Indeed Job Search
Pricing
from $1.89 / 1,000 results
Indeed Job Search
Search Indeed globally — full job description, salary range, company rating, remote flag, posted date, and 35 structured fields. 50+ countries. $2.30 per 1,000. No login.
Pricing
from $1.89 / 1,000 results
Rating
5.0
(2)
Developer
CheapGET
Actor stats
9
Bookmarked
265
Total users
30
Monthly active users
an hour ago
Last modified
Categories
Share
Indeed Job Search - Find Jobs on Indeed with Salary & Company Info
Search Indeed job listings worldwide — cheap and fast, with salary info, company details, and no login required.
🏆 Key Features
🌍 Search Jobs in 60+ Countries
-
🔍 Global Indeed Coverage: Search jobs in the United States, United Kingdom, Canada, Australia, Germany, India, and 50+ more countries.
-
📍 City & Region Search: Narrow your search to a specific city or area with adjustable distance radius.
-
⚡ Fast Results: Get hundreds of job listings in minutes — no manual browsing needed.
-
🔄 Fresh Listings: Filter by posting date to see only jobs from the last day, week, or month.
💰 Salary & Compensation Details
-
💵 Salary Ranges: See minimum and maximum salary when disclosed by employers.
-
💱 Currency Conversion: Convert all salaries to your preferred currency using real-time exchange rates.
-
📊 Pay Period Info: Know if the salary is hourly, monthly, or yearly.
-
🎯 Compare Offers: Side-by-side salary comparison across companies and locations.
🏢 Full Company Profiles
-
🏷️ Company Details: Name, industry, website, logo, revenue range, and employee count for every listing.
-
⭐ Ratings & Reviews: Company ratings and review counts to help you pick the right employer.
-
📧 Contact Info: Email addresses and social media links when available on company websites.
-
🔗 Direct Links: Quick links to company profiles and official career pages.
🎯 Flexible Filters
-
🔍 Keyword Search: Search by job title, skill, or company name.
-
📅 Date Filters: Find jobs posted within a specific time window — from 1 day to custom dates.
-
🏠 Remote Jobs: Filter for remote-only positions with the remote toggle.
-
📋 Job Types: Filter by full-time, part-time, contract, internship, or temporary roles.
💰 Pricing
| Resource | Cost | Description |
| --------------- | ------- | ---------------------------------------------------------------------------------------- |
| Actor Start | $0.005 | One-time charge when the search begins |
| Job Details | $0.0021 | Charged for each job found. Includes salary, company info, location, and contact details |
Example Cost Calculation:
-
Searching "Software Engineer" in United States with 100 max results
-
Cost: $0.005 + 100 × $0.0021 = $0.215 total
🎯 Use Cases
👔 Find Your Next Role Faster
Search Indeed by keyword and location to get all matching jobs in one place. Set posted_since to "3 days" to see only the freshest openings before the competition.
💰 Compare Salaries Across Companies
See what companies are paying for your role. Search across regions and compare salary ranges side by side — great for negotiating your next offer.
🏠 Find Remote Jobs Worldwide
Toggle remote-only filtering and search across multiple countries to find the best remote opportunities in your field.
🔔 Set Up Job Alerts
Connect this Actor to Make.com or n8n to get automatic notifications in Slack, Telegram, or Google Sheets whenever new jobs match your criteria.
📊 Track Salary Trends by Region
Compare pay across different cities and countries for the same role. Schedule recurring searches to track how salaries change over time.
🌟 Why Choose This Actor
Built for job seekers, career changers, and anyone tracking the job market, this Actor gives you instant access to Indeed's massive database at a fraction of the cost of manual searching.
| Feature | Indeed Job Search | Other Job Tools | Manual Searching |
| :--------------- | :-------------------- | :----------------- | :--------------- |
| Pricing | ✅ Pay per result | ⚠️ Subscription | ⚠️ Free but slow |
| Data Depth | ✅ 39 fields | ⚠️ 15-20 fields | ⚠️ Manual effort |
| Countries | ✅ 60+ supported | ⚠️ Limited | ⚠️ One at a time |
| Salary Data | ✅ Included | ⚠️ Basic only | ⚠️ Manual lookup |
| Company Info | ✅ Full profiles | ⚠️ Limited | ❌ Not included |
| Setup Time | ✅ Instant | ⚠️ Template needed | ❌ Hours of work |
| Min. Cost | ✅ $0.01 | ⚠️ $50+/month | ⚠️ Free but slow |
🚀 Quick Start
-
Enter your search — Type a job title or skill in the
keywordfield, pick yourcountry, and set how many results you want. -
Click Start — The Actor searches Indeed and collects job listings with salary, company, and contact details.
