Telegram Channel Scraper — No Bot Token, No Phone Login
Pricing
from $1.20 / 1,000 telegram posts
Telegram Channel Scraper — No Bot Token, No Phone Login
Telegram scraper for public channel posts via t.me/s/, with no bot token, phone login, or API credentials. Extract text, views, dates, media URLs, and links. Guide: https://konabayev.com/tools/telegram-posts-scraper/?utm_source=apify_info&utm_medium=referral&utm_campaign=telegram-posts-scraper
Pricing
from $1.20 / 1,000 telegram posts
Rating
0.0
(0)
Developer
Tugelbay Konabayev
Maintained by CommunityActor stats
0
Bookmarked
58
Total users
5
Monthly active users
10 days ago
Last modified
Categories
Share
Telegram scraper for public channels: submit one or more channel names or t.me/s/ URLs and receive post IDs, URLs, UTC dates, text, views, media, forwarded-from data, and link previews without a bot token or phone login.
Fast first run — the default input returns a small public-channel sample from
t.me/s/<channel>preview pages. No Telegram account or bot token required for public preview pages. Telegram may still limit or hide some channels. Built for monitoring and RAG ingestion — start with 10-25 posts, verify channel coverage, then scale to ongoing channel intelligence jobs.
For implementation notes, examples, and Telegram monitoring workflows, see the Telegram Posts Scraper guide on Konabayev.com.

Scrape posts from public Telegram channels without phone numbers, 2FA, OAuth, bot tokens, or spending weeks on MTProto client libraries. This actor wraps Telegram's own t.me/s/ SEO preview pages behind a single Apify-platform input with proxy rotation, pagination, filters, and a clean canonical output schema.
Perfect for brand monitoring, channel intelligence, AI RAG pipelines, crypto/news tracking, research datasets, and competitive analysis across one-person blogs to million-subscriber broadcast channels. Returns structured JSON with post text, view counts, timestamps, media URLs, link previews — plus an optional clean Markdown format that plugs straight into LangChain document loaders or Claude MCP tools.
How to run and how it works
- Start with one public channel and 10-25 posts.
- Verify post URLs, UTC
date, text/media coverage, views, and any block/error state. - Scale or schedule only after the public preview coverage fits the monitoring workflow.
Three input sources, used together in one run:
channels— list of channel handles (without@ort.me/). Scraper walkst.me/s/<handle>newest-first, paginating via?before=<post_id>untilmaxItemsor end of feed. This is the main mode.postUrls— list of full post URLs (e.g.https://t.me/durov/478). Each URL fetches one post with its OG metadata and embedded widget data.search— channel handle lookup viat.me/s/<query>. Useful when you know a likely public handle but want to run it through the same preview parser.
Posts are pushed to the dataset incrementally — even if the run is aborted, everything fetched so far is already stored.
What "public" means on Telegram: every channel with previews enabled. The channel admin sets this toggle in Telegram → Channel Settings. Most news, crypto, and broadcast channels have previews on. Some private or sensitive ones don't — we detect this case and surface it cleanly (empty dataset with a warning log).
Why use this instead of alternatives?
| Feature | Telegram Posts Scraper | Telethon (self-host) | Telegram Bot API | Other Apify scrapers |
|---|---|---|---|---|
| Auth required | None | Phone number + 2FA + SIM | Bot token + channel admin | Varies |
| Can scrape without joining channel | Yes (public preview) | Yes (after join) | Only if bot is admin | Varies |
| IP rotation | Yes — Apify proxy | Manual | N/A | Varies |
| Output formats | full / minimal / rag-markdown | Custom code | Raw objects | full only |
| Link preview extraction | Yes, structured | Manual | Manual | Rare |
| View counts + dates | Yes | Yes | Not directly exposed | Varies |
| Pagination | Automatic via ?before=<id> | Manual | Manual | Varies |
| MCP compatible | Yes (PPE = agent-friendly) | No | No | Rarely |
| Pay model | PPE — only what you scrape | Free but self-host | Free but bot must be admin | Varies |
Key advantage: no Telegram account. No SIM risk. No api_id/api_hash registration. No 2FA loops. Just channel handles in, structured posts out.
