Reddit Search Scraper - 3,000+ Results in 10 Seconds
Pricing
from $0.99 / 1,000 results
Reddit Search Scraper - 3,000+ Results in 10 Seconds
Search Reddit posts and comments by keyword. 3,000+ results in seconds with smart subreddit auto-discovery. Titles, bodies, scores, authors, timestamps, permalinks. 5 sort orders, time filters. Scope to specific subreddits or let it find them for you.
Pricing
from $0.99 / 1,000 results
Rating
1.0
(1)
Developer
ClearPath
Maintained by CommunityActor stats
0
Bookmarked
157
Total users
72
Monthly active users
5 days ago
Last modified
Categories
Share
Reddit Search Scraper | Fast Bulk Keyword Search (2026)
3,000+ results in under 10 seconds — type a keyword, get results from 20+ auto-discovered subreddits. The fastest Reddit search scraper on Apify.
Just enter a keyword. The actor automatically finds the top 20 most relevant subreddits and searches across all of them in parallel. No need to know which subreddits to target. Posts, comments, or both. Five sort orders, time filters.
| Clearpath Reddit Suite • Search, analyze, and monitor Reddit at scale | |||
|
➤ You are here Search Scraper Keyword search across Reddit |
Full comment tree scraper |
Feed scraper with 108 fields |
Bulk profile & karma lookup |
Copy to your AI assistant
Copy this block into ChatGPT, Claude, Cursor, or any LLM to start building with this data.
Key Features
- Smart subreddit auto-discovery — just type a keyword and the actor automatically finds the top 20 most relevant subreddits and searches across all of them. Get thousands of targeted results without knowing which subreddits to target
- Advanced query syntax: boolean operators, exact phrases, grouping, exclusion, and field operators (
author:,title:,selftext:,self:,flair:,url:). Turn a blunt keyword into a precise brand monitor or lead-gen filter. See Query recipes - Rich 52-field output: every post carries media and video URLs, galleries, polls, full subreddit context (subscriber count, type, icons), and author metadata. Comments add parent-comment linkage and parent-post context
- Posts, comments, or both — a single
contentTypetoggle controls whether you get posts, comments, or both result types in one run. No need to run the actor twice - 5 sort orders — relevance, new, top, hot, and most comments. Choose how results are ranked to match your use case
- Time filtering — restrict results to the past hour, day, week, month, or year. Combine with any sort order to narrow the window
- Subreddit scoping — search all of Reddit at once, target a single subreddit, or search across multiple subreddits in one run
- Bulk subreddit input — paste subreddit names in any format:
python,r/python,https://reddit.com/r/python. Mix formats freely in the same input - Fast — results stream in within seconds. Multiple subreddits run concurrently, so adding more subs doesn't proportionally increase run time
How to Search Reddit
Auto-discover subreddits (easiest)
Just enter a keyword. The actor finds the top 20 relevant subreddits automatically and searches across them.
Returns ~1,000+ results from across r/notion, r/obsidianmd, r/productivity, r/notetaking, and 16 other relevant communities.
Basic keyword search
Enter a search query. The actor searches all of Reddit and returns up to 100 posts sorted by relevance.
Search for comments instead of posts
Set contentType to comments to search comment text instead of post titles and bodies.
Get both posts and comments
Set contentType to both to retrieve matching posts and comments in a single run. Results are labeled with _type so you can filter them downstream.
Search within a specific subreddit
Use subreddit to scope results to a single community. Any format works.
Search across multiple subreddits
Use the subreddits array to search several communities in parallel. Mix name formats freely.
Newest results with time filter
Combine sort: "new" with a time filter to find the most recent discussions within a specific window.
