Reddit Posts Scraper - PAUSED
DeprecatedPricing
from $2.00 / 1,000 reddit posts
Reddit Posts Scraper - PAUSED
DeprecatedPAUSED: temporarily removed from active promotion while owner-run cost noise and unit economics are reviewed. Use only if you already depend on it. Guide: https://konabayev.com/tools/reddit-posts-scraper/?utm_source=apify_info&utm_medium=referral&utm_campaign=reddit-posts-scraper
Pricing
from $2.00 / 1,000 reddit posts
Rating
0.0
(0)
Developer
Tugelbay Konabayev
Maintained by CommunityActor stats
0
Bookmarked
20
Total users
7
Monthly active users
7 days ago
Last modified
Categories
Share
Reddit Public Data Scraper - Comments & RAG
Extract public Reddit posts, comments, subreddit listings, search results, and user submissions without creating a Reddit OAuth app or maintaining custom scraper scripts. Use it as a Reddit data extraction workflow, comment scraper, or RAG-ready community intelligence feed.
Scrape Reddit comments — fetch depth-limited comment trees for specific post IDs, subreddit listings, or Reddit search results. Sentiment-tagged comments — each comment can be classified
positive/negative/neutralvia fast lexicon scoring with no LLM cost. Per-post quality and engagement scores — filter downstream byqualityScore,engagementScore,commentDensity, andisDiscussionHeavy. Smart fallback chain — public Reddit endpoints plus public-page fallback handling when the first request path is blocked. No OAuth required for public listings, search, users, and direct post IDs.

Scrape public Reddit posts and comments without setting up OAuth apps or self-hosting custom scripts. This actor wraps Reddit's public .json endpoints behind a single Apify-platform input with proxy rotation, incremental dataset writes, and a clean canonical output schema.
Perfect for AI agents, RAG pipelines, market research, competitive intelligence, trend tracking, and content monitoring — returns clean Markdown that plugs straight into LangChain document loaders or Claude MCP tools.
For a longer implementation guide, production recipes, and SEO/GEO positioning notes, see the Reddit Posts Scraper guide on Konabayev.com.
Direct answers for search and AI agents
Can I scrape Reddit comments without the official Reddit API? Yes. Provide postIds or run a subreddit/search crawl with includeComments=true; the actor returns the post plus a structured comments array.
Can I use this in a Reddit data API workflow? Yes. Run it through the Apify API and export JSON dataset rows for posts, comments, authors, scores, engagement/source fields, timestamps, media URLs, permalinks, and optional Markdown for RAG.
Can I monitor Reddit search results? Yes. Use the search field for Reddit-wide queries such as a brand, competitor, category, or buyer-intent phrase. Use sort=new for alerts and sort=top for research.
Can I run Reddit sentiment analysis? Yes. Enable includeComments and keep includeSentiment=true; each parsed comment receives a sentiment label suitable for filtering or dashboarding.
Production lead and research recipes
Use these inputs when you want paid, production-size runs rather than a small sample.
Scrape Reddit comments for sentiment analysis
Reddit data API for weekly market research
Reddit RAG corpus for AI agents
How it works
This actor supports four input sources, processed in priority order until maxItems is reached:
postIds— direct fetch of specific posts by ID (e.g.1k0abc). Returns full content + optional comment tree first.users— each user's submitted-posts stream fills the remaining result cap.search— Reddit-wide keyword search fills the remaining result cap. Supports Reddit's native operators:author:,subreddit:,site:, etc.subreddits— one or more subreddit listings withsort(hot/new/top/rising/controversial) andtimeframe(hour/day/week/month/year/all) fill any remaining capacity.
Posts are pushed to the dataset incrementally — even if the run is aborted, everything fetched so far is already stored.
Why use this instead of alternatives?
| Feature | This Apify Actor | Self-hosted script | Reddit official API (paid) | Other Apify scrapers |
|---|---|---|---|---|
| Auth required | No | Yes (OAuth app) | Yes (app + tier limits) | Varies |
| IP rotation | Yes — Apify proxy | Manual | N/A | Varies |
| Output formats | full / minimal / rag-markdown | custom code | custom code | full only |
| Comment trees | Optional, depth-limited | Manual pagination | Manual pagination | Varies |
| Search | Yes — same input | Yes | Yes | Often separate actor |
| User streams | Yes — same input | Yes | Yes | Often separate actor |
| Direct post-ID fetch | Yes — same input | Yes | Yes | Rarely |
| MCP compatible | Yes (PPE = agent-friendly) | No | No | Rarely |
| Pay model | PPE — only what you scrape | Free but self-host | Token quotas | Varies |
Key advantage: one input schema instead of four separate actors. Drop in subreddit names OR a search query OR user handles OR specific post IDs and the actor just works.
