Google Trends Scraper — All Trends Data API
Pricing
from $6.00 / 1,000 trend reports
Google Trends Scraper — All Trends Data API
Google Trends API alternative — one reliable scraper for interest over time, compare keywords (up to 5, one scale), related queries, interest by region, and trending searches now. Schema-stable JSON for SEO keyword research. No charge for empty or failed results. No start fee. API + MCP ready.
Pricing
from $6.00 / 1,000 trend reports
Rating
0.0
(0)
Developer
Steadyfetch Team
Maintained by CommunityActor stats
1
Bookmarked
35
Total users
18
Monthly active users
21 days ago
Last modified
Share
Scrape Google Trends data as clean, schema-stable JSON — a reliable Google Trends API for marketers, SEO tools, and data/AI teams. One actor covers every Trends surface that actually returns data in 2026: interest over time, multi-keyword compare, related queries, interest by region, and trending now. Works with a single keyword or up to 5 in compare mode.
| Surface | What you get | Sample field |
|---|---|---|
| Interest over time | Full 0–100 timeline for any keyword, geo, and time range | data.points[].value |
| Multi-keyword compare | 2–5 keywords scored on one shared scale, like the Trends UI | comparedWith, sharedScale: true |
| Related queries | Top + rising queries with values and % growth | data.rising[].formattedValue |
| Interest by region | Per-state/country breakdown for the keyword | data.regions[].geoCode |
| Trending now | Current trending searches per country with traffic estimate + news links | data.approxTraffic, data.news[] |
Why this Google Trends scraper?
- Fail-fast, never hang. Every request has a hard timeout and a bounded retry budget over rotating residential sessions. A run either returns data or stops with an explicit reason — no infinite loops, no zombie runs. Set a Maximum cost per run and you never pay a cent over it.
