Financial News Sentiment Analyzer
Pricing
from $20.00 / 1,000 article analyzed | vaders
Financial News Sentiment Analyzer
Multi-source financial sentiment analysis using VADER ($0.02/article) or LLM ($0.05/article) engines. Scrapes Yahoo, Google News, and SEC EDGAR. Features budget caps and live market enrichment (Price, P/E, Market Cap). Delivers structured JSON for trading systems and AI agents.
Pricing
from $20.00 / 1,000 article analyzed | vaders
Rating
5.0
(2)
Developer
Scionic Tech
Maintained by CommunityActor stats
2
Bookmarked
40
Total users
5
Monthly active users
3 months ago
Last modified
Categories
Share
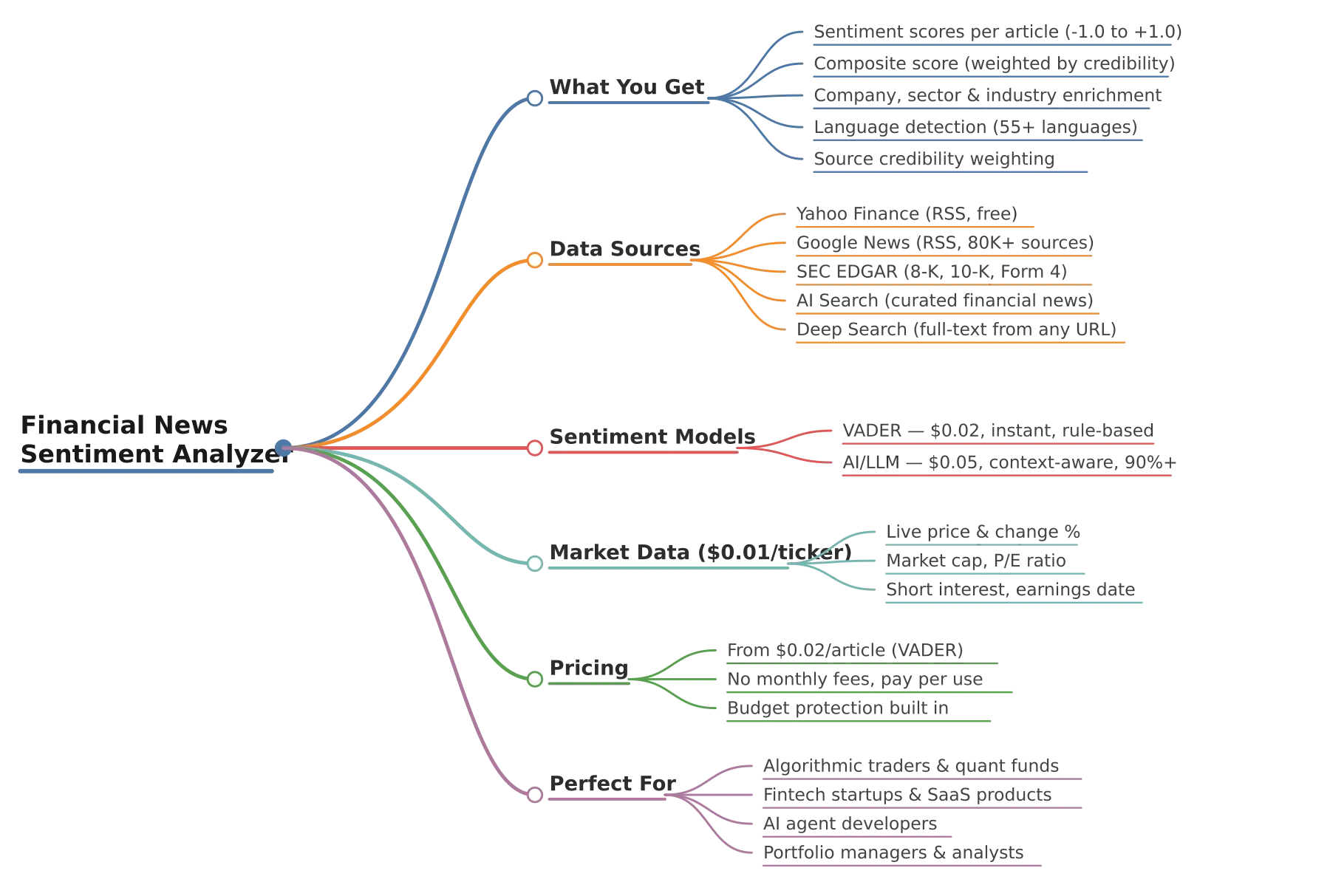
What does Financial News Sentiment Analyzer do?
