Web Search API for RAG — Search & Extract
Pricing
from $7.00 / 1,000 page scrapeds
Web Search API for RAG — Search & Extract
Web search API that turns Google results and public URLs into Markdown, text, or HTML for RAG and AI agents. Guide: https://konabayev.com/tools/rag-web-browser/?utm_source=apify_info&utm_medium=referral&utm_campaign=rag-web-browser
Pricing
from $7.00 / 1,000 page scrapeds
Rating
0.0
(0)
Developer
Tugelbay Konabayev
Maintained by CommunityActor stats
1
Bookmarked
19
Total users
11
Monthly active users
15 days ago
Last modified
Categories
Share
Web search API for RAG and AI agents: submit a search query or public URLs and receive source URLs, titles, clean Markdown/text/HTML, HTTP status, request status, and loadedAt in one structured dataset.
Search and extraction in one run — the default input searches one query and scrapes a small top-result sample. HTTP-first extraction with optional browser fallback for JS-heavy pages. Dataset, API, and MCP-friendly output for RAG pipelines, AI agents, and research workflows.
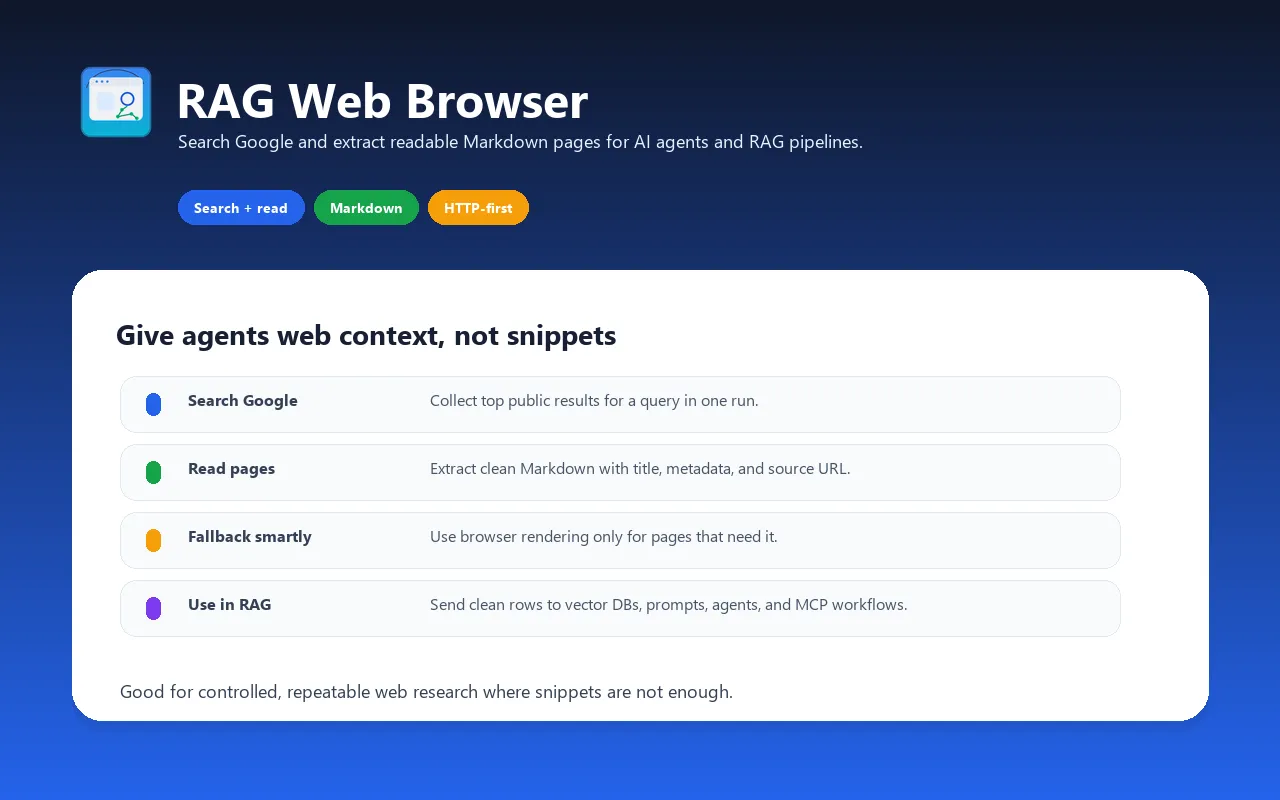

Web browser designed for AI agents, RAG pipelines, and LLM applications. Search Google or provide direct public URLs, then get clean Markdown, text, or HTML content ready to inject into prompts, vector databases, or retrieval pipelines. Use it when you need a controllable Apify API run with dataset output, scheduling, proxies, and webhooks.
