AI Context Scraper
Pricing
from $70.00 / 1,000 results
AI Context Scraper
AI Context Scraper is a production-grade Apify Actor that gathers high-quality coding context from the Web, GitHub, and StackOverflow for AI agents and RAG systems. It uses NVIDIA Nemotron 3 Super to synthesize documents, code snippets, and patterns into actionable implementation guidance.
Pricing
from $70.00 / 1,000 results
Rating
0.0
(0)
Developer
Varun Chopra
Maintained by CommunityActor stats
0
Bookmarked
3
Total users
1
Monthly active users
a month ago
Last modified
Categories
Share
AI Context Scraper — Production-Grade Developer Knowledge Engine
![]()
Overview
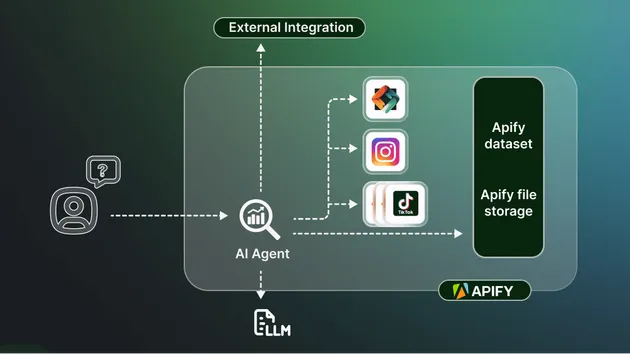
A production-grade Apify Actor that intelligently compiles high-quality coding context for AI agents, developer copilots, and engineering RAG systems. Transforms any coding task into structured, LLM-optimized context with documentation, code examples, implementation patterns, and best practices.
Powered by NVIDIA Nemotron 3 Super (120B) via OpenRouter for LLM synthesis.
🚀 Quick Start
Or call via the Apify Console.
✅ Production Verified
The actor has been battle-tested with real-world queries. Here are actual metrics from a live run:
| Metric | Value |
|---|---|
| Search queries executed | 12 |
| Sources discovered | 5 |
| Pages crawled | 4 |
| Code snippets extracted | 92 |
| Critical context chunks | 11 |
| StackOverflow answers | 4 |
| LLM tokens used | 8,471 |
| Total execution time | 112s |
| Errors | 0 |
🔑 Key Features
Multi-Source Knowledge Mining
- Web Search: DuckDuckGo (via
ddgs) with documentation prioritization and rate-limited timeouts - GitHub Intelligence: Repository and code search with star-based ranking
- StackOverflow Q&A: High-score accepted answers from the developer community
- Documentation Priority: Boosted ranking for official docs (Python, AWS, FastAPI, etc.)
LLM RAG Synthesis
- Model:
nvidia/nemotron-3-super-120b-a12b:free(configurable) - Actionable Guidance: Synthesizes gathered context into implementation-ready code with open questions
- Automatic Prompting: Builds token-optimized context prompts with code snippets, patterns, and SO answers
- Graceful Degradation: If the LLM call fails, the pipeline safely returns raw structured context
Advanced Intelligence
- Semantic Relevance Filtering:
sentence-transformers/all-MiniLM-L6-v2embeddings for precision ranking - Relevance Bucketization: Context classified as Critical / Helpful / Noise (noise dropped)
- Implementation Pattern Detection: Automatically identifies auth, caching, async, database patterns
- Content Deduplication: MinHash/shingling-based near-duplicate removal
- Code Quality Scoring: Ranks snippets by completeness, relevance, and documentation
Enterprise & Security
- SSRF Protection: CIDR-based private IP blocking (RFC 1918 + IPv6 link-local)
- Input Sanitization: Pattern-based injection detection (script tags, eval, data URIs)
- Secret Redaction: Automatic redaction of tokens/keys in logs
- Caching Layer: Apify KV store with monotonic-clock TTL (immune to container clock skew)
- Observability: Per-phase timing, relevance buckets, cache hit rates, error tracking
📊 Output Structure
⚙️ Configuration
Input Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
task | string | (required) | Coding task description |
max_sources | integer | 10 | Maximum sources to scrape (3–50) |
allowed_domains | array | [] | Domain whitelist (empty = all) |
include_github | boolean | true | Enable GitHub repository mining |
include_github_code_search | boolean | true | Enable authenticated GitHub code search |
github_token | string | null | GitHub token (or GITHUB_TOKEN env var) |
github_code_languages | array | [] | Target languages for code search |
include_stackoverflow | boolean | true | Enable StackOverflow Q&A mining |
max_code_snippets | integer | 20 | Maximum code snippets to return (1–100) |
enable_cache | boolean | true | Enable caching for faster repeated runs |
chunk_size | integer | 500 | Token limit per LLM chunk (100–2000) |
enable_llm_synthesis | boolean | true | Enable LLM-powered context synthesis |