Input Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
query | string | required | Keywords to search for. Supports boolean operators and quoted phrases (max 700 characters) |
maxResults | integer | 100 | Maximum number of results to return. Set to 0 for unlimited |
contentType | enum | posts | What to search: posts, comments, or both |
sort | enum | relevance | Sort order: relevance, new, top, hot, comments |
timeFilter | enum | all time | Time range: hour, day, week, month, year. Leave empty for all time |
subreddit | string | — | Scope search to a single subreddit. Leave empty to search all of Reddit |
subreddits | string[] | [] | Search across multiple subreddits. Results are merged and deduplicated |
autoDiscoverSubreddits | boolean | true | Auto-find relevant subreddits when none specified |
maxSubreddits | integer | 20 | Max subreddits to auto-discover (1-50) |
Sort order reference
| Value | Behavior |
|---|---|
relevance | Reddit's default. Balances keyword match quality with engagement signals |
new | Most recent results first, regardless of score |
top | Highest score (upvotes minus downvotes) |
hot | Currently trending content. Balances recency and engagement. Posts only |
comments | Most commented results first. Posts only |
Time filter reference
| Value | Window |
|---|---|
hour | Past 60 minutes |
day | Past 24 hours |
week | Past 7 days |
month | Past 30 days |
year | Past 365 days |
| (empty) | All time (default) |
Subreddit input formats
All of these are equivalent and can be mixed in the same subreddits array:
pythonr/python/r/pythonhttps://reddit.com/r/pythonhttps://www.reddit.com/r/pythonhttps://old.reddit.com/r/python
Search query syntax
The query field supports Reddit's full search syntax: boolean operators, exact phrases, grouping, and field operators that target a specific part of a post. This is what lets you go from a blunt keyword to a precise, repeatable monitor. Maximum query length is 700 characters.
Boolean and phrase operators
| Syntax | Example | Behavior |
|---|---|---|
| Keywords | kubernetes terraform | All terms must appear, ranked by relevance |
| Exact phrase | "web scraping" | Matches the exact phrase only |
| OR | flask OR django | Matches either term |
| AND | python AND scraping | Both terms must appear |
| NOT | jaguar NOT car | Excludes results with the second term |
| Exclude | python -snake | Same as NOT, using a leading - |
| Grouped | ("flask" OR "django") AND "REST API" | Combine operators with parentheses |
Field operators scope a term to one part of the post:
| Operator | Example | Matches |
|---|---|---|
author: | author:spez | Posts by a specific user |
title: | title:"show reddit" | Term appears in the title |
selftext: | selftext:"changed my life" | Term appears in the post body |
self: | self:yes climate change | Text posts only (self:no for link posts only) |
flair: | flair:"Discussion" | Posts with a specific flair (most precise inside one subreddit) |
url: | url:youtube.com | Link posts pointing to a domain |
Operators stack with grouping and phrases, and they work whether you search all of Reddit or scope to specific subreddits.
Query recipes
Each recipe is a complete, ready-to-run input. Paste it straight into an API call or the Console, then swap in your own terms.
Brand and competitor monitoring. Track your product and every alternative in one run, newest first, to build a live mention feed:
Buying-intent lead generation. Surface people actively asking for a recommendation, and drop the noise with an exclusion:
Title-only topic tracking. Catch posts that are actually about the subject, not ones that mention it in passing:
Account monitoring. Pull everything a specific user posts, newest first:
Deep body-text search. Match a phrase inside the post body, where keyword search alone would miss it:
Discussion mining in one community. Combine a flair filter with the subreddits field to read just the long-form threads from a single subreddit:
What Data Can You Extract?
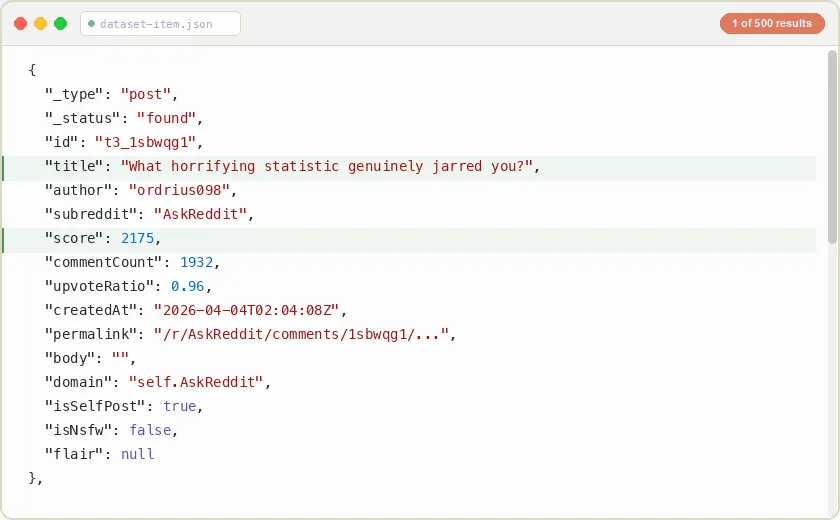
The output contains two row types depending on your contentType setting: post rows and comment rows. Each row includes a _type field so you can distinguish them when using both mode.