Give your AI agent the ability to search the web and read public pages that are accessible to the actor — in one API call.
For implementation notes, examples, and SEO/GEO use cases, see the RAG Web Browser guide.
Search Google and Extract Web Pages as Markdown
Use this actor to search Google for any query and extract clean Markdown from the top results — all in one API call. Perfect for RAG pipelines, AI agents, and LLM applications.
Search-to-Content Workflow for RAG
Search-only workflows often return titles, URLs, and short snippets. This actor is built for the next step: opening accessible public pages, extracting readable content, and returning document-like output that can be embedded, summarized, or passed to an agent.
Works with LangChain, Claude MCP, and OpenAI
Integrate as a LangChain document loader, Claude Desktop MCP tool, or call via REST API from any framework.
Main features
- Search Google and scrape top N results in a single call
- Scrape specific URLs directly (bypass search)
- Auto-detect JavaScript-heavy pages and fall back to headless browser
- Clean content extraction via Mozilla Readability algorithm
- Output as Markdown, plain text, or clean HTML
- Google SERP proxy to reduce search blocking risk
- Lightweight: HTTP-first path keeps memory lower than browser-only scraping
- Pay-per-event pricing for successfully scraped pages
- MCP and OpenAPI compatible — works with Claude, GPT, LangChain, CrewAI
- Open for inspection — review the source code before using
Comparison: why use this Actor
| Need | This Actor | Search-only API | Manual scraping |
|---|---|---|---|
| Search and page extraction | One Apify run | Usually needs a second step | Custom pipeline required |
| LLM-ready output | Markdown, text, or HTML | Mostly snippets and result URLs | Depends on your parser |
| Scheduled research | Apify schedules and webhooks | Separate orchestration required | Separate orchestration required |
| Direct URL extraction | Supported | Often outside search scope | Supported if you build it |
| JavaScript-heavy pages | Optional browser fallback | Usually not included | Requires browser automation |
| Dataset/API workflow | Built into Apify | Depends on provider | You maintain storage and retries |
Use it when your agent or RAG pipeline needs page content, not only search-result metadata.
How to run and how it works
- You provide a search query (e.g.,
"best RAG frameworks 2026") or a URL - If search query: the actor queries Google via SERP proxy and gets top N result URLs
- Each URL is fetched using fast HTTP first (raw HTML), then Playwright browser for JS-heavy sites
- Content is extracted using Mozilla Readability, cleaned, and converted to Markdown
- Results are returned with metadata (title, description, language, URL, HTTP status)
Usage mode
The RAG Web Browser currently runs as a standard Apify Actor run.
Standard Actor run
Run the Actor via the Apify API, schedule, integrations, or manually in Console. Pass an input JSON object with your search query and settings. Results are stored in the default dataset.
This mode is best for:
- Testing and evaluation
- Batch processing (scrape many queries in sequence)
- Scheduled runs (daily news extraction, content monitoring)
- One-off research tasks
HTTP API via Actor runs
To use it from an external system, start an Actor run through the Apify API.
