Phantom.js Scraper
DeprecatedPricing
Pay per usage
Phantom.js Scraper
DeprecatedPhantomJS is 6 to 10 times faster than puppeteer per Compute Unit. Sends an email when the task is complete. The input screen has been improved. Note: PhantomJS is no longer being developed and might be detected and blocked by websites.
Pricing
Pay per usage
Rating
0.0
(0)
Developer
Barry Schneider
Maintained by CommunityActor stats
1
Bookmarked
59
Total users
3
Monthly active users
5 years ago
Last modified
Categories
Share
MSIH PhantomJS Crawler for Apify
- crawls 6 to 10 times more pages than puppeteer per Compute Unit
- send email when crawl is complete
- improved input screen
This uses the PhantomJS headless browser to recursively crawl websites and extract data from them using front-end JavaScript code. PhantomJS is no longer being developed by the community and might be detected and blocked by websites. This crawler is based on the Apify Legacy PhantomJS Crawler.
Overview
This actor provides a web crawler that enables the scraping of data from any website using the primary programming language of the web, JavaScript.
In order to extract structured data from a website, you only need two things.
-
First, tell the crawler which pages it should visit (see Start URLs and Pseudo-URLs) and
-
second, define a JavaScript code that will be executed on every web page visited in order to extract the data from it (see Page function).
The crawler is a full-featured web browser which loads and interprets JavaScript and the code you provide is simply executed in the context of the pages it visits. This means that writing your data-extraction code is very similar to writing JavaScript code in front-end development, you can even use any client-side libraries such as jQuery or Underscore.js.
The crawler repeats the following steps:
- Add each of the Start URLs to the crawling queue.
- Fetch the first URL from the queue and load it in the virtual browser.
- Execute Page function on the loaded page and save its results.
- Find all links from the page using Clickable elements CSS selector. If a link matches any of the Pseudo-URLs and has not yet been enqueued, add it to the queue.
- If there are more items in the queue, go to step 2, otherwise finish.
This process is depicted in the following diagram. Note that blue elements represent settings or operations that can be affected by crawler settings. These settings are described in detail in the following sections.
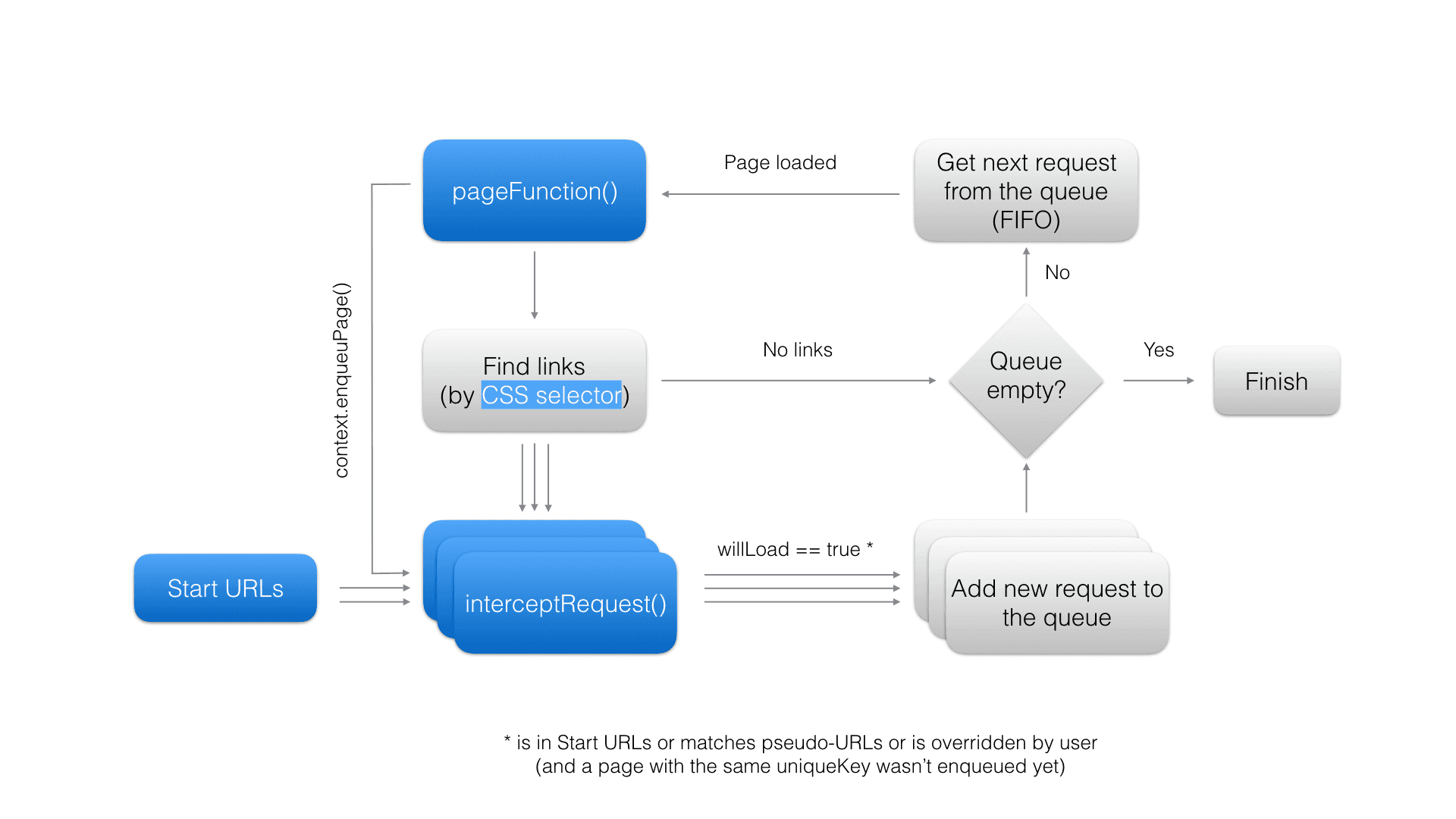
Note that each crawler configuration setting can also be set using the API. The corresponding property names and types are described in the Input schema section.
Start URLs
The Start URLs (startUrls) field represent the list of URLs of the first pages that the crawler will open.
