Indeed job scraper
Pricing
$20.00/month + usage
Indeed job scraper
This is an actively maintained scraper which can extract job postings and hiring company details at scale from any indeed search results page for a fixed monthly rental price. Well documented with examples and demos
Pricing
$20.00/month + usage
Rating
4.8
(48)
Developer
Curious Coder
Maintained by CommunityActor stats
162
Bookmarked
3.8K
Total users
109
Monthly active users
18 days
Issues response
3 months ago
Last modified
Categories
Share
This Indeed jobs actor collects public job listings from Indeed by country site, keywords, and location (see input below).
Indeed job scraper data fields
You can get all the fields listed in below table (and more) from this scraper
| 💬 Job Description | 🌐 Company Website | 🤵 CEO Name |
|---|---|---|
| 💼 Display Title | 💵 Extracted Salary | 🌐 Website |
| 📈 Company Rating | 📊 Company Review Count | 📅 Relative Time |
| 📍 Location | 📅 Pub Date | 🛑 Expired |
| 📌 Job Types | 📌 Location Count | 📜 Taxonomy Attributes |
| 📉 Ranking Scores | 📈 Indeed Apply | 🌐 Third Party Apply |
Features
- Scraper is capable of handling dynamic changes on the Indeed website.
- Optimized for efficiency and accuracy.
- We monitor and troubleshoot any issues or changes in the scraping process.
- We stay updated on web scraping best practices and industry trends.
How to scrape jobs from Indeed
- Open the actor on Apify and click Try for free (or run your saved task).
- Set Country to the Indeed site you want (for example United States →
www.indeed.com, United Kingdom →uk.indeed.com). - Optionally enter Job keywords and/or Location. Use the same style of keywords and place names you would type on Indeed.
- Optionally set Search radius (km) around the location, Posted within (days) (
1,3,7, or14only, per Indeed), and Total number of records required (leave empty to collect all results the search can return). - Click Start. When the run finishes, use Export to download JSON, CSV, Excel, or other formats.
Scraper options
Main input fields:
| Input | Description |
|---|---|
| Country | Indeed regional site (subdomain) for the search. |
| Job keywords | Search terms / title text. |
| Location | City, region, or postal area string. |
| Search radius (km) | Radius around the location in kilometers (Indeed GraphQL radius + KILOMETERS). |
| Posted within (days) | Optional; only 1, 3, 7, or 14 are applied. |
| Total number of records required | Maximum unique jobs written to the dataset; omit for no cap (subject to platform limits). |
Integrations
You can use Make to integrate indeed jobs to any other SaaS platform by designing your own automation flows.
For additional job scraping options, the LinkedIn Jobs Scraper extracts detailed job data from LinkedIn search without requiring login. To enrich your job data with company contact information, the Contact Info Finder provides comprehensive contact details including verified email addresses.