Why saved Tasks help production:
- Repeatable settings — save query, country, output format, and limits
- Scheduler support — run repeat research jobs on a cadence
- Webhooks — trigger downstream pipelines when results are ready
- Simple HTTP API — start runs and read datasets through Apify API
To use the Actor API:
Replace <APIFY_API_TOKEN> with your Apify API token. You can also pass the token via the Authorization HTTP header for increased security.
The /search endpoint accepts all input parameters as query strings. Object parameters like proxyConfiguration should be URL-encoded JSON strings.
Input examples
Search Google and get top 3 results as Markdown
Scrape specific URLs directly
Search with country filter and browser mode
Fast extraction (raw HTTP only, no JavaScript)
Single URL with both Markdown and text output
Input parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
query | String | — | Google search query or a direct URL. Examples: "best RAG frameworks", "https://docs.apify.com" |
urls | Array | — | List of specific URLs to scrape (alternative to query) |
maxResults | Integer | 3 | Number of Google search results to scrape (1–20) |
outputFormat | String | "markdown" | Output format: "markdown", "text", "html", or "both" (markdown + text) |
scrapingTool | String | "auto" | Scraping method: "auto" (recommended), "raw-http" (fastest), "browser" (JavaScript support) |
googleCountry | String | "us" | Country for Google results (ISO 3166-1 alpha-2 code) |
proxyConfiguration | Object | Google SERP | Proxy settings. Default uses Google SERP proxy for search. |
Output format
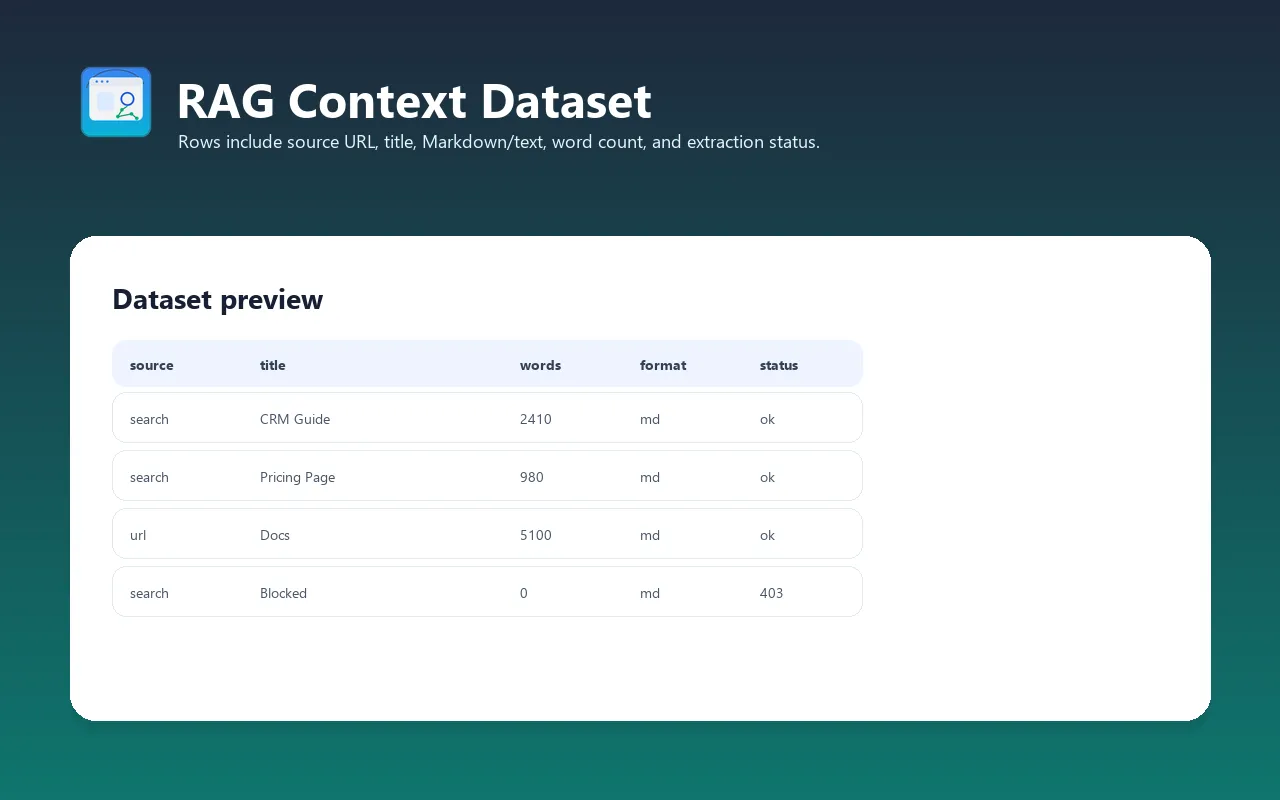
Each item in the dataset contains:
| Field | Type | Description |
|---|---|---|
url | String | Final page URL (after redirects) |
title | String | Page title (from Readability or meta tags) |
description | String | Page meta description or Open Graph description |
languageCode | String | Detected content language (e.g., "en") |
markdown | String | Extracted content as Markdown (if outputFormat includes markdown) |
text | String | Extracted content as plain text (if outputFormat includes text) |
httpStatusCode | Integer | HTTP response status code |
requestStatus | String | "handled" (success) or "failed" |
loadedAt | String | ISO 8601 timestamp of when the page was loaded |
searchTitle | String | Google search result title (only for search queries) |
searchDescription | String | Google search snippet (only for search queries) |
searchUrl | String | Original Google result URL (only for search queries) |