Optionally, each URL can be associated with a custom label that can be referenced from
your JavaScript code to determine which page is currently open
(see Request object for details).
Each URL must start with either a http:// or https:// protocol prefix!
Note that it is possible to instruct the crawler to load a URL using a HTTP POST request
simply by suffixing it with a [POST] marker, optionally followed by
POST data (e.g. http://www.example.com[POST]<wbr>key1=value1&key2=value2).
By default, POST requests are sent with
the Content-Type: application/x-www-form-urlencoded header.
Maximum label length is 100 characters and maximum URL length is 2000 characters.
Pseudo-URLs
The Pseudo-URLs (crawlPurls) field specifies which pages will be visited by the crawler using
the so-called pseudo-URLs (PURL)
format. PURL is simply a URL with special directives enclosed in [] brackets.
Currently, the only supported directive is [regexp], which defines
a JavaScript-style regular expression to match against the URL.
For example, a PURL http://www.example.com/pages/[(\w|-)*] will match all of the
following URLs:
http://www.example.com/pages/http://www.example.com/pages/my-awesome-pagehttp://www.example.com/pages/something
If either [ or ] is part of the normal query string,
it must be encoded as [\x5B] or [\x5D], respectively. For example,
the following PURL:
will match the URL:
Optionally, each PURL can be associated with a custom label that can be referenced from your JavaScript code to determine which page is currently open (see Request object for details).
Note that you don't need to use this setting at all,
because you can completely control which pages the crawler will access, either using the
Intercept request function
or by calling context.enqueuePage() inside the Page function.
Maximum label length is 100 characters and maximum PURL length is 1000 characters.
Clickable elements
The Clickable elements (clickableElementsSelector) field contains a CSS selector used to find links to other web pages.
On each page, the crawler clicks all DOM elements matching this selector
and then monitors whether the page generates a navigation request.
If a navigation request is detected, the crawler checks whether it matches
Pseudo-URLs,
invokes Intercept request function,
cancels the request and then continues clicking the next matching elements.
By default, new crawlers are created with a safe CSS selector:
In order to reach more pages, you might want to use a wider CSS selector, such as:
Be careful - clicking certain DOM elements can cause unexpected and potentially harmful side effects. For example, by clicking buttons, you might submit forms, flag comments, etc. In principle, the safest option is to narrow the CSS selector to as few elements as possible, which also makes the crawler run much faster.