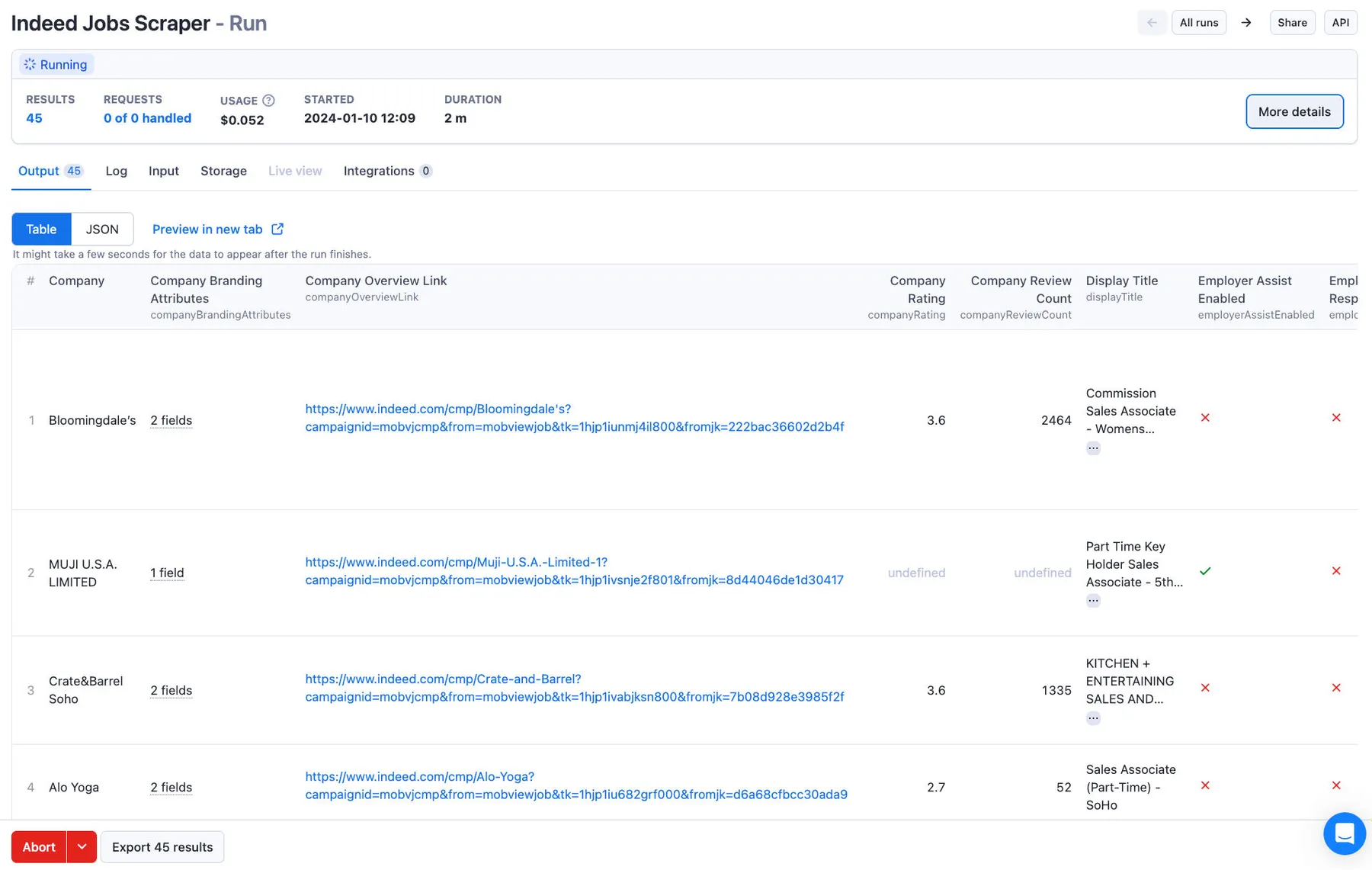
Sample output
You can download the dataset extracted by indeed scraper in various formats such as JSON, HTML, CSV, or Excel.
Job data documentation
Each dataset record represents one job posting. Fields are omitted when Indeed does not provide a value (except where noted).