Example output (search query)
Example output (direct URL)
Integration with LLMs
RAG Web Browser is designed for easy integration with LLM applications, AI agents, OpenAI Assistants, GPTs, and RAG pipelines via function calling.
OpenAPI schema
Use the OpenAPI schema to integrate with any LLM that supports function calling:
- OpenAPI 3.1.0 schema — for modern LLM platforms
- The schema contains all available query parameters, but only
queryis required
Tip: Remove optional parameters from the schema to reduce token usage and minimize hallucinations in function calling.
Apify MCP Server (Claude, AI agents)
The actor works with AI agents via the Apify MCP Server. Use it as a web browsing tool in Claude Desktop, Claude Code, or any MCP-compatible AI framework.
Step-by-step setup for Claude Desktop:
- Install the Apify MCP Server package
- Add to your Claude Desktop MCP configuration (
claude_desktop_config.json):
- Restart Claude Desktop
- Ask Claude: "Search the web for 'best RAG frameworks 2026' and summarize the top results"
- Claude will call the RAG Web Browser actor and return summarized content
OpenAI Assistants
For assistant workflows that need an external web-research function, expose RAG Web Browser through the Apify API:
- Create an Assistant in the OpenAI Platform
- Add a function tool with the RAG Web Browser OpenAPI schema
- Configure the function to start the Actor run or call a saved Task
- Use the returned dataset items as context for answers, summaries, or retrieval
For detailed instructions, see OpenAI Assistants integration in Apify docs.
OpenAI GPTs (Custom Actions)
Add web browsing to your GPTs:
- Go to My GPTs → Create a GPT
- Under Actions → Create new action
- Set Authentication to API key, Auth Type Bearer
- Paste the OpenAPI schema in the Schema field
- Save and test — your GPT can now search Google and extract web content
Python integration
JavaScript/TypeScript integration
LangChain integration
cURL
Performance optimization
Scraping tool selection
The most important performance decision is selecting the right scraping method:
| Method | Speed profile | JavaScript | Best for |
|---|---|---|---|
raw-http | Fastest path | No | Static sites, blogs, docs, Wikipedia |
browser | Slower path | Yes | SPAs, React/Vue apps, dynamic content |
auto | Adaptive | Auto-detect | Mixed workloads (recommended default) |
Recommendation: Use raw-http when you know your target sites are static. Use auto when scraping unknown URLs from Google search results.