Input examples
Trending in two subreddits (default prefill)
Top of the week, with comments, for RAG
Search across all of Reddit for a product mention
Pull specific posts by ID (faster than listing)
A user's submitted posts
Input parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
subreddits | Array[String] | ["MachineLearning","webscraping"] | Subreddit names without r/ |
search | String | — | Reddit-wide search query (overrides subreddits) |
users | Array[String] | — | Usernames without u/ |
postIds | Array[String] | — | Direct post IDs (highest priority) |
sort | Enum | hot | hot / new / top / rising / controversial |
timeframe | Enum | day | For top/controversial: hour / day / week / month / year / all |
maxItems | Integer | 10 | Max posts across all sources (1–10,000) |
includeComments | Boolean | false | Fetch comment tree per post |
maxComments | Integer | 20 | Per-post comment cap (1–500) |
maxCommentDepth | Integer | 3 | Reply-tree depth (0–10) |
outputFormat | Enum | full | full / minimal / rag |
skipNsfw | Boolean | false | Drop posts with over_18=true |
minScore | Integer | 0 | Drop posts below this upvote count |
proxyConfiguration | Object | Apify proxy | Proxy rotation (recommended) |
Choosing the right source mode
Use subreddits when you know exactly where the conversation happens. This is the best mode for routine monitoring because subreddit listings are predictable and easy to schedule.
Use search when you are discovering conversations across Reddit. Search is useful for brand names, competitor names, product categories, and buyer-intent phrases, but Reddit search can be less complete than focused subreddit monitoring.
Use users when you want posts from known accounts. This is useful for creator/influencer research, executive monitoring, and tracking official company accounts.
Use postIds when you already have URLs or IDs and need clean JSON, Markdown, or comments for specific threads.
Priority order matters: if postIds is set, the actor uses post IDs first. If users is set, it uses user streams before search/subreddit listings. Later source modes can still fill the remaining maxItems capacity, but one source mode per run usually produces cleaner reporting.
Recommended workflows
Brand and competitor monitoring
- Start with
searchfor your brand and 2-3 competitors. - Export dataset rows to Google Sheets or BigQuery.
- Filter by
score,num_comments, and subreddit. - Add the best subreddits to a scheduled
subredditsrun. - Use
includeComments=trueonly for posts that need deeper analysis.
Example:
Buyer-intent research
Use Reddit search operators and RAG output to collect real purchase language:
Then send the markdown field into your LLM workflow to extract:
- pain points
- feature requests
- products mentioned
- objections
- exact customer language
- competitor alternatives
Weekly subreddit digest
This is the simplest scheduled monitoring pattern. It avoids comments by default and keeps cost predictable.
RAG dataset for an agent
Use this when you want thread context, not just post metadata.
