Financial Crime Screening · AML for BI + Pipelines
Pricing
$300.00 / 1,000 aml risk classifications
Financial Crime Screening · AML for BI + Pipelines
AML/CFT composite screening as a scheduled Apify actor. Same deterministic engine as the MCP twin, dataset-output shape. For Zapier / Make / n8n / BI tools and scheduled bulk re-screening. 16 sources. 6 institutional policy profiles. $0.30 per result.
Pricing
$300.00 / 1,000 aml risk classifications
Rating
0.0
(0)
Developer
Ryan Clinton
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
22 days ago
Last modified
Categories
Share
Financial Crime Screening
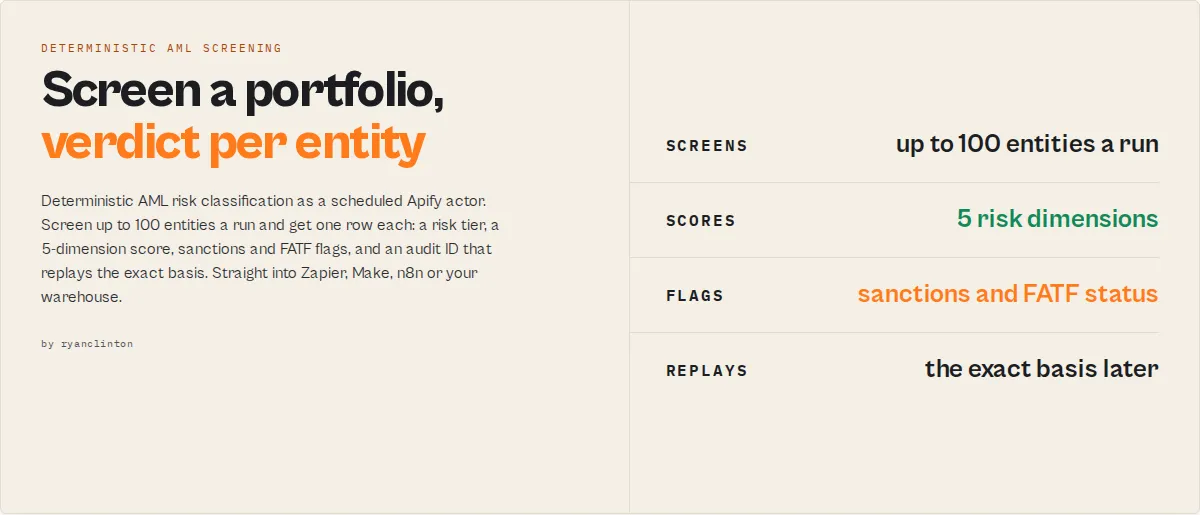
Deterministic AML risk classification as a scheduled-execution Apify actor.
Same engine, same envelope, same data sources as the MCP twin — but exposed as an Apify actor that pushes one result per entity to its dataset, instead of a Streamable HTTP MCP server. Built for the enterprise orchestration + batch intelligence layer: Zapier, Make, n8n, BI tools that consume Apify datasets directly, scheduled bulk re-screening cycles, and pipelines without Claude Desktop / Cursor / Cline access.
In one sentence
A deterministic AML compliance engine that produces replayable, machine-actionable risk classifications as Apify dataset rows.
In one paragraph
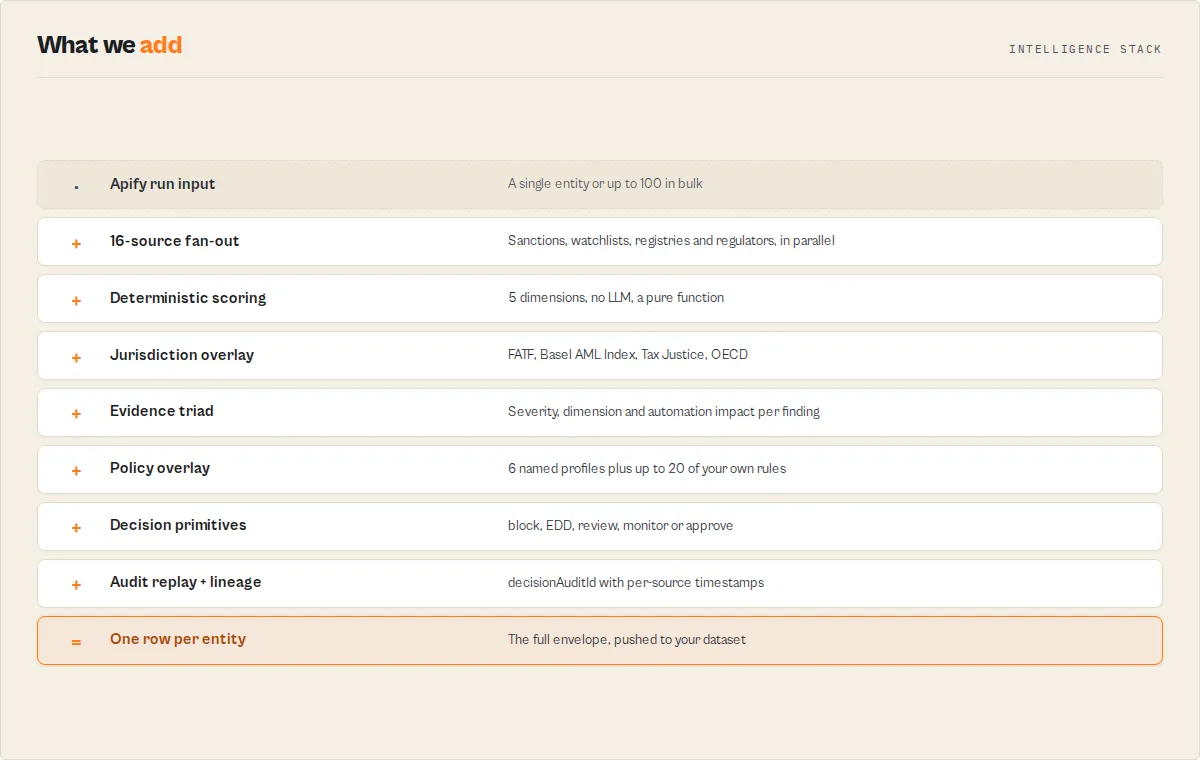
Financial Crime Screening is AI-native compliance infrastructure exposed as a scheduled Apify actor. 16 live data sources, 5-dimensional scoring, six named institutional policy profiles, caller-supplied custom rules, regulatory obligations with deadlines, operational restrictions for downstream banking systems, AI autonomy contracts, and decisionAuditId for regulatory replay. Same primitives the MCP twin exposes — but as one row per entity in your Apify dataset, ready to ingest into Zapier / Make / n8n / BI tools.
Why this is different
| Traditional AML APIs | This actor |
|---|---|
| Black-box composite scores | Deterministic five-dimensional scoring |
| Free-text recommendations | Stable action enums |
| Snapshot-only screening | Stateful risk memory + 30-day trajectory forecast |
| Human-oriented PDFs | Machine-actionable JSON, one row per entity |
| No replayability | decisionAuditId retrieves the exact decision basis months later |
