Company News & Announcement Finder
Pricing
from $1.80 / 1,000 announcement-results
Company News & Announcement Finder
Find recent public company news, press releases, newsroom posts, blog announcements, product launches, funding updates, partnerships, and expansion signals. One flat, CSV-ready row per announcement. No login or cookies.
Pricing
from $1.80 / 1,000 announcement-results
Rating
0.0
(0)
Developer
Delowar Munna
Maintained by CommunityActor stats
0
Bookmarked
4
Total users
2
Monthly active users
a month ago
Last modified
Categories
Share

Find recent public company news, press releases, newsroom posts, blog announcements, product launches, funding updates, partnerships, and expansion signals for a list of companies or source URLs. You get one flat, CSV-ready row per announcement: title, URL, source, date, snippet, a detected category, signal tags, and a transparent growth-signal score (0–100).
Built for B2B sales, lead generation, competitor monitoring, and market research — turn a company list into a clean stream of business signals without expensive news APIs or AI media-intelligence platforms.
- ✅ No login, no cookies, no API keys. Public data only.
- ✅ One row per announcement with source tracking and simple signal scoring.
- ✅ Transparent, non-AI scoring you can audit field-by-field.
- ✅ Prefers public RSS/Atom feeds and company-owned news/press/blog pages, with a free public-search fallback.
What it does
For every company input the actor:
- Resolves the company website (free public search for bare names).
- Discovers public announcement sources — common paths like
/news,/press,/press-releases,/blog,/newsroom, plus anyRSS/Atomfeeds, with a public-search fallback. - Extracts announcements from RSS/Atom feeds, schema.org
Article/NewsArticleJSON-LD, Open Graph metadata, and visible article links. - Normalizes URLs, dates, snippets, and source types; classifies a category and signal tags.
- Scores a transparent
growth_signal_scoreand emits one flat row per announcement.
For start URLs, the actor scans the provided newsroom/press/blog/RSS pages directly.
It does not do login/session scraping, paywalled content, full-article or media downloads, deep crawling, AI summaries, or ongoing monitoring.
Input
| Field | Type | Default | Description |
|---|---|---|---|
companies | array of strings | [] | Company names or domains. Provide at least one company or start URL. Max 500. |
startUrls | array of strings | [] | Direct newsroom/press/blog/RSS URLs to scan. |
searchMode | string | company_sources | company_sources (discover sources) or direct_urls_only (scan only start URLs). |
sourceTypes | array of strings | all | newsroom, press_release, blog, rss, general_news. |
maxResults | integer | 100 | Global cap on saved announcement rows (1–5000). |
maxResultsPerCompany | integer | 20 | Cap on announcements per company (1–200). |
lookbackDays | integer | 180 | Keep dated announcements within this window (1–3650). Undated rows are kept. |
fromDate / toDate | string | "" | Optional fixed YYYY-MM-DD bounds; override lookbackDays. When set, undated rows are dropped. |
includeKeywords | array of strings | [] | Keep only announcements matching at least one keyword. |
excludeKeywords | array of strings | [] | Drop announcements matching any keyword. |
signalCategories | array of strings | [] | Keep only matching detected categories. |
deduplicate | boolean | true | Remove duplicate announcements before saving/charging. |