id: Indeed job key (same ID used inviewJobLink).title: Job title.salary: Salary information when available, as an object:{ min, max, type, currencyCode }.jobDescription: Plain-text job description (with any HTML stripped).jobDescriptionHTML: Raw job description HTML, when available.originalApplyUrl: Direct URL provided by the employer or listing for applying or viewing the job.viewJobLink: Relative path to the job on the specified country site (prefix with the site’s origin for a full URL).companyOverviewLink: Full URL to the company page/profile on Indeed, when available.pubDate: Posting date/time as Unix time in milliseconds (when available).expirationDate: Date/time when the job is set to expire, ornullif not provided.expired: Whether this listing is marked as expired.isRepost: Indicates if this job is a repost.newJob: Whether the listing is flagged as a latest post.urgentlyHiring: Whether the employer is marked as urgently hiring.highVolumeHiring: indicates high-volume hiring.formattedLocation: Single-line location string suitable for display.jobLocationCity: City where the job is located, if specified.jobLocationState: State or region code (admin1Codeor similar), if available.location: Structured location object including:countryCode,admin1Code,admin1Name,admin2Code,admin2Name,admin3Code,admin3Name,admin4Code,admin4Name,city,statecountryName,postalCode,latitude,longitude,streetAddress,fullAddressformatted:{ long, short }
jobTypes: Array of human-readable job type labels (e.g., "Full-time", "Part-time"), if any.companyDetails: Employer/company profile object when available, which may include:name,rating,reviewCount,ceoName,ceoPhotoUrl,industry,sectorNamesemployeeRange,revenue,headquartersLocation({ address }),websiteUrl,logoUrl,headerImageUrl
companyOverviewLink: Full Indeed URL to the company’s profile (redundant with the above but present for clarity).benefits: Array of benefit/compensation objects, each with{ key, label }.attributes: Array of job attribute objects from the job taxonomy, each with{ key, label }.language: Language code or name when provided.occupations: Array or object describing job occupation codes or taxonomy.socialInsurance: Social insurance info when provided.jobSourceName: Name of the employer or agency that posted this job, if specified.trackingKey: Internal search correlation ID from the Indeed payload.
Only the fields listed above (and possibly more, as returned by Indeed) will appear in the dataset when provided or applicable.
How much will it cost me to scrape Indeed jobs ?
To use this scraper you need to pay $20 per month fixed cost to the developer and you should have an Apify subscription which starts from $49/mo prepaid usage credits. Based on historical data our scraper costs an average of $0.73 per thousand jobs scraped as usage credits. Based on above data, you can scrape upto 67,000 jobs per month with starter plan
Why scrape indeed jobs data?
Here are some use cases for an Indeed jobs scraper:
Job Market Research: Use an Indeed scraper to collect job postings in a specific industry or location. This data can be analyzed to identify trends, such as job demand, salary ranges, and skill requirements, which can inform business strategies or career decisions.
Competitor Analysis: Monitor your competitors' job postings on Indeed to gain insights into their hiring strategies and the types of positions they are actively recruiting for. This can help you stay competitive in the job market.
Company Research: Scraper can be used to gather data on companies posting job listings on Indeed, including information about their industry, location, and hiring patterns. This data can be valuable for business development and partnership opportunities.
Salary Benchmarking: Collect salary information from job postings to understand the average compensation for specific roles in different regions. This data can be used to benchmark your own salary structure or negotiate better compensation.
Location-Based Insights: Analyze job postings in different geographical locations to identify areas with high demand for specific skills or industries. This information can guide decisions about where to expand or relocate a business.
Lead Generation: Scraping job postings for contact information (where available) can be used for lead generation. This is particularly useful for B2B companies looking to connect with potential clients or partners in specific industries or roles.
CRM Enrichment: If you have a CRM (Customer Relationship Management) system, you can use the scraper to enrich your existing contacts with information about their current job positions, companies, and industries. This helps you maintain up-to-date and relevant customer profiles.
Marketplace Insights: Analyze job postings to understand the demand for certain skills or certifications in the job market. This information can be valuable for educational institutions and training providers to tailor their programs to meet industry needs.
Content Creation: Bloggers, journalists, or researchers can use scraped job data to create reports, articles, or blog posts about employment trends, job market changes, or emerging industries.
Consulting Services: Offer consulting services to businesses based on the insights gained from scraping Indeed data. Help companies optimize their hiring processes, identify market gaps, or make informed decisions about expansion and talent acquisition.
Is it legal to scrape indeed.com ?
Our scrapers are ethical and do not extract any private user data, such as email addresses, gender, or location. They only extract what the user has chosen to share publicly. We therefore believe that our scrapers, when used for ethical purposes by Apify users, are safe. However, you should be aware that your results could contain personal data. Personal data is protected by the GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping
Your feedback
We’re always working on improving the performance of our Actors. So if you’ve got any technical feedback for this scraper or simply found a bug, please create an issue on the actor’s Issues tab in Apify Console.