| Vendor-curated lock-in | Primary-source data + customer-owned API keys |
| Annual contracts, analyst-seat licensing | Pay-per-decision infrastructure pricing |
When to use this vs the MCP
| You want | Use |
|---|---|
| AI agent (Claude Desktop, Cursor, Cline) makes one call at a time | financial-crime-screening-mcp |
| Zapier / Make / n8n pipeline consumes results | This actor |
| Scheduled bulk re-screening of an entity portfolio | This actor |
| BI tool ingests Apify datasets directly | This actor |
| Webhook-driven async event flow | This actor |
| Real-time / one-off per-entity decision | The MCP twin |
Same engine, same envelope. The only difference is the transport layer.
Core guarantees
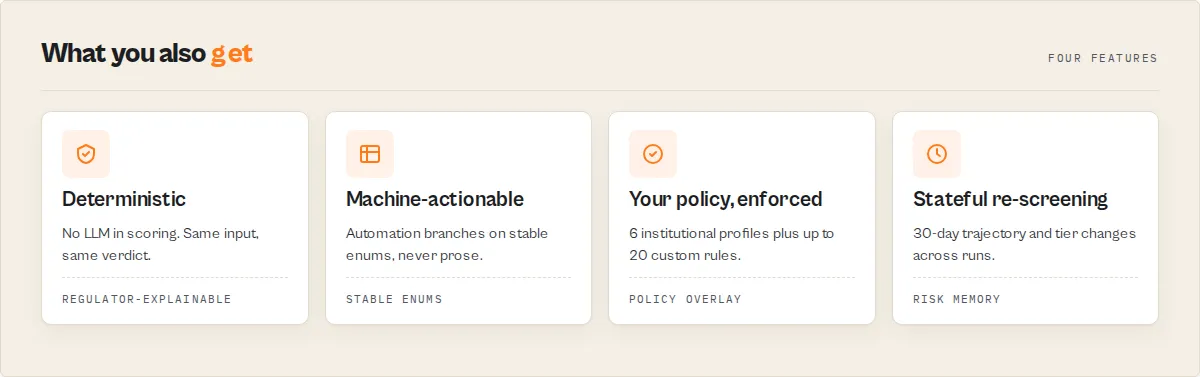
- Same input always produces the same verdict (deterministic)
- No LLM in the scoring path (regulator-explainable)
- Every decision is replayable via
decisionAuditId - Every action is machine-actionable through stable enums
- Automation branches on enums and booleans, never on free-text prose
- Every finding cites a regulatory source and carries an auditable URL
Designed for
- banks (BSA-regulated US, UK FCA, EU credit institutions)
- crypto exchanges (FinCEN MSB, NYDFS Part 504, MiCA-regulated)
- money service businesses / remittance firms
- fund administrators (LP onboarding, hedge fund KYC)
- fintechs and embedded-finance platforms
- payment processors and card issuers
- EU AMLR Article 6 obliged entities
- compliance automation teams running on Zapier / Make / n8n
- regulatory technology vendors building on top of primary-source data
Event-driven compliance workflows
Designed for:
- scheduled re-screening (daily SDN-delta sweep, quarterly tier-based cycles)
- webhook-triggered escalation (Apify run completion → Slack / PagerDuty / Jira)
- SIEM ingestion (route
complianceEvents[]to Splunk / Sentinel / Chronicle) - data-warehouse enrichment (one row per entity, BI tools pull directly)
- portfolio-wide compliance telemetry (track tier transitions across a customer book)
- nightly compliance state refresh (downstream account-state flag synchronisation)
Pair with Apify's built-in scheduler for cron-based runs, with webhooks for event-driven downstream routing, and with the dataset API for warehouse ingestion. No additional infrastructure required.