Output format
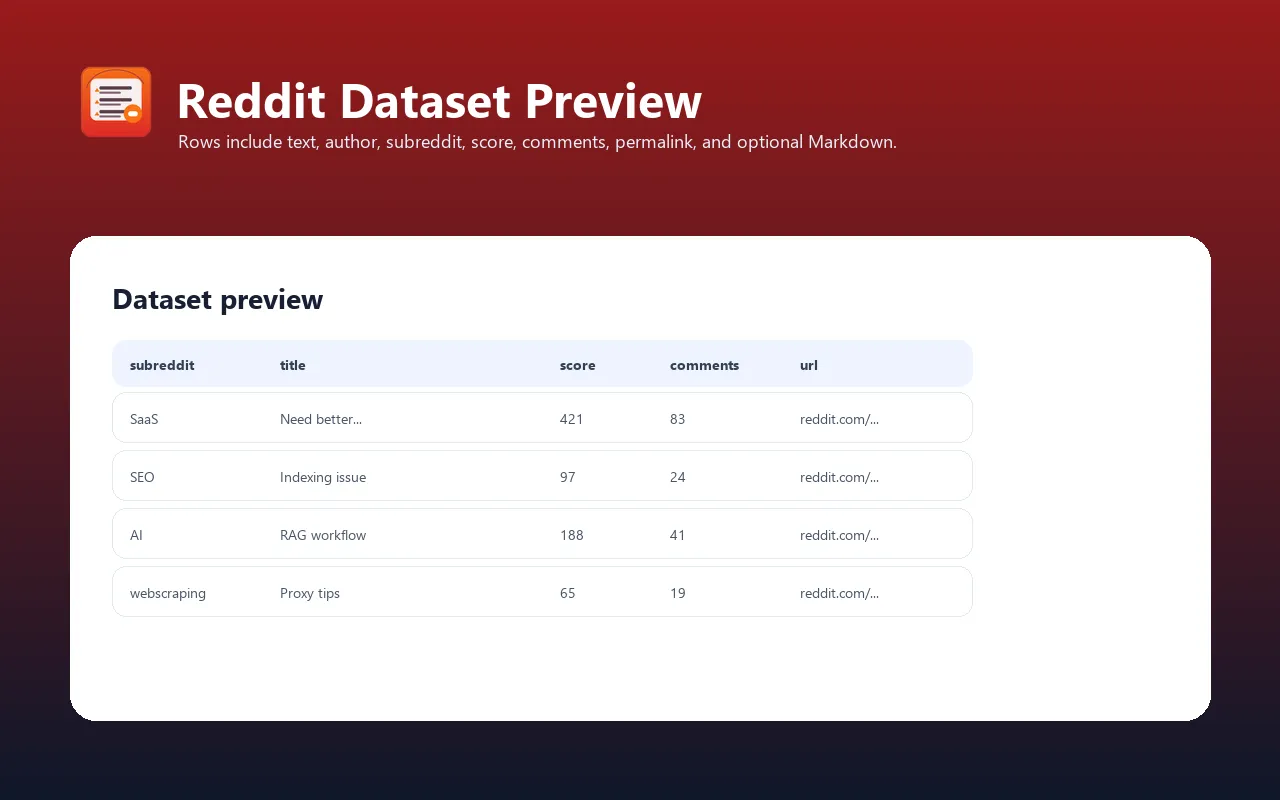
Each post is one dataset item. Field set depends on outputFormat:
full (default)
minimal
rag
Single markdown field per post, ready for vector-DB ingestion:
Output field reference
| Field | Type | Description |
|---|---|---|
id | string | Reddit post ID without the t3_ prefix. |
subreddit | string | Subreddit name. |
title | string | Post title. |
author | string/null | Reddit username when public. |
score | integer | Reddit score at fetch time. |
upvote_ratio | number/null | Upvote ratio when available. |
num_comments | integer | Comment count reported by Reddit. |
created_utc | string | UTC timestamp converted to ISO format. |
url | string/null | External URL for link posts, or null for self posts. |
permalink | string | Canonical Reddit permalink. |
selftext | string/null | Plain self-post body where present. |
selftext_markdown | string/null | Markdown body where Reddit exposes it. |
link_flair_text | string/null | Link flair label. |
author_flair_text | string/null | Author flair label. |
over_18 | boolean | NSFW marker from Reddit. |
spoiler | boolean | Spoiler marker. |
stickied | boolean | Whether the post is stickied. |
locked | boolean | Whether comments are locked. |
is_self | boolean | Whether it is a self/text post. |
is_video | boolean | Whether Reddit marks it as video. |
is_gallery | boolean | Whether gallery media is present. |
thumbnail | string/null | Thumbnail URL when available. |
media_url | string/null | Main media URL when available. |
gallery_urls | array | Gallery image URLs. |
comments | array | Present when includeComments=true; each item has author/body/score/depth. |
markdown | string/null | Present when outputFormat=rag. |
Comment extraction
Comments are optional because every post with comments requires an additional request and more parsing. Leave comments off for feed scanning. Turn them on only when the comment discussion matters.
Recommended settings:
| Goal | includeComments | maxComments | maxCommentDepth |
|---|---|---|---|
| Feed monitoring | false | 20 | 3 |
| RAG summaries | true | 20 | 2 |
| Deep thread analysis | true | 100 | 3 |
| Large historical run | false | 20 | 3 |
Deep comment trees can be noisy and expensive. For most research workflows, top-level and near-top-level comments carry enough context.
Cost estimation
Approximate prompt-sized run costs at the displayed "from" price:
| Use case | Input | Approx. cost |
|---|---|---|
| 10 posts from 2 subs, no comments | default | ~$0.03 |
| 100 posts from 5 subs, no comments | maxItems=100 | ~$0.30 |
| 100 posts with top-20 comments each | includeComments=true | ~$0.40 |
| 1,000 posts from search, RAG output | search mode, maxItems=1000 | ~$3.00 |
Billed as PPE (pay-per-event) at the Apify Store's displayed per-result price. Each delivered dataset item represents one post/result; check the live Store pricing box before large scheduled runs because Apify pricing configuration can change independently of this README.