Financial News Sentiment Analyzer scrapes financial news from multiple sources, runs AI-powered sentiment analysis on every headline, and outputs structured, machine-readable data enriched with live market data, confidence scores, and company classifications.
It is an affordable, pay-per-use alternative to Bloomberg Terminal ($24,240/year), Refinitiv Eikon ($22,000/year), and other institutional data providers. You pay $0.02 per article analyzed — no subscriptions, no minimums.
Key features:
- Multi-source aggregation — Yahoo Finance, Google News, SEC EDGAR filings, and AI-powered search in a single run
- Two sentiment engines — Fast rule-based (VADER) or premium AI-powered (LLM) with financial context understanding
- Live market data enrichment — Current price, price change %, market cap, P/E ratio, short interest, earnings dates per ticker
- Proprietary composite scoring — Sentiment weighted by source credibility and model confidence
- Deep Search — Full-text article extraction from any URL for superior sentiment accuracy
- Company & sector enrichment — Automatic ticker-to-company mapping with industry classification
- Language detection — 55+ languages detected, filter non-English noise automatically
- Budget protection — Automatically stops when your spending limit is reached, never overcharges
- Pay only for what you use — No monthly fees, no setup costs
Data sources
| Source | Type | Data | Cost |
|---|---|---|---|
| Yahoo Finance | RSS feed | Headlines, summaries, per-ticker news | Free |
| Google News | RSS feed | Aggregated headlines from 80,000+ sources | Free |
| SEC EDGAR | API | 8-K, 10-K, 10-Q, Form 4 filings | Free |
| AI Search | API | AI-curated financial articles missed by RSS | $0.03/search |
| Deep Search | URL scraper | Full article text from any URL (CNBC, Reuters, etc.) | $0.05/page |
What data do you get?
Each article in the output dataset contains:
| Field | Description | Example |
|---|---|---|
title | Article headline | "Top Analysts See Solid Upside in Nvidia Stock" |
source | Source identifier | google_news, sec_edgar, ai_search |
sentiment_label | Bullish / Bearish / Neutral | "bullish" |
sentiment_score | Continuous score (-1.0 to +1.0) | 0.850 |
sentiment_confidence | Model confidence (0.0 to 1.0) | 0.95 |
composite_score | Score × credibility × confidence | 0.547 |
sentiment_model | Which model produced the score | "vader" or "llm" |
tickers | Mentioned stock tickers | ["NVDA"] |
companies | Resolved company names | ["Nvidia"] |
sectors | Sector classification | ["Technology"] |
industry | Industry classification | "Information Technology" |
source_credibility | Source reliability score | 0.70 |
published_at | Publication timestamp (UTC) | "2026-03-21T07:10:39Z" |
language | Detected language | "en" |
article_type | Category | "news", "filing", "press_release" |
mentioned_tickers | Additional tickers found in text | ["AMD", "INTC"] |
With market data enrichment enabled ($0.01/ticker):
| Field | Description | Example |
|---|---|---|
current_price | Live stock price | 172.70 |
price_change_pct | Change from previous close | -3.28 |
market_cap | Market capitalization (USD) | 4197473583104 |
pe_ratio | Trailing P/E ratio | 35.24 |
short_ratio | Short interest ratio | 1.32 |
earnings_date | Next earnings date | "2026-05-20" |
Pricing
| Event | Price | When charged |
|---|---|---|
| Article analyzed (VADER) | $0.02 | Per article with fast rule-based sentiment |
| Article analyzed (LLM) | $0.05 | Per article with AI-powered sentiment |
| AI Search query | $0.03 | Per search query when AI Search source is enabled |
| Deep Search page | $0.05 | Per URL scraped for full-text extraction |
| Ticker enrichment | $0.01 | Per unique ticker enriched with live market data |
Cost examples:
| Use case | Configuration | Est. cost |
|---|---|---|
| Quick check, 1 ticker, 10 articles | VADER, Google News | ~$0.21 |
| Daily monitoring, 5 tickers, 50 articles | VADER, all free sources | ~$1.01 |
| Deep analysis with market data | LLM, AI Search, enrichment, 3 tickers | ~$1.63 |
| Full stack, 5 tickers, 50 articles | LLM, AI Search, Deep Search, enrichment | ~$3.21 |
Compare to alternatives:
| Provider | Annual cost | Sentiment | Market data | API access |
|---|---|---|---|---|
| Bloomberg Terminal | $24,240 | Limited | Yes | No |
| Refinitiv Eikon | $22,000 | Yes | Yes | Yes |
| Finnhub Premium | $6,000 | Basic | Yes | Yes |
| This Actor (VADER) | ~$120-600 | Yes | Optional | Yes |
| This Actor (LLM) | ~$300-1,500 | Advanced | Optional | Yes |
How it works

Quick start
Step 1. Click Try for free and configure your run:
- Enter stock tickers (e.g.,
AAPL,TSLA,NVDA) - Choose news sources (default: all free sources)
- Pick sentiment model —
vaderfor speed,llmfor accuracy - Optionally enable market data enrichment
Step 2. Run the Actor.