proxyConfiguration | object | { "useApifyProxy": true } | Datacenter, no proxy, or custom proxy URLs. Apify Residential rejected at startup. |
Example inputs
1. Enrich a company list with recent announcements and filter by signal
2. Scan only specific newsroom / RSS URLs
3. Minimal run — just give it companies
Output
One flat row per announcement. Key fields:
- Company:
input_company,company_name,company_domain - Source:
source_type,source_name,source_domain,is_company_owned_source,discovery_method,source_page_url,http_status - Announcement:
announcement_title,announcement_url,canonical_url,published_date,published_datetime,snippet - Signals:
detected_category,signal_tags,growth_signal_score(0–100),signal_strength(high/medium/low),matched_keywords - Timestamp:
scraped_at
Company announcements — all fields (table view)
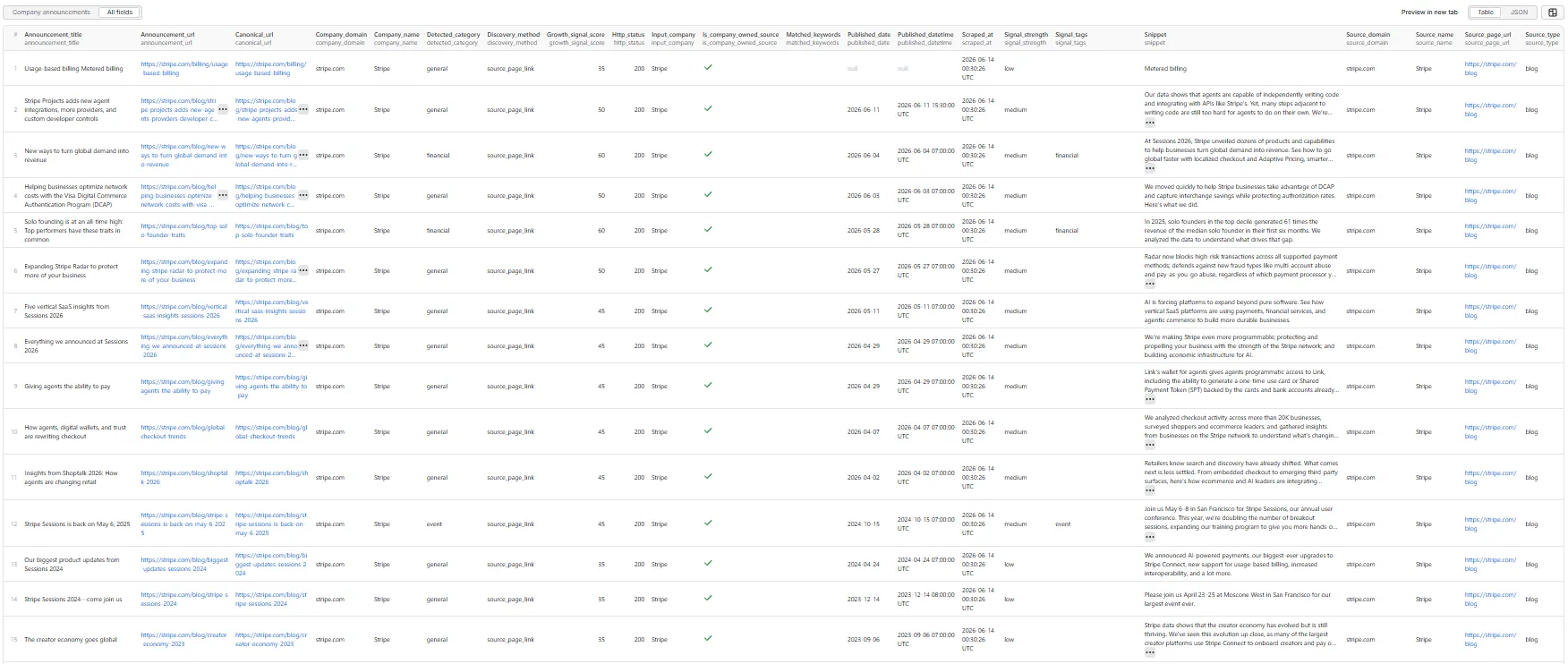
Sample record
A run summary is stored in the default key-value store under RUN_SUMMARY with counters such as inputs_total, sources_scanned, raw_results_found, results_saved, duplicates_removed, filtered_out, and charged_events.
Growth-signal score
A transparent 0–100 weighted sum (see PRD §7), based only on visible public fields:
+10base for any valid announcement+20company-owned source+15 / +10published within 30 / 90 days+15high-value category (funding,partnership,product_launch,expansion,customer_win)+10secondary category (leadership,financial,hiring,event)+10strong signal word (launches, raises, acquires, partners, expands, …)+5snippet present
Labels: 70–100 high, 40–69 medium, 0–39 low.
Pricing
Pay Per Event. One event, announcement-result, is charged only after a valid, unique announcement row is successfully pushed to the dataset. Duplicate announcements, filtered-out rows, failed fetches, source pages, and summary records are never charged. The actor honours your per-run spending limit and stops cleanly when it is reached.
🚦 Proxy policy
Use Apify Datacenter proxy or no proxy for normal runs — both work reliably for company news/RSS pages at this actor's conservative concurrency.
Apify Residential proxy is not supported. The actor fails at startup if apifyProxyGroups includes RESIDENTIAL. Reason: in pay-per-event actors, residential bandwidth (~$8/GB) is billed to the developer, not the run user, so a single bandwidth-heavy run could exceed the per-result event revenue.
If you genuinely need residential routing, supply your own residential provider via the proxy editor's Custom proxy URLs field — that traffic goes through your provider, not Apify, and is unaffected:
How sources are found
For each company the actor tries, in order of reliability:
- RSS/Atom feeds advertised by the homepage or a news/press/blog section (structured and fast).
- Common announcement paths —
/news,/newsroom,/company/news,/press,/press-releases,/media,/blog. - Schema.org
Article/NewsArticleJSON-LD and Open Graph metadata on those pages. - Visible article links on listing pages as a fallback.
- Free public search fallback when no company-owned source is found (may surface third-party
general_news).
Notes & limitations
- Coverage is strongest for companies that publish an RSS feed or a structured newsroom/blog; custom JavaScript-only pages with no feed, JSON-LD, or server-rendered links may yield few or no rows (this actor is HTTP-only by design — no headless browser).
- Dates are extracted conservatively and never invented; announcements without a reliable date keep
published_date: null. - Company-name inputs are resolved best-effort via free public search; supplying a domain or a direct source URL is more reliable.