum surface without trial calls. - MCP prompts for canonical workflows —
weekly_competitor_brief,competitor_battle_card,portfolio_strategy_reviewregister asprompts/listentries so agents pick them up directly.
Deterministic AI infrastructure for governance-safe AI automation and machine-actionable competitive intelligence.
Pricing
Pay-per-event. No subscription. Apify free tier includes $5 of monthly credits.
| Scenario | Tool calls | Cost |
|---|---|---|
| Spot-check a competitor | 1 × full_competitive_audit | $0.25 |
| Weekly composite on 5 competitors | 5 × full_competitive_audit | $1.25 |
| Scheduled monitoring on 10 competitors weekly (3 emit events / 7 silent) | 10 × continuous_competitor_monitor; 3 charged | $0.75 |
| Strategic-pivot check across 8 watchlist competitors | 8 × detect_competitor_shift | Free |
| Territory overlap on 5 competitors with 50 keywords each | 5 × territory_overlap_analysis | $0.40 |
| Portfolio strategy review | 1 × get_portfolio_intelligence | Free |
| Reputation-only deep-dive | 1 × reputation_monitor | $0.08 |
| Compare 3 competitors against your domain | 3 × compare_competitors | $0.30 |
Set a per-event spending limit in your MCP client. The actor checks the limit before charging and returns a structured limit failure if reached.
How it works
Phase 1: Parse competitor identity
parseCompetitor() builds a structured identity (domain, url, brandName) from the input. This is the resolver phase of the two-phase fan-out: each sub-actor receives the identifier it natively expects.
Phase 2: Parallel sub-actor execution
runActorsParallel calls every required sub-actor via Actor.call() simultaneously, with 512MB memory and a 180-second timeout. Failures populate a per-source errors map that surfaces as dataSourceErrors. Skipped sources (fast mode) get the canonical Skipped: prefix.
Phase 3: Per-dimension scoring
Four pure scoring functions consume the correct output shape from each sub-actor and emit 0-100 scores, level enums, and structured evidence with source attribution.
Phase 4: Composite assembly
generateCompetitiveIntel applies the weighted formula (SEO 30% + ecommerce 25% + reputation 25% + tech 20%), assigns a verdict, and generates audience-tagged recommendations.
Phase 5: Signal bus normalisation
buildSignalBus converts the sub-actor data into a flat stream of NormalizedSignal records keyed by stable signal types. Every derivation in the next phase subscribes to signal types instead of reading the report shape directly.
Phase 6: Composition layer
All v1.5 derivations are computed: archetype, materialChanges, marketEvents, drift, momentum, scoreExplanation, signalLifecycles, narrativeEvolution, strategicMemoryGraph, pressureMap, attentionPriority, exposureSimulation, trajectoryForecast, dimensionConfidence, dimensionVolatility, seoDependenceRisk, reputationFragility, technologyRiskHorizon, strategicExposureGraph, portfolioBenchmark, alertClassification, alertCorrelation, threatAssessment (if context supplied), territoryOverlap (if ourKeywords supplied), constellationAggregate (auto-detect + caller-supplied hybrid), reviewThemes (from signal bus). None re-fetch data.
Phase 7: KV persistence
Per-competitor snapshots (capped at 12 most recent) and the entity index (capped at 500) are written to the competitor-history KV store. Both writes are non-critical; failure is logged but never breaks the tool.
Phase 8: Envelope wrap
wrapResponse / wrapNoData / wrapError attach the envelope (schemaVersion, recordType, captureTimestamp, contentHash, runSummary). The workflowProfile transform runs last to reshape for Zapier / Make / Dify.
Phase 9: PPE charge (success path only)
Actor.charge() runs after data resolves and before the response leaves. Empty-result responses short-circuit to noData without charging. Spending-limit hits return a structured limit failure.
Composite Intelligence Score explained
The composite is a weighted average of four dimension scores. Full formula in the methodology MCP resource.
| Dimension | Weight | What it measures |
|---|---|---|
| SEO Competitive | 30% | SERP positions + WCAG-as-accessibility-SEO |
| E-commerce | 25% | Product catalog depth, on-sale frequency, Shopify confirmation |
| Reputation | 25% | Cross-platform ratings, Trustpilot grade, sentiment, divergence |
| Tech Stack | 20% | Modern-vs-legacy ratio, breadth, CVE risk count, Wayback evolution |
composite = (seo * 0.30) + (ecommerce * 0.25) + (reputation * 0.25) + (techStack * 0.20)
| Score | Verdict |
|---|---|
| 80-100 | MARKET_LEADER |
| 60-79 | STRONG |
| 40-59 | ESTABLISHED |
| 20-39 | EMERGING |
| 0-19 | WEAK_COMPETITOR |
Output example (truncated)
full_competitive_audit against hubspot.com with ourDomain, ourKeywords, and ourVertical supplied:
Combine with other Apify actors
| Actor | How to combine |
|---|---|
| Website Tech Stack Detector | Pull per-technology metadata when tech_stack_analysis signals a CUTTING_EDGE or LEGACY stack worth investigating |
| Trustpilot Review Analyzer | Pull full review text for the brands flagged POOR by reputation_monitor |
| SERP Rank Tracker | Run targeted keyword sets against domains flagged DOMINANT by seo_ranking_intelligence |
| Company Deep Research | Pair digital posture with full company research for IC memos |
| Multi-Review Analyzer | Extract full review corpora for sentiment deep-dives |
Limitations
- Shopify-only e-commerce data. WooCommerce, Magento, custom storefronts, and Amazon seller accounts are not detected.