Every row is rich by default. Posts carry 52 fields and comments carry 30 fields, including media URLs, full subreddit context (subscriber count, type, icons), author metadata, and parent-post context on comments. Nothing the source exposes is dropped except viewer-specific noise.
Post row (52 fields)
The media, gallery, and poll objects are null on text posts and populate by post type. Their shapes (arrays truncated):
Post fields (52): _type, _status, id, title, author, subreddit, score, commentCount, upvoteRatio, createdAt, editedAt, permalink, url, body, domain, outboundUrl, postHint, languageCode, isSelfPost, isNsfw, isSpoiler, isLocked, isStickied, isArchived, isContestMode, isCrosspostable, isGildable, isScoreHidden, isPollIncluded, isCommercialCommunication, isCrowdControlFilterEnabled, crowdControlLevel, distinguishedAs, removedByCategory, suggestedCommentSort, isTranslated, translatedLanguage, isThumbnailEnabled, flair, thumbnail, authorId, authorType, authorFlair, authorIsNsfw, authorIsCakeDayNow, authorIconUrl, media, gallery, poll, postEventInfo, crosspostRoot, subredditInfo
Comment row (30 fields)
parentId is the parent comment's ID (or null for a top-level comment), so you can reconstruct full reply threads from a flat result set.
Comment fields (30): _type, _status, id, parentId, author, subreddit, score, createdAt, editedAt, permalink, body, isScoreHidden, isOP, authorId, authorKarma, authorType, authorIsAcceptingFollowers, authorIconUrl, postId, postTitle, postUrl, postAuthor, postScore, postCommentCount, postFlair, postDomain, postIsSelfPost, postCreatedAt, postLanguageCode, subredditSubscribers
Pricing - Pay Per Event (PPE)
| $0.99 per 1,000 results |
You pay only for what you scrape. Each result (post or comment) counts as one result-scraped event.
Budget controls: Set a spending limit on any run from the Apify Console. The actor stops automatically when the budget is reached, and you keep all data scraped up to that point.
Use Cases
Brand monitoring. Search for your company or product name across all of Reddit. Use sort: "new" to catch mentions as they appear. Schedule daily or hourly runs to build a continuous feed of brand mentions with scores, timestamps, and subreddit context.
Market research. Search keywords related to your industry to understand what real users discuss, recommend, and complain about. The score and commentCount fields reveal which topics generate the most engagement. Scope to relevant subreddits for focused insights.
Content research. Find top-performing discussions on any topic. Use sort: "top" with timeFilter: "month" to surface the highest-scoring content from the past 30 days. The body field gives you the full text, and upvoteRatio tells you how universally the community agrees.
Competitor analysis. Search competitor names and products to see what customers say on Reddit. Compare engagement metrics across different brands. The subreddit field reveals which communities discuss each competitor most.
Sentiment analysis. Pull thousands of comments mentioning a topic and feed them into your NLP pipeline. Each row includes the full text, score, and metadata needed for downstream analysis. Use time filters to segment sentiment by period.
Lead generation. Monitor subreddits where your target audience asks for recommendations. Search for phrases like "looking for", "best tool for", or "alternative to" to find high-intent posts. Export to your CRM or outreach tool via Apify integrations.
Academic research. Build datasets of public Reddit discussions on any topic. The structured output with timestamps, scores, and subreddit metadata supports quantitative analysis of online discourse, community dynamics, and information spread.
SEO and content strategy. Analyze which questions and topics generate engagement in your niche. Use comment search to find the specific advice and recommendations that get upvoted. Map these insights back to your content calendar.
FAQ
How many results can I get per run?
No hard limit. Set maxResults to 0 for unlimited. With auto-discovery across 20+ subreddits, a single keyword can return thousands of results. The actual count depends on how many matching posts/comments exist in the discovered subreddits.
What's the difference between searching posts and comments?
Post search matches against post titles and body text. Comment search matches against comment text. Use contentType: "both" to search both simultaneously. Each type is returned as separate rows with a _type field.
How does multi-subreddit search work?
When you provide multiple subreddits, the actor searches each one in parallel. Results are merged into a single dataset. Each row includes a subreddit field so you can filter or group by community.