Tips for predictable runs
- Use
raw-httpscraping tool for static websites when JavaScript rendering is not needed - Reduce
maxResults— fewer pages usually means faster response - Keep batches small — fewer pages keep Actor run latency predictable
- Set a timeout — the actor returns partial results if time runs out, so your LLM gets at least some context
Cost vs. throughput optimization
For heavier runs, tune memory and request limits:
- Default memory: Good starting point for search plus a small page sample.
- More memory: Useful for larger browser-mode runs or higher concurrency.
- Lower
maxResults: Best first lever when an agent needs quick context instead of a large crawl.
Create a Task in Apify Console to save tuned run settings for your specific use case.
Use cases
RAG pipelines — feed vector databases with fresh web content
Search a topic and inject the results into your vector store for retrieval-augmented generation:
AI agents — web browsing tool
Give your AI agent the ability to search and read the web. Works with any agent framework that supports function calling or MCP.
Research automation
Search a topic and get structured content from multiple sources. Perfect for literature reviews, competitive analysis, and market research.
Content monitoring
Track changes on specific pages by scraping them on a schedule. Compare Markdown output between runs to detect content changes.
Knowledge base building
Extract and index documentation sites. Combine with a vector database to build a searchable knowledge base from any public website.
Competitive analysis
Scrape competitor pages, extract their content, and analyze messaging, features, and positioning.
News aggregation
Search for breaking news on a topic and get clean article text — no ads, no navigation, just the content.
Cost estimation (PPE pricing)
This actor uses Pay-Per-Event pricing:
| Event | Description |
|---|---|
page-scraped | Each page successfully scraped and content extracted |
On 2026-07-14 the result event is $0.01 per stored page on FREE and falls to $0.007 on GOLD and higher tiers, plus Apify's $0.00005 synthetic start event. The Store Pricing panel is authoritative for current tiers. As a planning rule, multiply the expected successfully extracted page count by the current event price and include the start event.
Start with the default small sample to evaluate output quality before larger runs. For recurring workloads, save a Task with your preferred query, country, output format, and result limit.
FAQ
When should I use this instead of a crawler?
Use this actor when you want a search-to-content workflow: a query or short URL list in, LLM-ready Markdown/text/HTML out. Use a full website crawler when you need broad site traversal, sitemap-style crawling, or hundreds of pages from one domain.
Can I use this with Claude / ChatGPT / other AI assistants?
Yes. The actor works with:
- Claude Desktop via Apify MCP Server
- OpenAI GPTs via Custom Actions (OpenAPI schema)
- OpenAI Assistants via function calling
- LangChain, CrewAI, AutoGen via Apify Python/JS client
- Any framework that supports HTTP APIs or MCP
Does it handle JavaScript-rendered pages (SPAs)?
Yes. Set scrapingTool to "auto" (default) and the actor will automatically detect pages that need JavaScript rendering and use a headless Chromium browser. Or set scrapingTool to "browser" to always use the browser.
What about anti-scraping protections (Cloudflare, CAPTCHAs)?
The actor uses Apify proxy infrastructure for Google search and target-page requests. Some sites with aggressive bot detection, login walls, paywalls, or CAPTCHA protection may still block requests. The actor returns a "failed" status for pages it cannot access.
Can I search in languages other than English?
Yes. Set the googleCountry parameter to any ISO 3166-1 alpha-2 country code (e.g., "de" for Germany, "jp" for Japan, "br" for Brazil). Google will return localized results.
What's the maximum number of results per query?
20 results per search query (Google's limit). For more coverage, run multiple queries with different search terms.
How do I use this in a RAG pipeline?
- Call the actor with your search query
- Get Markdown content from the results
- Split the Markdown into chunks (sentence-level or paragraph-level)
- Embed chunks with your embedding model (OpenAI, Cohere, etc.)
- Store in your vector database (Pinecone, ChromaDB, Weaviate, etc.)