-
Download your results — Get your jobs as JSON, CSV, or Excel from the Output tab.
💻 Input Parameters
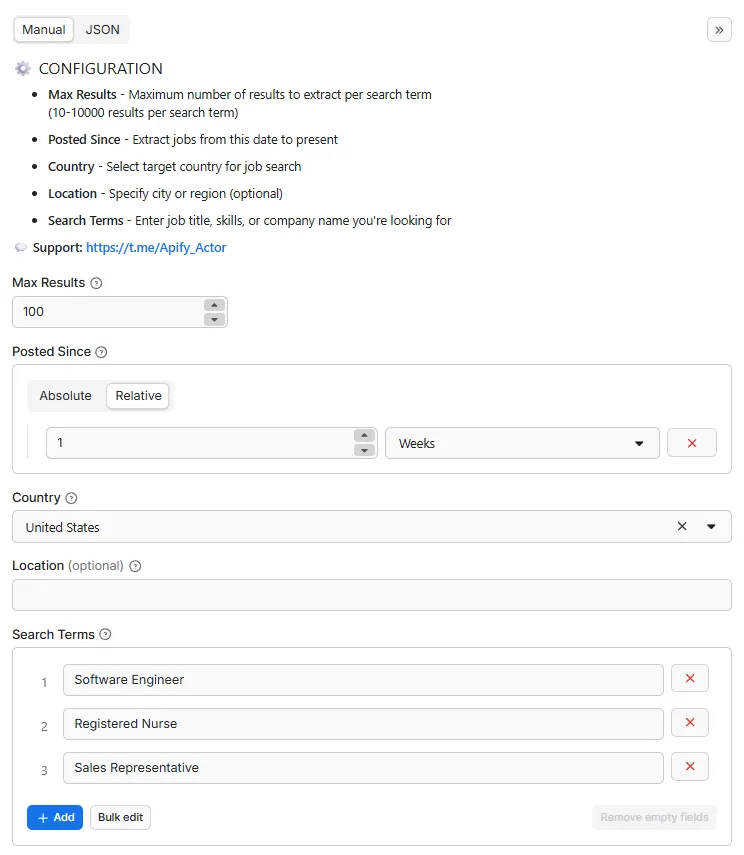
| Parameter | Type | Required | Description |
|---|---|---|---|
keyword | string | ✅ Yes | Job title, skill, or company name to search for |
country | string | ✅ Yes | Country where the chosen job listings are located |
max_results | integer | ✅ Yes | Maximum number of jobs to return |
remote_only | boolean | ❌ No | Restrict results to remote-friendly positions only |
distance | integer | ❌ No | Search radius in miles around the specified location |
location | string | ❌ No | City or region to focus the job search results on |
posted_since | string | ❌ No | Only include listings posted within this timeframe |
job_type | string | ❌ No | Employment type to filter by: full-time, contract, etc. |
currency | string | ❌ No | Chosen currency for converting salary figures |
📝 Example Input
📤 Output Structure
| Field | Type | Description |
|---|---|---|
processor | string | Apify actor URL that processed this job record |
processed_at | string | UTC timestamp when this record was processed |
platform | string | Job board or platform name (e.g. LinkedIn) |
platform_url | string | Job listing URL on the source platform |
official_url | string | Direct URL to the original job posting |
title | string | Job position or role title |
posted_date | string | Date the job was originally posted |
location | string | City, state, or country of the job |
is_remote | boolean | True if the position allows remote work |
description | string | Full job description and requirements text |
job_type | string | Employment type (full-time, part-time, contract) |
job_level | string | Seniority level (junior, mid, senior, manager) |
job_function | string | Job category or department (e.g. Engineering) |
listing_type | string | Type of job listing (standard, featured, etc.) |
skills | string | Required skills and technologies for the role |
work_from_home | string | Remote or hybrid work arrangement details |
vacancy_count | integer | Number of open positions for this role |
experience_range | string | Required years of experience for the role |
salary_period | string | Pay frequency (yearly, monthly, or hourly) |
salary_minimum | number | Minimum salary offered for the position |
salary_maximum | number | Maximum salary offered for the position |
salary_currency | string | ISO currency code for the salary (e.g. USD) |
easy_apply | boolean | True if the job can be applied to directly on the platform |
company_name | string | Name of the company offering the job |
company_type | string | Ownership type of the company (e.g. Public, Private, Nonprofit) |
company_founded | integer | Year the company was founded |
company_industry | string | Industry or sector the company operates in |
company_url | string | Company profile URL on the job platform |
company_website | string | Official website URL of the company |
company_logo | string | URL of the company's logo image |
company_addresses | string | Physical office address of the company |
company_revenue | string | Estimated annual revenue range of the company |
company_description | string | Brief overview or about section of the company |
company_rating | number | Overall company rating score (e.g. out of 5) |
