AI Agent Effect Firewall
Pricing
Pay per usage
AI Agent Effect Firewall
Execution firewall for AI agents. Blocks untrusted inputs from triggering real-world actions by enforcing decision-level allow / deny / approval gates. Infrastructure safety layer for tool-enabled agents
Pricing
Pay per usage
Rating
0.0
(0)
Developer
Tomasz Trojanowski
Maintained by CommunityActor stats
0
Bookmarked
1
Total users
0
Monthly active users
5 months ago
Last modified
Categories
Share
Decision‑level execution firewall for tool‑enabled AI agents
(Execution boundaries, not prompt scanning)
TL;DR
AI Agent Effect Firewall is a drop‑in execution guard for agent systems.
It decides whether an agent is allowed to do something — not what it is allowed to say.
For every requested effect (tool call, API call, filesystem access, publish action), the firewall returns one of three decisions:
allowdenyrequire_approval
with a risk score and explicit reasons.
This is infrastructure, not an agent.
Why this exists (real problem, not theory)
Modern AI systems increasingly look like this:
This architecture is fundamentally unsafe by default.
Why?
Because natural language does not preserve trust boundaries.
An LLM can unintentionally turn:
- scraped text
- emails
- RSS headlines
- documents into real‑world actions.
This is usually called prompt injection.
That name is misleading.
The real problem is:
Reasoning and execution are coupled without a mandatory decision gate.
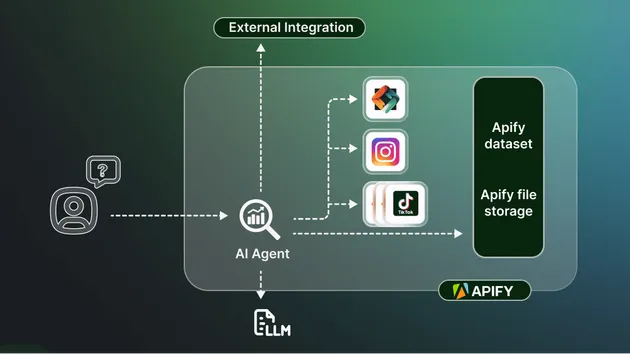
What this firewall actually does
AI Agent Effect Firewall sits between reasoning and execution.
It evaluates effects, not text.
For every request it checks:
- What effect is requested
- filesystem.read
- api.call
- publish_post
- delegation
- Where the influence came from
- system
- internal agent
- external input
- What resource is targeted
- file path
- API host
- external service
- Policy
- deny lists
- allow lists
- sensitivity patterns
- risk thresholds
It returns a deterministic decision with audit logs.
What this firewall is NOT
- ❌ Not a prompt scanner
- ❌ Not a jailbreak detector
- ❌ Not content moderation
- ❌ Not sentiment or intent analysis
- ❌ Not an LLM wrapper
It does not read prompts.
It enforces execution boundaries.
Concrete architecture placement
This makes execution non‑bypassable.
Real usage example (practical)
Example: RSS → LLM → social media posting
Without firewall:
- RSS headline influences LLM
- LLM calls
publish_post - Post goes live
With firewall:
- LLM proposes an action:
- Your orchestrator sends this to the firewall:
- Firewall responds:
- Post does NOT go live automatically.
This is the difference between:
- automation
- controlled automation
Executable test examples (curl)
Health check
External input tries to read private SSH key (DENY)
Expected:
- decision:
deny - high riskScore
- reason: sensitive resource + external origin
External input performing read‑only navigation (ALLOW)
Internal agent reading internal file (ALLOW)
Allow‑listed API call (ALLOW)
Non‑allow‑listed API call (REQUIRE_APPROVAL)
Real‑world case: Clawdbot / Moltbot (2026)
In early 2026, the Clawdbot project (later renamed Moltbot) became a widely discussed example of agent exposure gone wrong.
What happened:
- Tool‑enabled agents were exposed to the internet
- Agents ran with broad filesystem and execution privileges
- No non‑bypassable execution gate existed
- Untrusted influence could reach real effects
There was no sophisticated AI attack.
The failure was architectural.
Language crossed trust boundaries and directly caused execution.
Why this is NOT a prompt injection story
No clever prompts were required.
The system failed because:
- reasoning and execution were coupled
- agents ran with production privileges
- no deterministic decision gate existed
This is a confused deputy problem, amplified by autonomy.
How this firewall would have changed the outcome
With AI Agent Effect Firewall:
- external influence could not directly trigger tools
- filesystem and API access would be gated
- high‑impact effects would require approval
- every attempt would be logged
The incident would have been contained, not viral.
Threat model (concise)
Assets
- filesystem
- APIs and credentials
- public outputs
- delegation capability
Trust levels
- system / developer
- internal agents
- external input
Security guarantee
No irreversible or privileged effect executes without passing a deterministic, auditable decision gate.
Why this matters
LLMs are not the problem.
Unbounded execution is.
This firewall turns agent systems from:
- hope‑based automation
into:
- controlled, observable systems
License
Open pattern.
Free to use, modify, and adapt.