- Query the vector store during LLM inference for relevant context
Is the output compatible with OpenAI / Anthropic token limits?
Yes. Markdown output is compact and token-efficient. A typical web page produces 1,000–5,000 tokens of Markdown. You can control output size by adjusting maxResults and using text format (slightly more compact than Markdown).
Can I run this on a schedule?
Yes. Set up a Schedule in Apify Console to run the actor at any interval — daily, hourly, or custom cron expressions.
Troubleshooting
Google search returns 0 results
- Cause: Google may temporarily rate-limit the SERP proxy IP
- Fix: The actor retries automatically (3 attempts with backoff). If it still fails, try again in a few minutes.
- Alternative: Provide direct URLs via the
urlsinput instead of using search.
Page content is empty or very short
- Cause: The page requires JavaScript to render content (SPA)
- Fix: Set
scrapingToolto"browser"or"auto"to enable Playwright rendering - Alternative: Some pages (login walls, paywalled content) simply can't be scraped
Timeout errors
- Cause: Target page is slow to respond or has heavy JavaScript
- Fix: Increase the timeout, or reduce
maxResultsto scrape fewer pages per query - Alternative: Use
raw-httpscraping tool for faster (but JavaScript-less) extraction
Markdown output has formatting issues
- Cause: Complex page layouts (multi-column, heavy CSS) may not convert cleanly
- Fix: This is expected for non-article pages. The Readability algorithm works best on article-style content (blogs, news, documentation).
- Alternative: Use
textoutput format for a simpler, cleaner extraction.
"Failed" status for some pages
- Cause: Cloudflare protection, login walls, IP blocks, or the page doesn't exist
- Fix: Try using residential proxy configuration. Some pages simply can't be scraped.
Validation evidence and responsible use (2026-07-14)
Validation on 2026-07-14 establishes a bounded retrieval contract:
- Google's policy on machine-generated traffic remains authoritative for Google Search access.
- RFC 9309 defines the Robots Exclusion Protocol; target-site terms, copyright, privacy, and access controls also apply.
- Results retain source URLs, request/HTTP status, content fields, and
loadedAtso downstream systems can cite and refresh the original page. - Strict Actor QA validates schemas, links, metadata, Docker configuration, and PPE declarations before release.
This evidence does not grant republication rights or guarantee access, extraction completeness, search position, traffic, or AI citation.
Support
Send the run ID, sanitized query or public URL, selected extraction mode, expected content, observed status, and visible error. Do not send cookies, credentials, paywalled content, or private documents.
Limitations
- Google Search may rate-limit; the actor retries automatically (3 attempts with exponential backoff)
- Some websites block scraping entirely (Cloudflare protection, CAPTCHA, login walls)
- JavaScript-heavy SPAs may require
"browser"scraping mode (slower but more reliable) - Maximum 20 search results per query (Google's limit)
- Content extraction works best on article-style pages; complex layouts (dashboards, apps) may lose formatting
- Direct URL scraping uses datacenter proxy by default; some sites may require residential proxy
Changelog
v1.0 (2026-03-29)
- Initial release
- Google Search + page scraping in one call
- Auto-detect JS-heavy pages with Playwright fallback
- Readability + html2text for clean Markdown extraction
- Google SERP proxy support with 3-attempt retry
- Dual proxy strategy (SERP for Google, datacenter for target pages)
- PPE pricing
- Supports Markdown, plain text, HTML, and combined output formats
- Concurrent scraping (up to 3 pages in parallel)
Related Actors
- Website Content Crawler — Crawl websites and extract Markdown for RAG/LLMs
- Article Extractor — Extract clean article text from any URL
- Website Tech Stack Detector — Identify 80+ technologies on any website
- Google Maps Lead Extractor — Extract business leads with emails from Google Maps
- JustDial Scraper & Lead Extractor — Scrape India business data from JustDial.com
See all actors: apify.com/tugelbay