Leave this field empty if you do not want the crawler to click any elements and only open
Start URLs
or pages enqueued using enqueuePage().
Page function
The Page function (pageFunction) field contains
a user-provided JavaScript function that is executed in the context of every web page loaded by
the crawler.
Page function is typically used to extract some data from the page, but it can also be used
to perform some non-trivial
operation on the page, e.g. handle AJAX-based pagination.
IMPORTANT: This actor uses the PhantomJS headless web browser, which only supports JavaScript ES5.1 standard (read more in a blog post about PhantomJS 2.0).
The basic page function with no effect has the following signature:
The function can return an arbitrary JavaScript object (including array, string, number, etc.) that can be stringified to JSON;
this value will be saved in the crawling results, as the pageFunctionResult
field of the Request object corresponding to the web page
on which the pageFunction was executed.
The crawling results are stored in the default dataset
associated with the actor run, from where they can be downloaded
in a computer-friendly form (JSON, JSONL, XML or RSS format),
as well as in a human-friendly tabular form (HTML or CSV format).
If the pageFunction's return value is an array,
its elements can be displayed as separate rows in such a table,
to make the results more readable.
The function accepts a single argument called context,
which is an object with the following properties and functions:
| Name | Description |
|---|---|
request | An object holding all the available information about the currently loaded web page. See Request object for details. |
jQuery | A jQuery object, only available if the Inject jQuery setting is enabled. |
underscoreJs | The Underscore.js' _ object, only available if the
Inject Underscore.js
setting is enabled.
|
skipLinks() | If called, the crawler will not follow any links from the current page and will continue with the next page from the queue. This is useful to speed up the crawl by avoiding unnecessary paths. |
skipOutput() | If called, no information about the current page will be saved to the results,
including the page function result itself.
This is useful to reduce the size of the results by skipping unimportant pages.
Note that if the page function throws an exception, the skipOutput()
call is ignored and the page is outputted anyway, so that the user has a chance
to determine whether there was an error
(see Request object's errorInfo
field).
|
willFinishLater() | Tells the crawler that the page function will continue performing some background
operation even after it returns. This is useful
when you want to fetch results from an asynchronous operation,
e.g. an XHR request or a click on some DOM element.
If you use the willFinishLater() function, make sure you also invoke finish()
or the crawler will wait infinitely for the result and eventually timeout
after the period specified in
Page function timeout.
Note that the normal return value of the page function is ignored.
|
finish(result) | Tells the crawler that the page function finished its background operation.
The result parameter receives the result of the page function - this is
a replacement
for the normal return value of the page function that was ignored (see willFinishLater() above).
|
saveSnapshot() | Captures a screenshot of the web page and saves its DOM to an HTML file, which are both then displayed in the user's crawling console. This is especially useful for debugging your page function. |
enqueuePage(request) |
Adds a new page request to the crawling queue, regardless of whether it matches
any of the Pseudo-URLs.
The Note that the manually enqueued page is subject to the same processing as any other page found by the crawler. For example, the Intercept request function function will be called for the new request, and the page will be checked to see whether it has already been visited by the crawler and skipped if so. For backwards compatibility, the function also supports the following signature:enqueuePage(url, method, postData, contentType).
|
saveCookies([cookies]) | Saves the current cookies of the current PhantomJS browser to the actor task's Initial cookies setting. All subsequently started PhantomJS processes will use these cookies. For example, this is useful for storing a login. Optionally, you can pass an array of cookies to set to the browser before saving (in PhantomJS format). Note that by passing an empty array you can unset all cookies. |
customData | Custom user data from crawler settings provided via customData input field. |
stats | An object containing a snapshot of statistics from the current crawl.
It contains the following fields:
pagesCrawled, pagesOutputted
and pagesInQueue.
Note that the statistics are collected before
the current page has been crawled.
|
actorRunId | String containing ID of this actor run. It might be used to control the actor using the API, e.g. to stop it or fetch its results. |
actorTaskId | String containing ID of the actor task, or null if actor is run directly.
The ID might be used to control
the task using the API.
|
Note that any changes made to the context parameter will be ignored.
When implementing the page function, it is the user's responsibility to not break normal
page scripts that might affect the operation of the crawler.
Waiting for dynamic content
Some web pages do not load all their content immediately, but only fetch it in the background
using AJAX,
while pageFunction might be executed before the content has actually been
loaded.