What subreddit formats are accepted?
Plain name (python), prefixed (r/python), full URL (https://reddit.com/r/python), old/new/mobile URLs, and any combination in the same input. The actor normalizes everything before searching.
Can I search all of Reddit at once?
Yes. Leave both subreddit and subreddits empty, and the actor searches across all public subreddits.
How do time filters work? Time filters restrict results to a specific window: past hour, day, week, month, or year. Leave empty to search all time. Time filters work with all sort orders.
What happens if I search a subreddit that doesn't exist? The actor skips it and continues with the remaining subreddits. You are not charged for failed searches.
What does the _status field mean?
"found" means the result was successfully scraped. This field is consistent across all actors in the Clearpath Reddit Suite, so you can build pipelines that handle status uniformly.
How does "both" mode split the results?
When contentType is "both", the actor runs post search and comment search in parallel. Each type gets up to maxResults results independently. The total output can be up to twice maxResults.
Can I use boolean operators in the search query?
Yes. The query supports AND, OR, NOT, quoted phrases for exact matching, a leading - to exclude a term, and parentheses for grouping. For example: ("flask" OR "django") AND "REST API". Maximum query length is 700 characters.
Can I monitor my brand and its competitors in one search?
Yes, and it's the most popular use of this actor. Group every name with OR inside parentheses and anchor it with a phrase: ("1Password" OR "Bitwarden" OR "Dashlane") "switched". Set sort: "new" and schedule the run to get a continuous feed of every mention across Reddit.
Can I search only post titles, or only post bodies?
Yes. Use title: to require a term in the title (title:"show reddit") and selftext: to require it in the body (selftext:"changed my life"). This cuts out posts that only mention your term in passing.
Can I find every post from a specific user?
Yes. Use author:username (for example author:AutoModerator). Combine it with keywords or the subreddits field to narrow further.
Can I limit results to text posts or link posts?
Yes. Add self:yes for text (self) posts only, or self:no for link posts only. You can also target link posts by domain with url: (for example url:youtube.com).
Can I filter by post flair?
Yes. Use flair:"Discussion" to match a specific flair. Flair filtering is most precise when you also scope the run to one subreddit with the subreddits field, since flairs are defined per community.
What sort orders work for comments?
relevance, new, and top work for both posts and comments. hot and comments (most comments) apply only to post search.
Can I schedule recurring searches?
Yes. Set up a schedule in the Apify Console to run the actor at any interval. Combine with sort: "new" and a time filter to build a continuous monitoring pipeline without duplicate results.
What output formats are available? The Apify Console lets you download results as JSON, CSV, Excel, XML, or RSS. You can also access the dataset via the Apify API in any of these formats.
How does this compare to the Subreddit Posts Scraper? This actor searches by keyword across Reddit. The Subreddit Posts Scraper scrapes a subreddit's feed (hot, new, top, rising, controversial) without a keyword filter. Use this actor when you need to find specific content. Use the Subreddit Posts Scraper when you want everything from a subreddit's feed.
How does this compare to the Post & Comments Scraper? This actor finds posts and comments by keyword. The Post & Comments Scraper starts from specific post URLs and extracts full comment trees with nested replies. Use this actor for discovery, and the other for deep extraction of known threads.
More Clearpath scrapers for Reddit
🔍 Search & discovery
 Reddit Subreddit Posts Scraper
Reddit Subreddit Posts Scraper
Full subreddit feeds: hot, new, top, rising
💬 Threads & comments
 Reddit Post Comments Scraper
Reddit Post Comments Scraper
Full comment trees and nested replies from any post URL
👤 Users
 Reddit Profile Scraper
Reddit Profile Scraper
Bulk username, karma, and account lookup Reddit User Posts & Comments Scraper
Reddit User Posts & Comments Scraper
A single user's full post and comment history
🤖 AI & LLM tools
 Reddit MCP Server
Reddit MCP Server
Live Reddit search inside your AI assistant Reddit Answers API
Reddit Answers API
Reddit's AI answer engine for any question Reddit to LLM
Reddit to LLM
Clean Reddit threads as Markdown for AI pipelines
Support
- Bugs: Issues tab
- Features: Email or issues
- Email: max@mapa.slmail.me
Legal Compliance
Extracts publicly available data. Users must comply with Reddit terms and data protection regulations (GDPR, CCPA).