Scheduling and automation
The most useful Reddit workflows are scheduled:
- hourly: brand crisis or launch monitoring
- daily: product category monitoring
- weekly: trend and content research
- monthly: RAG corpus refresh
Recommended Task setup:
Attach a webhook to send finished datasets to Slack, Google Sheets, BigQuery, or your own API.
Integrations
Python
JavaScript
LangChain document loader
Claude MCP / Apify MCP Server
Works out of the box. Any Claude/GPT agent using the Apify MCP Server can call this actor as a tool and pipe the output straight into its context.
Data quality checklist
Before using results for analysis:
- Filter out posts with very low
scoreif you only want meaningful discussions. - Use
skipNsfw=truefor business/brand monitoring. - Prefer
sort=newfor alerting andsort=topfor research. - Keep one source mode per run so downstream reports are easier to interpret.
- Store the
permalinkfield so analysts can inspect the original thread. - For sentiment or topic extraction, use
outputFormat=ragso the title, body, and comments stay together.
Use cases
- RAG knowledge base — scrape relevant subreddit threads into a vector DB
- Competitive intelligence — monitor mentions of your product or competitors
- Trend research — top posts of the week across 20 subreddits, one run
- Content gap analysis — aggregate questions people ask in niche subs
- Academic data collection — snapshots of subreddit discourse over time
- AI agent tooling — on-demand Reddit search as an MCP tool
- Brand safety monitoring — NSFW filter built in
- Influencer research — pull recent public submitted posts for known users
FAQ
Do I need a Reddit account or OAuth app? No. This actor uses Reddit's public .json endpoints — the exact same data Reddit serves to logged-out visitors.
Why do I need a proxy? Reddit rate-limits by IP. At small volumes you may be fine without one, but larger runs should keep the default residential proxy enabled to reduce block/rate-limit risk.
Can I get removed posts or deleted comments? No. If Reddit has removed content from the public API, this actor sees the same [deleted] placeholder. Use Pushshift for historical archives.
How fresh is the data? Live — each run hits Reddit directly. Default sort is hot which reflects the current front page at run time.
What about NSFW content? Set skipNsfw: true to filter posts marked over_18. Comment filtering is not per-comment.
Can it handle quarantined or private subreddits? Quarantined subs: partial results. Private subs: no access without OAuth.
Can I scrape comments only? Use postIds with includeComments=true for the specific threads you care about. The actor still returns the post row as the parent item.
Can I scrape Reddit profiles? Yes, use users. It fetches submitted posts for each public username.
Can I search inside one subreddit? Yes. Either set subreddits and choose a listing sort, or use Reddit search syntax such as subreddit:LocalLLaMA "fine tuning".
Why do results differ from Reddit's UI? Reddit personalizes and experiments with ranking. The actor reads public JSON endpoints at run time, so output can differ from a logged-in browser session.
Does it bypass Reddit restrictions? No. It reads public pages/data. Private, removed, deleted, or login-only content is outside scope.
Troubleshooting
| Issue | Cause | Fix |
|---|---|---|
| Empty dataset | Subreddit name typo or banned sub | Check the name on Reddit first |
HTTP 403 in logs | Reddit temporarily blocked the proxy IP | Leave proxyConfiguration on — session auto-rotates |
| Missing comments | includeComments: false | Set to true |
| Posts look truncated | outputFormat: minimal | Switch to full or rag |
| Search misses posts | Reddit search ranking/coverage varies | Monitor key subreddits directly when possible |
| Run takes too long | Comments enabled on many posts | Lower maxItems, maxComments, or comment depth |
| Duplicate topics | Same story cross-posted across subreddits | Deduplicate downstream by URL/title/permalink |
Limitations
- No OAuth-only data — private subs, user inbox, friends, subscribed feed
- No historical archives — Reddit JSON returns live data only; for posts older than a few weeks on active subs, pagination may stop early
- Comment depth capped — default 3, max 10 (Reddit itself caps around 10)
- Public-data only — no inbox, private communities, mod-only data, or logged-in recommendations
- Search is not exhaustive — Reddit search can miss posts; direct subreddit monitoring is more predictable
Privacy and compliance
This actor is designed for public Reddit content. Do not use it to collect private messages, bypass access controls, or infer sensitive personal data. For business reporting, store only the fields you need and respect deletion/removal signals from Reddit.
Changelog
- 0.1.10 (2026-04-26) — reduced first-run default to 10 posts, added quality contract, and expanded README with workflow, output, scheduling, and troubleshooting guidance.
- 0.1 (2026-04-19) — initial release: subreddits, search, users, postIds; optional comment trees; full / minimal / rag output