employee_count | string | Approximate number of employees at the company |
review_count | integer | Total number of employee reviews for the company |
emails | array | Contact email addresses for the job or company |
phones | array | Contact phone numbers for the job or company |
social_links | object | Company social media URLs keyed by platform name |
📤 Example Output
🔌 Integrations
Connect this actor to your favorite tools and automate your job search.
🐍 Python
🟨 JavaScript / Node.js
🌐 REST API (curl)
Ⓜ️ Make.com Integration
Get Started with Make.com (1000 Free Credits) 🎁
🎱 N8N.io Integration
Open Source Workflow Automation ⚡
📚 API Documentation
-
API Docs — Full API reference and integration guide
-
Python Docs — Python client documentation with examples
-
JavaScript Docs — Node.js and browser integration guide
🏗️ Metadata (JSON-LD)
🚀 Performance Tips
Get the best results from your Indeed job searches with these tips:
💰 Save Money
-
Start Small: Test with
max_results: 10first to preview output before running larger searches. -
Be Specific: Use precise job titles like "Senior React Developer" instead of broad terms like "developer."
-
Track Costs: Check the "Usage" tab in Apify Console for real-time spending.
⚡ Get Faster Results
-
Fewer Results: Smaller
max_resultsvalues finish faster. -
Add Location: Specifying a city narrows the search and speeds things up.
-
Recent Only: Use
posted_since: "7 days"to search fewer listings and finish quicker.
🛡️ Better Data Quality
-
Country Names: Use full country names exactly (e.g., "United States", not "USA" or "US").
-
Salary Data: Not all employers disclose pay. Filter results by
salary_minimumto find jobs with salary info. -
Stay Fresh: Job postings change daily. Schedule regular searches for time-sensitive applications.
❓ FAQ
How do I search for jobs on Indeed?
Enter a job title or skill in the keyword field, pick your country, and click Start. The Actor searches Indeed and returns matching job listings with full details.
Is Indeed Job Search free to use?
You pay only for results — $0.005 to start a search plus $0.0021 per job found. There are no subscriptions or monthly fees. A 100-job search costs about $0.22.
What countries does this support?
Over 60 countries including United States, United Kingdom, Canada, Australia, Germany, India, France, Netherlands, Singapore, Switzerland, and many more.
Can I find remote jobs only?
Yes! Set remote_only to true and the Actor will show only remote-friendly positions.
Does it include salary information?
Yes — salary minimum, maximum, currency, and pay period are included when employers disclose them. You can also convert all salaries to your preferred currency.
How many jobs can I get?
Set max_results up to 500 per search. Start with 10–50 for testing, then increase as needed.
What output formats are available?
Results come in JSON by default. You can also download them as CSV or Excel from the Output tab in Apify Console.
How long does a search take?
Depends on the number of results. Typical times: 10 jobs ≈ 1–2 minutes, 50 jobs ≈ 3–5 minutes, 200 jobs ≈ 8–12 minutes.
Why don't job titles match my keyword exactly?
Indeed uses its own search algorithm that considers relevance, synonyms, and related skills — the same behavior you see when searching Indeed directly.