Input
Single entity:
Bulk mode (up to 100 entities per run):
With custom policy rules:
Bring your own upstream API keys
| Header / Input field | Source | Where to sign up |
|---|---|---|
opensanctions_api_key | OpenSanctions global sanctions, PEP, watchlist coverage | opensanctions.org/account/ |
opencorporates_api_key | OpenCorporates 200M+ corporate registry | opencorporates.com/api_accounts/new |
dol_api_key | DOL WHD + EBSA enforcement records | dataportal.dol.gov/registration |
fec_api_key | FEC campaign finance (optional) | api.open.fec.gov |
Customer-supplied keys are never stored — they're read once per run from input or env-var fallback and passed through to the relevant sub-actor. If a key is absent, that source is skipped and the response carries a dataSourceErrors entry of missing-credential.
Output
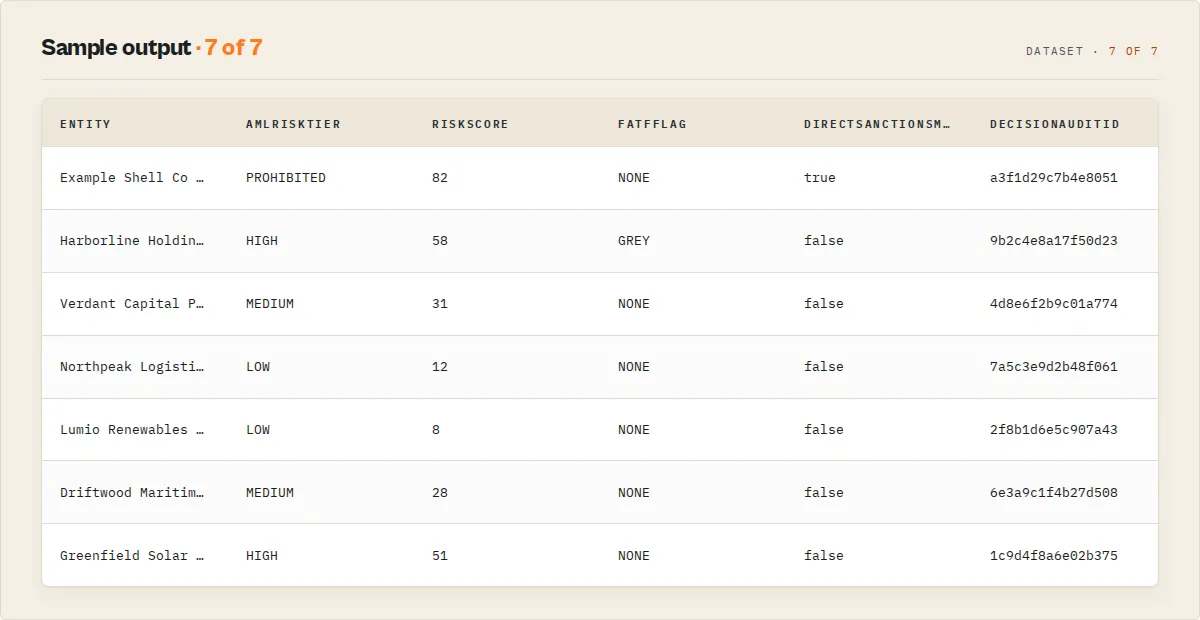
One dataset row per entity. Each entity produces:
- one deterministic classification (same input always produces the same verdict)
- one replayable audit object (retrievable months later via
decisionAuditId) - one machine-actionable decision envelope (stable enums for automation)
- one dataset row (immediately consumable by Zapier / Make / n8n / BI tools)
Compact canonical example:
Core primitives
Every classification returns:
amlRiskTier— LOW / MEDIUM / HIGH / PROHIBITEDdecision.recommendedAction— stable action enumevidence[]— structured findings with severity + dimension + automationImpactcomplianceEvents[]— normalised event-bus payload for SIEM / SOARautonomyContract— explicit allowed / prohibited actions for AI agentsobligations[]— regulatory deadlines with jurisdiction + regulatory-source citationoperationalRestrictions[]— account-state flags for downstream banking systemsdecisionAuditId— 16-char hex ID that replays the exact decision basisriskMemory— longitudinal state with 30-day projected tierpolicyEvaluation— institutional policy overlay (6 profiles + custom rules)
The full envelope additionally carries sourceLineage{}, runSummary{}, dimensions{}, topContributors[], narrative{}, confidence{}, derivedFrom{}, stateNarrative{}, trustLayer{}, operationalReadiness{}, jurisdictionRisk{}, and relationshipNetwork{} (companies only).