Input examples
Read two channels (default prefill)
Monitor a crypto announcement channel since a specific date
Fetch a specific viral thread + related posts
Paginate deep into a channel's history
Find a channel by topic
Input parameters
| Field | Type | Default | Description |
|---|---|---|---|
channels | array[string] | ["durov", "telegram"] | Channel handles (no @, no t.me/). Most common mode. |
postUrls | array[string] | [] | Specific https://t.me/<channel>/<id> URLs to fetch. |
search | string | — | Channel-name lookup. Telegram returns the top-matching public channel. |
maxItems | integer | 10 | Cap on total posts across all sources. Each is one PPE event. |
before | integer | — | Start at posts OLDER than this post ID. Default is newest first. |
outputFormat | enum | full | full / minimal / rag. See Output format section. |
minViews | integer | 0 | Drop posts below N views. Good for "only viral posts" runs. |
sinceIso | string | — | ISO-8601 (2026-01-01T00:00:00Z). Older posts are skipped. |
proxyConfiguration | object | {useApifyProxy: true} | Apify proxy group. Default auto-selects. |
Output format
Full (default)
Every post includes:
Minimal
Keeps: channel, post_id, url, date, text, views, forwarded_from, photos, video_url, link_preview.
RAG (Markdown)
Each post becomes one Markdown block with post metadata, text, and link preview — paste directly into a vector DB.
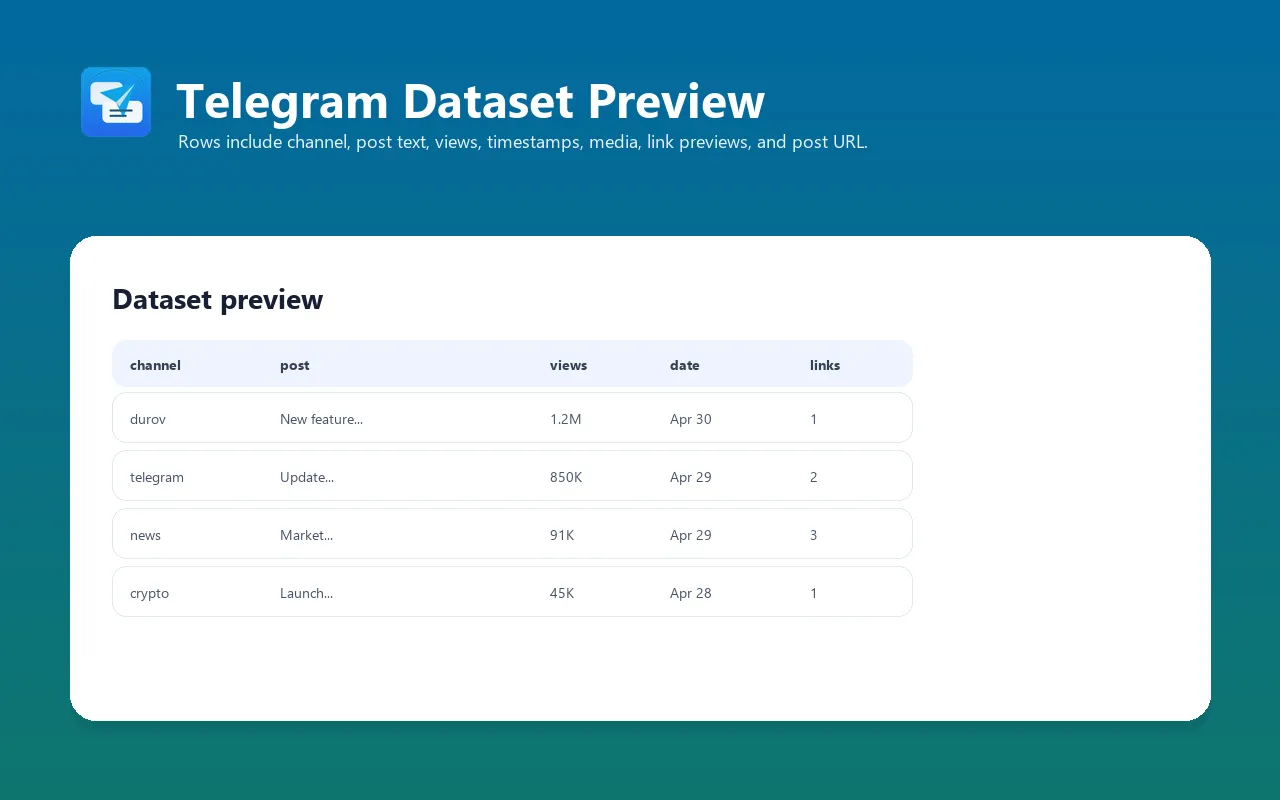
Output fields
| Field | Type | Description |
|---|---|---|
channel | string | Handle without @, e.g. durov. |
post_id | integer | Numeric ID within channel (used for pagination). |
url | string | Canonical t.me/<channel>/<id>. |
date | string (ISO-8601) | When posted (UTC). |
text | string|null | Post body. <br> converted to \n, all formatting stripped. |
views | integer|null | Parsed from 1.5K/2M notation to absolute integer. |
forwarded_from | string|null | Original author if this is a forward. |
reply_to_url | string|null | URL of post being replied to, if any. |
photos | array[string] | CDN URLs for photo attachments. |
video_url | string|null | Direct video URL (may be time-limited CDN link). |
has_voice | boolean | True if post contains a voice message. |
document_url | string|null | Direct document URL for file uploads. |
link_preview | object|null | {url, site_name, title, description, image_url} if post includes a link preview card. |
Integrations
Python — quick RAG ingest