🏷️ SEO Keywords
🔍 Primary Keywords
indeed job search, find jobs on indeed, indeed job listings, indeed salary search, indeed job finder
📝 Long-Tail Keywords
search indeed jobs with salary info, find remote jobs on indeed, indeed job search by country, how to find jobs on indeed fast, indeed job listings with company details
🏢 Industry Keywords
nursing jobs indeed, software engineer jobs indeed, indeed warehouse jobs, indeed healthcare jobs, indeed finance jobs
📍 Location Keywords
indeed jobs usa, indeed jobs uk, indeed jobs canada, indeed jobs australia, indeed jobs germany, indeed remote jobs worldwide
💼 Use Case Keywords
best indeed job search tool, cheap indeed job finder, indeed job alerts, indeed salary comparison tool, indeed company reviews search
⚖️ Legal & Compliance
This actor collects publicly available data only. It does not bypass authentication, access private content, or violate platform terms of service. You are responsible for:
-
Data Rights: Ensuring you have permission to collect and use the data
-
Privacy Compliance: Adhering to GDPR, CCPA, and other applicable privacy laws when processing data
-
Platform Terms: Respecting Indeed's terms of service and usage policies
-
Ethical Use: Using collected data responsibly and in compliance with applicable laws
Need help or have compliance questions? Contact us.
🔗 Related Actors
💼 Jobs
-
Best Job Search — Search jobs across LinkedIn, Indeed, Glassdoor, and regional platforms all at once.
-
Glassdoor Job Search — Find Glassdoor jobs with salary ranges, company ratings, and reviews.
-
Indeed Job Search — Search Indeed for jobs with salary info, company details, and application links.
-
LinkedIn Job Search — Find LinkedIn jobs with applicant counts, company info, and seniority details.
🎬 Videos
-
Best Video Downloader — Download videos from 1000+ platforms with quality options and thumbnails.
-
TikTok Video Downloader — Download TikTok videos without watermarks with full video details.
-
YouTube Video Downloader — Download YouTube videos in multiple qualities with comments and metadata.
-
Video Subtitles Downloader — Get subtitles from any video as downloadable text files.
-
TikTok Live Recorder — Record TikTok live streams with creator and engagement info.
-
TikTok Video Lookup - Get full TikTok video details with hidden SEO data and music info
-
YouTube Niche Scraper - Find YouTube videos by keyword and get channel details, contact info, and stats
-
Video To Text — Turn any video or audio into searchable text with timestamps.
-
Instagram To Text — Turn Instagram videos into text for captions, research, and archives.
📱 Social Media
-
Instagram Explore - Get trending Instagram Explore posts with topic labels, media links, and engagement counts.
-
Instagram Post - Get recent Instagram posts from any public profile with captions and media.
-
Instagram Profile - Check any Instagram profile for bio, followers, business info, and more.
-
Social Media Marketing — Generate ready-to-post marketing content with multiple tones and formats.
-
Find Any Company On LinkedIn — Look up any company on LinkedIn with full profile details.
-
Find Anyone On LinkedIn — Look up anyone on LinkedIn with profile details and work history.
-
Reddit User Profile — Check any Reddit user's profile, karma, and activity.
-
Reddit Community Profile — Get subreddit info with rules, descriptions, and pinned posts.
-
Reddit Community Post — Get posts from any subreddit with comments and engagement stats.
-
Reddit Post Search — Search Reddit by keyword and get posts with comments and votes.
-
Reddit Community User — Find active users in any subreddit with karma and profile details.
-
X Community Profile — Get X community details with membership info and activity.
-
X User Profile — Get any X user's profile with followers, bio, and pinned posts.
💬 Telegram
-
Telegram Group Member — Get member profiles from any public Telegram group.
-
Telegram Channel Message — Get messages from Telegram channels with media, views, and reactions.
-
Telegram Profile — Look up Telegram profiles for users, groups, bots, and channels.
🏠 Local & Real Estate
-
Google Business Profile — Find local businesses on Google with reviews, ratings, photos, and contacts.
-
Zillow Real Estate — Search Zillow listings with pricing, photos, valuations, and address details.
-
US Real Estate — Search US property listings with pricing, specs, and agent details.
🤝 Support & Community
📧 Support: Contact Us 💬 Community: Telegram Group
Last Updated: April 22, 2026