Policy profiles
| Profile | Treats FATF grey as | Max shell score | Min SAR tier | Auto-block fuzzy sanctions |
|---|---|---|---|---|
standard | medium | 100 | HIGH | no |
crypto_exchange_us | HIGH | 30 | MEDIUM | no |
bsa_bank_us | HIGH | 50 | HIGH | no |
eu_obliged_entity | HIGH | 40 | MEDIUM | no |
msb_remittance_us | HIGH | 35 | MEDIUM | no |
fund_administrator | medium | 40 | HIGH | no |
Why deterministic systems matter
Regulators require explainability, replayability, auditability, and stable escalation logic. Probabilistic AI systems (LLM-driven scoring, ML-based AML classifiers, opaque ensembles) struggle with all four because their outputs change over time even when inputs don't.
This actor produces reproducible compliance outcomes from deterministic rules and source evidence. Every score is a pure function of the upstream data plus a versioned rule set. Months later, regulatory examiners replay the exact verdict via decisionAuditId — the evidence[] array, the policyEvaluation block, the sourceLineage timestamps, and the dimensional scores all reproduce identically as long as the rule version matches.
Pricing
| Event | Cost |
|---|---|
result-returned (one classification) | $0.30 |
No subscription, no monthly minimum, no charge for failed runs (no-data + error responses don't trigger billing). Apify's $5/month platform credits cover dozens of classifications. Most compliance teams running 500-2,000 screenings per month spend $150-$600.
Limitations
- US-centric regulatory coverage. FDIC, CFPB, FEC, FARA, DOL WHD, DOL EBSA, Federal Register are US government sources. Non-US institutions have less coverage.
- OpenSanctions, OpenCorporates, and DOL sources require customer-supplied API keys. Without them, those sources skip with a
missing-credentialdataSourceErrorsentry. - 100 entities per run cap. For larger portfolios, dispatch multiple parallel runs or use the MCP twin's
batch_screentool. - Snapshot history retained per actor lifetime (50 snapshots per entity, 1000 decision audit entries total). Mirror to your own retention system for multi-year regulatory record-keeping.
- Fuzzy sanctions matches (confidence 0.50-0.95) always require human review — the actor cannot determine on its own whether a fuzzy match is the same person.
- Not a substitute for FinCEN Form 114 filing or qualified BSA/AML officer judgement. The actor produces audit-ready inputs to compliance workflows; the workflows themselves remain human-supervised.
Platform ecosystem
| Layer | Tool |
|---|---|
| Agent-native MCP transport | ryanclinton/financial-crime-screening-mcp |
| Pipeline / BI dataset transport | This actor |
| Underlying sub-actors | 16 wrapper actors (OFAC, OpenSanctions, Interpol, FBI, FARA, FEC, OpenCorporates, GLEIF, Nonprofit Explorer, SEC EDGAR, SEC Insider, CFPB, FDIC, Federal Register, DOL WHD, DOL EBSA) |
Responsible use
This actor accesses only publicly available government data and customer-supplied API endpoints. AML screening results are analytical aids, not legal determinations. Compliance decisions must be made by qualified personnel under applicable law. SAR filing obligations and timelines are governed by BSA/FinCEN regulations, not by the recommendation strings returned by this actor.
Support
Open an issue on the Apify Store page for the actor. For custom integrations, enterprise compliance pipelines, or AI-native compliance infrastructure questions, reach out through the Apify platform.