- You are never charged a result fee for empty results. Google Trends has a degraded mode where it returns HTTP 200 with an empty payload. This actor detects it, retries on a fresh session, and if a fetch ultimately fails it is reported in the run's
ERRORSrecord and no result fee is charged. - Schema-stable JSON. Every item carries
schemaVersion, and every field is always present — explicitnullover silent omission. Your pipeline never breaks on a missing key. - Honest scope. Related topics is intentionally not offered: Google's topics feed currently returns empty data platform-wide (verified June 2026 from multiple networks). Actors that still sell it deliver empty rows. We'll ship the surface the day it returns real data.
- Clean exits, honest partials. If a run hits your max-cost ceiling or its timeout, it stops cleanly, tells you exactly how many units are left, and how to get the rest.
How to scrape Google Trends (no code)
- Click Try for free — the form is prefilled with a working example (
bitcoin, all surfaces). - Add your keywords and pick surfaces, location, and time range.
- Click Start. The first results usually land in the dataset within a minute.
- Export as JSON, CSV, or Excel — or schedule the run to repeat daily/weekly.
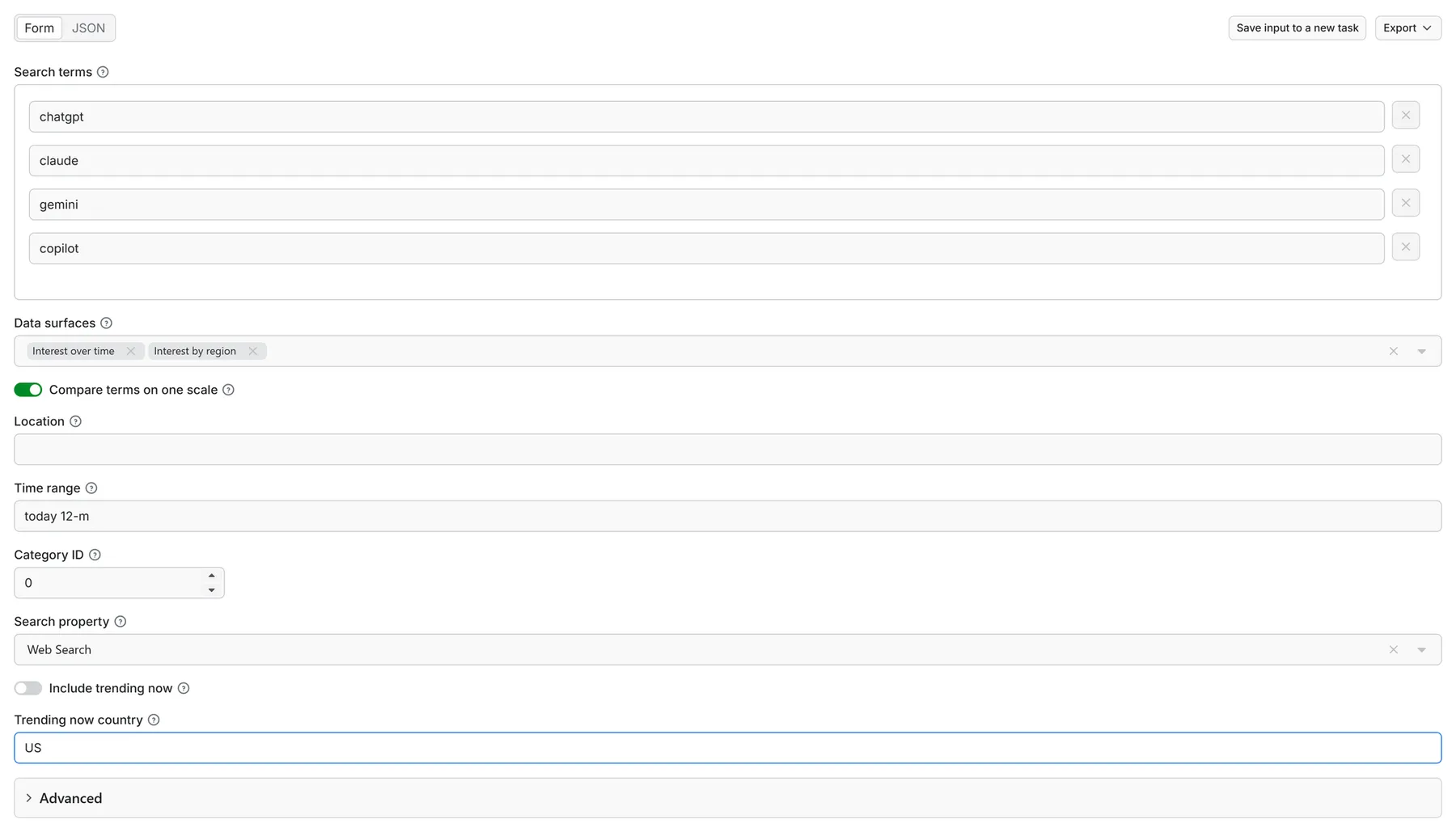
Input example
Output examples
See real output before you run anything — live sample dataset (actual results, every surface), or a 4-keyword compare run (chatgpt vs claude vs gemini vs copilot on one shared scale).
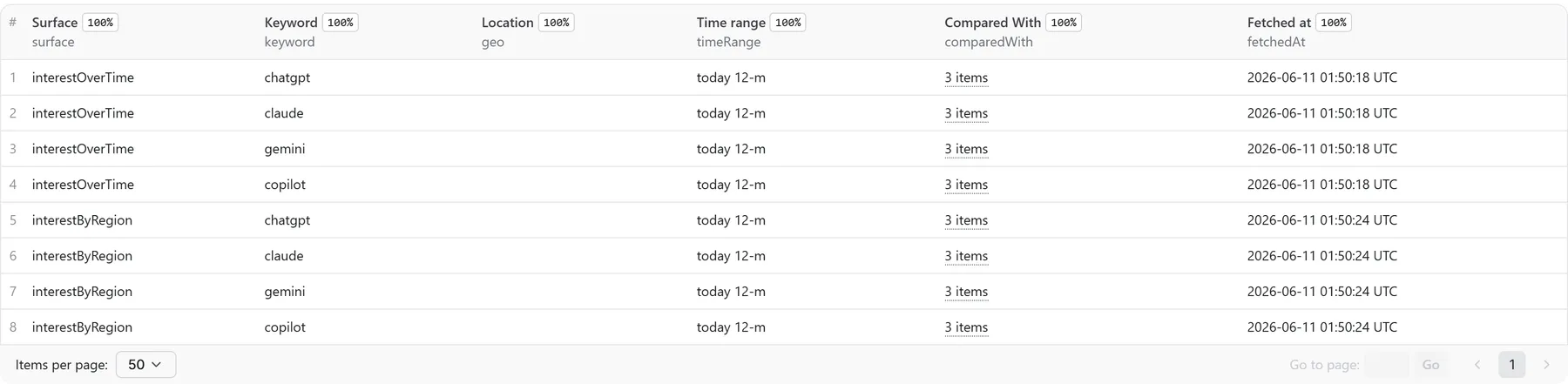
One dataset item = one keyword × one surface. Every item shares the same envelope:
Google Trends related queries API
Google Trends trending now API
Note: Google typically surfaces ~10–20 trending searches per country per pull; some days fewer. Trends values are a relative 0–100 index with sampling variance — small differences vs the Trends UI are normal and documented in the FAQ.