Step 3. Download results from the Dataset tab as JSON, CSV, or Excel.
Sentiment models compared
| VADER | LLM (AI-Powered) | |
|---|---|---|
| Speed | Instant (~1ms/article) | ~500ms/article (batched) |
| Cost | $0.02/article | $0.05/article |
| Strengths | Fast, deterministic, no external dependency | Understands context, negation, financial nuance |
| Weakness | Misses context in complex headlines | Slightly slower, higher cost |
| Best for | High-volume monitoring, cost-sensitive | Investment decisions, research reports |
Example where it matters:
"Nvidia Stock Drops. Not Even Elon Musk Can Give Shares a Boost."
- VADER: bullish +0.83 (confused by "Boost")
- LLM: bearish -0.95 (understands "Drops" is the signal)
Output example
Use cases
Algorithmic trading — Feed real-time sentiment signals into your trading system. The composite score combines sentiment, source credibility, and confidence into a single actionable number. Market data enrichment adds price context alongside sentiment.
Portfolio monitoring — Schedule daily runs across your holdings. Track sentiment trends over time. Detect negative news before it hits the price. Get notified when short interest or P/E ratios change.
Research & due diligence — Analyze sentiment around a company before investing. Compare sentiment across competitors in the same sector. Use Deep Search to extract full articles from any URL.
AI agents & automation — Structured JSON output works directly with AI agents, LangChain, and automation platforms. Schedule runs and pipe results into your workflow.
Fintech products — Build sentiment dashboards, alerts, and newsletters. The standardized schema makes integration straightforward across all sources.
Input parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
tickers | string[] | ["AAPL", "TSLA"] | Stock tickers to analyze |
query | string | — | Free-text search query |
sources | string[] | All free sources | Which sources to scrape |
maxArticles | integer | 20 | Max articles per source |
sentimentModel | string | "vader" | "vader" or "llm" |
includeRawText | boolean | true | Include article summaries |
enrichWithMarketData | boolean | false | Add live price, market cap, P/E per ticker ($0.01/ticker) |
deepSearchUrls | string[] | — | URLs for full-text extraction ($0.05/page) |
Integration examples
Python
JavaScript
FAQ
Is this financial advice? No. Sentiment scores are AI-generated and may be inaccurate. This tool is for informational and research purposes only. Always do your own due diligence.
How accurate is the sentiment analysis? VADER with our financial lexicon correctly classifies ~75-80% of financial headlines. The LLM model achieves ~90-95% accuracy on financial text, including complex headlines with negation and context.
What about paywalled sources (Bloomberg, WSJ)? We do not scrape paywalled content. All sources are publicly accessible or use official APIs. Use Deep Search URLs to extract articles from sites you have access to.
How fresh is the data? Articles are scraped in real-time when the actor runs. Schedule it hourly or daily for continuous monitoring. Market data enrichment provides live prices at the time of the run.
Can I use this with my AI agent or LLM? Yes. The structured JSON output is designed for programmatic consumption. It works directly with LangChain, AutoGPT, Claude, and any tool that accepts JSON data.
What happens if my budget runs out? The actor automatically stops processing and returns whatever articles it has already analyzed. You are never overcharged. Set a spending limit in the Apify Console to control costs.
What happens if a source is down? Each source is fetched independently. If one fails, the others still return data. Errors are logged in the run stats.
Legal disclaimer
This actor only scrapes publicly available data. Article summaries are limited to 200 characters for legal compliance — full article text is never stored or distributed. SEC EDGAR data is explicitly public domain. All other data is derived analysis (sentiment scores) which is protected as transformative use.
Not affiliated with Yahoo Finance, Google, SEC, or any news publisher.