- SERP rankings reflect supplied keywords only. Pass
keywords(comma-separated) or useterritory_overlap_analysisto widen coverage. - Trustpilot requires a listing. Brands without a Trustpilot presence reduce the achievable reputation score.
- Wayback coverage varies by domain age. Domains under 3 years old will score low on Wayback evolution.
- Industry benchmark is portfolio-relative, not industry-cohort. The percentile is computed against YOUR previously-audited entities; full industry baselines require external cohort data we do not have.
- Constellation auto-detect coverage varies. OpenCorporates is global but free-tier rate-limits. WHOIS surfaces the registrant org but not sister domains directly. Companies House covers UK entities only and requires a free API key (
UK_COMPANIES_HOUSE_API_KEYenv var). Wikipedia covers notable brands but synthesises best-guess.com/.co.ukdomains for entities surfaced by name. Thecaveatfield on theconstellationAggregateblock names which sources contributed; customers should re-audit each surfaced member. - No paid-ad / hiring / funding signals. Out of scope for v1.5.
Troubleshooting
Composite score is unexpectedly low. Inspect dimensions.*.score and dimensionConfidence individually. Common causes: competitor isn't on Shopify (lowers ecommerce), no Trustpilot listing (lowers reputation), supplied SERP keywords don't match what they rank for. dataSourceErrors names which sources failed.
X-Serper-Api-Key header not set error. Add the header to your MCP client config alongside the Authorization: Bearer YOUR_APIFY_TOKEN line. Free key at https://serper.dev (2,500 queries / month). The actor reads headers per request; restart the MCP client after editing the config so it picks up the new headers.
Spending limit reached in tool response. MCP session hit the per-event limit. Increase in MCP client config.
Tool returns noData: true but no charge. All sources returned empty. Most often: domain unreachable, blocked, or brand name didn't resolve. Try the exact domain (e.g. stripe.com rather than Stripe).
detect_competitor_shift returns noData. Requires at least 2 prior snapshots. Run full_competitive_audit on this competitor at least twice first.
continuous_competitor_monitor returned suppressed: true. Working as designed: nothing material changed vs prior snapshot. No charge. Snapshot was persisted for future comparisons.
Standby cold start is slow on first request. Standby instances exit after 5 minutes of inactivity. Next request cold-starts (5-10 seconds). MCP clients reconnect transparently.
Responsible use
- Accesses publicly available website data, search results, public review platforms, and the Internet Archive.
- Respect website terms of service and robots.txt.
- Intended for legitimate competitive intelligence.
- Do not use extracted data to facilitate unauthorised access, defamation, or targeted harassment.
- For guidance on web scraping legality, see Apify's guide.
FAQ
How is this different from SimilarWeb or Semrush? Both use proprietary traffic-panel data built over years. This MCP fetches live public data, scores it through a deterministic model, and returns structured JSON for AI agents and automation pipelines. $0.06-$0.25 per call vs $120-$167 / month.
What does the composite score measure? Four weighted dimensions: SEO (30%), ecommerce (25%), reputation (25%), tech stack (20%). Each is a 0-100 sub-score with a level enum.
Why thirteen tools and not one?
Different tools answer different questions and have different charging behaviour. AI agents discover tools via tools/list and pick the right one for the user's prompt. Forcing everything onto one tool would require parameter knowledge the agent does not have.
Can I run this on non-English websites? Yes. Tech, Wayback, and WCAG work on any domain. SERP results depend on the keywords you supply.
How long does full_competitive_audit take?
60-120 seconds in accurate mode. The slowest sub-actor sets wall time. mode: 'fast' skips Wayback and WCAG and typically halves the time.
Can I compare my domain against a competitor?
Yes. compare_competitors with both competitor and benchmark arguments. Or pass ourDomain to full_competitive_audit for threat assessment.
What if one of the 8 sub-actors fails or times out?
Failing sources contribute empty arrays. dataSourceErrors names the failure per source. trustLayer.whichSourcesFailed and dimensionConfidence make the impact explicit on the response.
Can I schedule weekly sweeps?
Yes. Use Apify Schedules to invoke continuous_competitor_monitor on a cron. Cheaper and quieter than scheduled full_competitive_audit because no-event runs skip the charge.
How is this safe for autonomous AI agents?
decision.recommendedAction is a 5-value enum. agentInstructions.safeToAutoApprove is a single boolean. operationalReadiness.confidenceForAutonomousAction reports high / medium / low based on source coverage. Branch on these primitives; never parse prose.
Why deterministic? Automation systems consuming this MCP need to reproduce verdicts months later for governance and audit. A non-deterministic score is one that can drift between identical inputs. The scoring functions here are pure; the methodology MCP resource exposes every weight and threshold.
Help us improve
If something looks wrong, enable run sharing in Account Settings > Privacy so the actor developer can see run details. Visible only to the developer.
Support
Issues, feature requests, or custom integration questions: open an issue from the actor's page in the Apify Console.