How much does it cost to scrape Google Trends?
1 result = one keyword × one surface payload. A full 12-month timeline is one result. A complete related-queries set (top + rising) is one result. One trending-now row is one result.
No start fee, no subscription — you pay only for delivered results. Failed or empty fetches are never charged.
From July 19, 2026 pricing is all-inclusive: platform usage (compute + residential proxy) is included in the event price — one flat, predictable price per result, no separate usage line. The table below shows all-in costs at the FREE-tier price ($9.00/1,000; paid Apify plans price lower, down to $6.00/1,000):
| What you run | Results | All-in cost* |
|---|---|---|
| 1 keyword, all 3 keyword surfaces | 3 | ~$0.03 |
| Track 100 keywords' interest weekly | 430/mo | ~$3.87/mo |
| Track 250 keywords daily | 7,500/mo | ~$67.50/mo (from $45 on paid plans) |
| Trending now for 3 countries, daily | ~900/mo | ~$8.10/mo |
*Until July 19, 2026 the previous model still applies: a lower event price ($3.00/1,000 FREE tier, down to $1.50/1,000) plus Apify platform usage billed separately (typically $1–3 per 1,000 results, occasionally more on retry-heavy keywords). Either way you stay in control: set a Maximum cost per run and the run stops cleanly before exceeding it — and Apify's free plan ($5 monthly credit) is enough to evaluate seriously before paying anything.
Google Trends API alternative
There is no generally available official Google Trends API: Google's announced API is in closed alpha (waitlist, no trending-now surface). The popular Python library pytrends is unmaintained, with long-broken endpoints. This actor is a stable HTTP/JSON alternative: callable from any language, schedulable, monitored, exportable to CSV/Sheets — with reliability engineering (residential proxy rotation, consistent browser fingerprints per session, fail-fast retries) that one-off scripts and unmaintained libraries can't sustain.
Use it via API, MCP, and integrations
Connect from any MCP client (Claude, Cursor, …) in one step — add this server to your MCP config:
MCP-ready, including multi-keyword compare (verified end-to-end, June 2026): every input works identically from the UI, the REST API, and MCP clients — the input is one flat JSON schema with no hidden flags. Quick calls (trending now, single keyword) return results inside the tool call; bigger jobs hand back a run you can poll with the bundled dataset tools. Scheduling, monitoring, webhooks, and Make/Zapier connections come with the Apify platform.
FAQ
Is there an official Google Trends API?
Google announced one, but it remains alpha/waitlist-only and does not cover trending now. This actor exists to fill that gap today.
Is it legal to scrape Google Trends?
This actor only collects public, non-personal, aggregated data — the same anonymized index anyone sees at trends.google.com. Courts have repeatedly held that scraping publicly accessible data is lawful (e.g., hiQ v. LinkedIn, Meta v. Bright Data). Still, consult your counsel for your specific use.
Why do values differ slightly from the Trends UI?
Trends is a sampled, relative 0–100 index; Google itself returns slightly different values across sessions. Differences of a few points are inherent to the source, not a scraper defect.
What happens when Google blocks a request?
The session is discarded and a fresh residential session (new IP, new fingerprint, fresh tokens) retries — up to 5 attempts with cooldowns. If all fail, the fetch is recorded in ERRORS with the exact reason and no result fee is charged for it. (From July 19, 2026 those retries cost you nothing at all — platform usage is included in the event price; until then Apify bills usage for the attempts separately.)
Can I compare 5 keywords?
Yes — set compare: true with 2–5 searchTerms to get them on one shared scale. Related queries are per-keyword, so fetch them in a second run without compare.
Where are related topics?
Google's topics feed currently returns empty data platform-wide (verified June 2026). We don't sell empty rows. The surface ships the day Google's data returns.
Feedback & support
Found an issue or missing a feature? Open it on the Issues tab — issues get a response within one business day, and fixes land in the changelog. If this actor saves you time, a review helps other buyers find it.