You can wait for dynamic content to load using the following code:
Intercept request function
The Intercept request function (interceptRequest) field contains
a user-provided JavaScript function that is called whenever
a new URL is about to be added to the crawling queue,
which happens at the following times:
- At the start of crawling for all Start URLs.
- When the crawler looks for links to new pages by clicking elements matching the Clickable elements CSS selector and detects a page navigation request, i.e. a link (GET) or a form submission (POST) that would normally cause the browser to navigate to a new web page.
- Whenever a loaded page tries to navigate to another page, e.g. by setting
window.locationin JavaScript. - When user code invokes
enqueuePage()inside of Page function.
The intercept request function allows you to affect on a low level
how new pages are enqueued by the crawler.
For example, it can be used to ensure that the request is added to the crawling queue even
if it doesn't match
any of the Pseudo-URLs,
or to change the way the crawler determines whether the page has already been visited or not.
Similarly to the Page function,
this function is executed in the context of the originating web page (or in the context
of about:blank page for Start URLs).
IMPORTANT: This actor is using PhantomJS headless web browser, which only supports the JavaScript ES5.1 standard (read more in blog post about PhantomJS 2.0).
The basic intercept request function with no effect has the following signature:
The context is an object with the following properties:
request | An object holding all the available information about the currently loaded web page. See Request object for details. |
jQuery | A jQuery object, only available if the Inject jQuery setting is enabled. |
underscoreJs | An Underscore.js object, only available if the Inject Underscore.js setting is enabled. |
clickedElement | A reference to the DOM object whose clicking initiated the current navigation
request.
The value is null if the navigation request was initiated by other
means,
e.g. using some background JavaScript action.
|
Beware that in rare situations when the page redirects in its JavaScript before it was
completely loaded
by the crawler, the jQuery and underscoreJs objects will be undefined.
The newRequest parameter contains a Request object
corresponding to the new page.
The way the crawler handles the new page navigation request depends
on the return value of the interceptRequest function in the following way:
- If function returns the
newRequestobject unchanged, the default crawler behaviour will apply. - If function returns the
newRequestobject altered, the crawler behavior will be modified, e.g. it will enqueue a page that would not normally be skipped. The following fields can be altered:willLoad,url,method,postData,contentType,uniqueKey,label,interceptRequestDataandqueuePosition(see Request object for details). - If function returns
null, the request will be dropped and a new page will not be enqueued. - If function throws an exception, the default crawler behaviour will apply
and the error will be logged to Request object's
errorInfofield. Note that this is the only way a user can catch and debug such an exception.
Note that any changes made to the context parameter will be ignored
(unlike the newRequest parameter).
When implementing the function, it is the user's responsibility not to break normal page
scripts that might affect the operation of the crawler. You have been warned.
Also note that the function does not resolve HTTP redirects: it only reports the originally
requested URL, but does not open it to find out which URL it eventually redirects to.
Proxy configuration
The Proxy configuration (proxyConfiguration) option enables you to set
proxies that will be used by the crawler in order to prevent its detection by target websites.
You can use both Apify Proxy
as well as custom HTTP or SOCKS5 proxy servers.
The following table lists the available options of the proxy configuration setting:
| None | Crawler will not use any proxies. All web pages will be loaded directly from IP addresses of Apify servers running on Amazon Web Services. |
|---|---|
| Apify Proxy (automatic) | The crawler will load all web pages using Apify Proxy in the automatic mode. In this mode, the proxy uses all proxy groups that are available to the user, and for each new web page it automatically selects the proxy that hasn't been used in the longest time for the specific hostname, in order to reduce the chance of detection by the website. You can view the list of available proxy groups on the Proxy page in the app. |
| Apify Proxy (selected groups) | The crawler will load all web pages using Apify Proxy with specific groups of target proxy servers. |
| Custom proxies |
The crawler will use a custom list of proxy servers.
The proxies must be specified in the Example:
|
Note that the proxy server used to fetch a specific page
is stored to the proxy field of the Request object.
Note that for security reasons, the usernames and passwords are redacted from the proxy URL.
The proxy configuration can be set programmatically when calling the actor using the API
by setting the proxyConfiguration field.