openrouter_api_key | string | null | OpenRouter API key (or OPENROUTER_API_KEY env var) |
openrouter_model | string | nvidia/nemotron-3-super-120b-a12b:free | Model ID for LLM synthesis |
Environment Variables
| Variable | Required | Description |
|---|---|---|
OPENROUTER_API_KEY | Yes (for LLM) | OpenRouter API key. Can also be passed as input. |
GITHUB_TOKEN | No | GitHub personal access token for code search. |
Set via Apify secrets:
🏗️ Architecture
Module Structure
Pipeline Flow
🧪 Testing
Test Coverage
| Module | Coverage |
|---|---|
deduplicator.py | 100% |
metrics.py | 100% |
exceptions.py | 100% |
pattern_detector.py | 100% |
llm_synthesizer.py | 99% |
chunker.py | 99% |
security.py | 99% |
cache_manager.py | 99% |
extractor.py | 97% |
formatter.py | 96% |
orchestrator.py | 83% |
| Total | 77% |
Test Modules
| File | Tests | Covers |
|---|---|---|
test_security.py | 79 | SSRF protection, injection detection, secret redaction |
test_metrics.py | 55 | Phase timing, counters, finalize, reset |
test_cache_manager.py | 54 | TTL expiry, disabled mode, KVS error handling |
test_orchestrator.py | 36+ | Pipeline run, error fallbacks, static helpers |
test_actor_input.py | 27 | Pydantic schema, all boundary values |
test_llm_synthesizer.py | 34 | Retry logic, prompt building, structured output |
test_extractor.py | 65 | HTML extraction, snippet detection, edge cases |
test_formatter.py | 66 | Output structure, dedup, relevance buckets |
test_deduplicator.py | 45 | Shingling, Jaccard similarity, determinism |
test_chunker.py | 27 | Token-aware chunking, code block handling |
test_pattern_detector.py | 25 | Auth, async, caching, DB pattern detection |
test_search.py | 35 | Query expansion, rate limiting, mocked DDGS |
🛠️ Deployment
Build & Push
Docker Build (local)
The Dockerfile pre-downloads the sentence-transformers model during build so cold starts are fast.
📈 Performance
- Async Architecture: Concurrent crawling with semaphore limits
- Smart Caching: Task-level caching with monotonic-clock TTL (immune to container clock drift)
- Batch Processing: Embeddings computed in batches for efficiency
- Rate Limiting: Configurable requests/second with sleep-outside-semaphore optimization
- Timeout Protection:
asyncio.wait_for()on all external calls - Broad Error Recovery: Catches 8 exception types without crashing the pipeline
🔒 Security
- SSRF Protection:
ipaddressmodule CIDR checks against all RFC 1918, loopback, link-local, and IPv6 private ranges - Input Validation: Pydantic models with strict typing + regex-based injection detection
- Secret Redaction: Automatic redaction of
ghp_*,sk-or-v1-*,Bearer *tokens in logs - Content Sanitization: readability-lxml for safe HTML parsing
- SEO Spam Filtering: Multi-keyword detection (sponsored, affiliate, promo, etc.)
- Domain Whitelisting: Optional domain restrictions
- API Key Validation: Format checks with suspicious pattern detection
📦 Dependencies
| Package | Purpose |
|---|---|
apify | Actor runtime |
httpx | Async HTTP client |
beautifulsoup4 | HTML parsing |
readability-lxml | Content extraction |
ddgs | DuckDuckGo search |
markdownify | HTML → Markdown |
sentence-transformers | Semantic embeddings |
tiktoken | Token counting |
pydantic | Input validation |
rapidfuzz | Lexical similarity fallback |
🎯 Use Cases
- AI Coding Agents: Power your coding agent with real-time context about libraries, patterns, and best practices
- Developer Copilots: Provide your IDE extension with rich, structured coding context
- RAG Systems: Build retrieval-augmented generation pipelines with curated developer knowledge
- Engineering Onboarding: Generate comprehensive learning materials for new team members
- Code Review Assistance: Fetch implementation patterns and best practices to guide reviews
📝 License
MIT License — see LICENSE file for details.
🤝 Contributing
Contributions welcome! See CONTRIBUTING.md for guidelines.
Built for production use by AI infrastructure teams.
Actor ID: 2OBJzyOtx1FyGGt2f | Latest Build: 0.1.24 | Model: NVIDIA Nemotron 3 Super | Tests: 534 passing | Coverage: 77%