JavaScript/Node
MCP (Claude / GPT agents)
Expose this actor as a tool via the Apify MCP Server (mcp.apify.com). Your agent gets a Telegram-read tool with no credentials to manage:
LangChain / LlamaIndex
n8n
Use the community node @apify/n8n-nodes-apify → Run Actor operation:
- Actor:
tugelbay/telegram-posts-scraper - Input JSON:
{"channels": ["{{ $json.channel }}"], "maxItems": 20, "outputFormat": "full"} - Output dataset items are available as
$jsonin downstream nodes.
Make
Use the Apify app (built-in) → Run an Actor module:
- Select actor:
tugelbay/telegram-posts-scraper - Input: map
channels,maxItems,outputFormatfields - Results are passed to next modules as JSON array.
Zapier
Use Apify action app → Run Actor:
- Actor:
tugelbay/telegram-posts-scraper - Input fields: populate
channels(comma-separated),maxItems,outputFormat - Output: dataset items feed into your Zap (email, Slack, Sheets, etc.).
Use cases
- Brand & competitor monitoring — watch a competitor's announcement channel, alert on keywords.
- Crypto signal tracking — monitor shilling channels, extract mentioned token tickers via regex over
text. - AI news feed — aggregate AI/ML channels, dedupe, feed to LLM-summary pipelines.
- Channel research for ads — before sponsoring a channel, pull last 100 posts, measure view decay, engagement.
- Internal KB from public team channel — teams that use public Telegram for announcements can ingest their own channel into Notion/Confluence.
- Local news aggregation — hundreds of Telegram channels for every country/city — aggregate by location.
- Dataset building — label corpus for abuse detection, sentiment analysis, language identification.
- Academic research — social-network effects without needing Telegram developer registration.
- Journalism leads — monitor OSINT channels during breaking events.
- Public figure tracking — read every post from a politician/CEO/founder channel as it arrives.
Cost estimation
| Scenario | Posts | Cost (FREE tier) | Cost (GOLD tier) |
|---|---|---|---|
| Daily 20-post feed from 5 channels | 100/day | $0.20/day | $0.12/day |
| Monthly digest — 500 posts across 10 channels | 500 | $1.00 | $0.60 |
| One-off research dump — 10,000 posts | 10,000 | $20.00 | $12.00 |
| RAG cold-start — 100 channels × 200 posts | 20,000 | $40.00 | $24.00 |
Live PPE pricing verified on 2026-07-14 is $0.002 per post on FREE and $0.0012 per post on GOLD and higher tiers, plus the small Actor-start event.
Compare to running your own Telethon instance: $5–10/mo proxy + SIM card risk + ~40 hours maintenance/year.
Free Apify plan limits. Non-paying Apify accounts are capped at 100 posts per run and 300 posts per month — a graceful guardrail against free-credit farming. Your run ends cleanly with a status message when the monthly allowance is reached. Paid Apify accounts are not subject to these free-tier caps (the general per-run
maxItemsceiling still applies).
FAQ
Do I need a Telegram account? No. No account, no phone, no 2FA. The actor reads public channel previews that Telegram serves to every indexing bot.
What about private channels? Private channels and channels with "web previews" disabled return empty. No way around that without a real account — which we explicitly don't do.
Can it read comments? Only when comments are public widgets on the channel post (rare). Private comment sections require account login.
How fresh is the data? Real-time. Each run hits Telegram live — you get the same posts a website visitor sees.
What rate limits apply? In validation, 40 rapid requests to t.me/s/ returned 200. Apify proxy handles any edge-case throttling. Heavy runs (>10k posts) should use RESIDENTIAL proxy group for safety.
Is this legal? Channel previews are public by design (they're indexed by Google). Standard web-scraping compliance applies — respect channel owners' rights, honor takedown requests, don't re-publish copyrighted material.
What languages? All. Text is extracted as-is. Telegram channels exist in every major language; the actor returns whatever bytes Telegram serves.
Why t.me/s/ and not the Bot API? Bot API requires the bot to be a channel admin. t.me/s/ requires nothing. Different access model — we chose simplicity.
Can I get channel subscriber count? Not currently. t.me/s/<handle> doesn't expose it. Could add via t.me/<handle> in a future version if requested.
Troubleshooting
| Issue | Cause | Fix |
|---|---|---|
| 0 posts returned for a channel | Channel is private or has previews disabled | Confirm t.me/s/<channel> in a browser — if it shows no posts, this channel isn't scrapeable publicly. |
| Some posts missing link previews | Telegram doesn't always generate them | Nothing to fix — link_preview is null when Telegram doesn't emit the card. |
| Photo URLs expire after a few hours | Telegram CDN signs media URLs | Download media during the run, don't rely on URLs later. Or hit the page again when needed. |
| Pagination stops early | Hit oldest post in preview window | Telegram only shows ~100–200 posts in /s/ view for most channels. For deeper history, pass lower before IDs or use a Telethon account. |
| Rate limit / slowdown | Heavy burst from one IP | Use RESIDENTIAL proxy group or lower concurrency. |
Validation evidence and Telegram terms (2026-07-14)
Validation on 2026-07-14 preserves the public-preview boundary:
- Telegram documents public post widgets, which are based on public post URLs.
- Telegram's current Terms of Service remain authoritative; channel rights, privacy, copyright, and applicable law also apply.
- Each result retains channel, post ID, source URL, and UTC
dateso downstream users can verify the public source and snapshot time. - Strict Actor QA validates schemas, metadata, links, Docker configuration, and PPE declarations before release.
This evidence does not grant access to private channels, recover deleted posts, verify authorship, or guarantee rankings, reach, or AI citations.
Limitations
- No private channels, no group chats — only channel public previews.
- No comments — Telegram renders those client-side.
- Media URLs are CDN-signed and expire; download during the run if you need persistence.
- No reactions count — not in the public preview HTML.
- Subscriber counts not yet extracted (future work).
- Some channels have previews limited to last 100 posts — deeper history requires account-based access (out of scope).
Changelog
- 0.1.24 (2026-07-02) — Removed a dead
telegram-postcharge call left over from an earlier pricing draft; billing is unchanged (it already runs on theapify-default-dataset-itemPPE event viapush_data). - 0.1 (2026-04-24) — Initial release. Full / minimal / RAG formats. Pagination via
?before=. Filters by views + date. MCP-compatible PPE pricing.
Support & Feedback
If this actor saves you time, please leave a review on its Store page — it takes under a minute and is the main trust signal that helps other users find a reliable tool.
Hit a bug or missing a feature? Open a ticket on the Actor's Issues tab — issues are typically answered within 24-48 hours and fixes ship fast.