It accepts a JSON object with the following structure:
Finish webhook
The Finish webhook URL (finishWebhookUrl)
field specifies a custom HTTP endpoint that receives a notification after a run of the actor ends,
regardless of its status, i.e. whether it finished, failed, was aborted, etc.
You can specify a custom string that will be sent with the webhook
using the Finish webhook data (finishWebhookData),
in order to help you identify the actor run.
The provided endpoint is sent a HTTP POST request with Content-Type: application/json; charset=utf-8 header,
and its payload contains a JSON object with the following structure:
You can use the actorId and runId fields to query the actor run status using
the Get run API endpoint.
The datasetId field can be used to download the crawling results
using the Get dataset items
API endpoint - see Crawling results below for more details.
Note that the Finish webhook URL and Finish webhook data are provided merely for backwards compatibility with the legacy Apify Crawler product, and the calls are performed using the Apify platform's standard webhook facility. For details, see Webhooks in documentation.
To test your webhook endpoint, please create a new empty task for this actor, set the Finish webhook URL and run the task.
Cookies
The Initial cookies (cookies) option enables you to specify
a JSON array with cookies that will be used by the crawler on start.
You can export the cookies from your own web browser,
for example using the EditThisCookie plugin.
This setting is typically used to start crawling when logged in to certain websites.
The array might be null or empty, in which case the crawler will start with no cookies.
Note that if the Cookie persistence setting is Over all crawler runs and the actor is started from within a task the cookies array on the task will be overwritten with fresh cookies from the crawler whenever it successfully finishes.
SECURITY NOTE: You should never share cookies or an exported crawler configuration containing cookies with untrusted parties, because they might use it to authenticate themselves to various websites with your credentials.
Example of Initial cookies setting:
The Cookies persistence (cookiesPersistence) option
indicates how the crawler saves and reuses cookies.
When you start the crawler, the first PhantomJS process will
use the cookies defined by the cookies setting.
Subsequent PhantomJS processes will use cookies as follows:
Per single crawling process only"PER_PROCESS" | Cookies are only maintained separately by each PhantomJS crawling process for the lifetime of that process. The cookies are not shared between crawling processes. This means that whenever the crawler rotates its IP address, it will start again with cookies defined by the cookies setting. Use this setting for maximum privacy and to avoid detection of the crawler. This is the default option. |
Per full crawler run"PER_CRAWLER_RUN" | Indicates that cookies collected at the start of the crawl by the first PhantomJS process are reused by other PhantomJS processes, even when switching to a new IP address. This might be necessary to maintain a login performed at the beginning of your crawl, but it might help the server to detect the crawler. Note that cookies are only collected at the beginning of the crawl by the initial PhantomJS process. Cookies set by subsequent PhantomJS processes are only valid for the duration of that process and are not reused by other processes. This is necessary to enable crawl parallelization. |
Over all crawler runs"OVER_CRAWLER_RUNS" |
This setting is similar to Per full crawler run,
the only difference is that if the actor finishes with SUCCEEDED status,
its current cookies are automatically saved
to the cookies setting of the actor task
used to start the actor,
so that new crawler run starts where the previous run left off.
This is useful to keep login cookies fresh and avoid their expiration.
|
Crawling results
The crawling results are stored in the default dataset associated with the actor run, from where you can export them to formats such as JSON, XML, CSV or Excel. For each web page visited, the crawler pushes a single Request object with all the details about the page into the dataset.
To download the results, call the Get dataset items API endpoint:
where [DATASET_ID] is the ID of actor's run dataset,
which you can find the Run object returned when starting the actor.
The response looks as follows:
Note that in the full results of the legacy Crawler product results, each Request
object contained a field called errorInfo, even if it was empty.
In the dataset, this field is skipped if it's empty.
To download the data in simplified format known in the legacy Apify Crawler
product, add the simplified=1 query parameter:
The response will look like this:
To get the results in other formats, set format query parameter to xml, xlsx, csv, html, etc.
For full details, see the Get dataset items
endpoint in API reference.
To skip the records containing the errorInfo field from the results,
add the skipFailedPages=1 query parameter. This will ensure the results have a fixed structure, which is especially useful for tabular formats such as CSV or Excel.
Request object
The Request object contains all the available information about
every single web page the crawler encounters
(both visited and not visited). This object comes into play
in both Page function
and Intercept request function,
and crawling results are actually just an array of these objects.
The object has the following structure: