Lever Hiring Intelligence Scraper
Pricing
from $1.80 / 1,000 job-results
Lever Hiring Intelligence Scraper
Scrape public job postings from Lever-hosted career boards (global + EU) into clean, CSV-ready hiring-intelligence rows - no login, cookies, or paid APIs.
Pricing
from $1.80 / 1,000 job-results
Rating
0.0
(0)
Developer
Delowar Munna
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
a month ago
Last modified
Categories
Share

Scrape public job postings from Lever-hosted career boards — by board URL or by site slug — and turn them into clean, flat, CSV-ready rows, plus lightweight hiring-intelligence fields (team/department, derived seniority & workplace type, salary visibility, detected skills, and a transparent hiring-signal score + reason tags). Built for recruiters, sales teams, staffing agencies, job-board operators, and market researchers.
No login, no cookies, no API keys. The actor uses Lever's public Postings API (?mode=json) over HTTP — one request returns every published posting for a board — so it stays fast and cost-predictable. You pay one flat event per unique job row that passes your filters.
✨ Why this scraper
- Lever-focused hiring intelligence — not a generic multi-ATS crawler. Every row carries derived signals useful for sales, recruiting, and market research.
- Global + EU boards —
jobs.lever.co/api.lever.coandjobs.eu.lever.co/api.eu.lever.co, with automatic region fallback. - Two input modes — paste Lever board/API URLs, or just list site slugs (
netflix,benchling,figma). - 31 flat fields — job identity, company, categories, dates, description, salary, and hiring signals. No nested objects; drops straight into Sheets/Excel/CRMs.
- Pay-Per-Event — one flat
job-resultevent per saved unique job. Duplicates and filtered rows are never charged. - No browser — pure HTTP + JSON, so it is fast and light.
🚀 Quick start — sample inputs
Example 1 — site slugs + filters
Example 2 — board URLs + remote-only + custom residential proxy via your own provider
Provide at least one of
startUrlsorsiteSlugs. URLs always use their own host's region; bare slugs use theregionsetting (autotries global first, then EU).
The actor blocks Apify Residential proxy; if you need residential routing, supply your own provider via
proxyConfiguration.proxyUrls. See 🚦 Proxy policy below.
📦 Output
The dataset has one view: Jobs & hiring signals — a 31-column flat table.
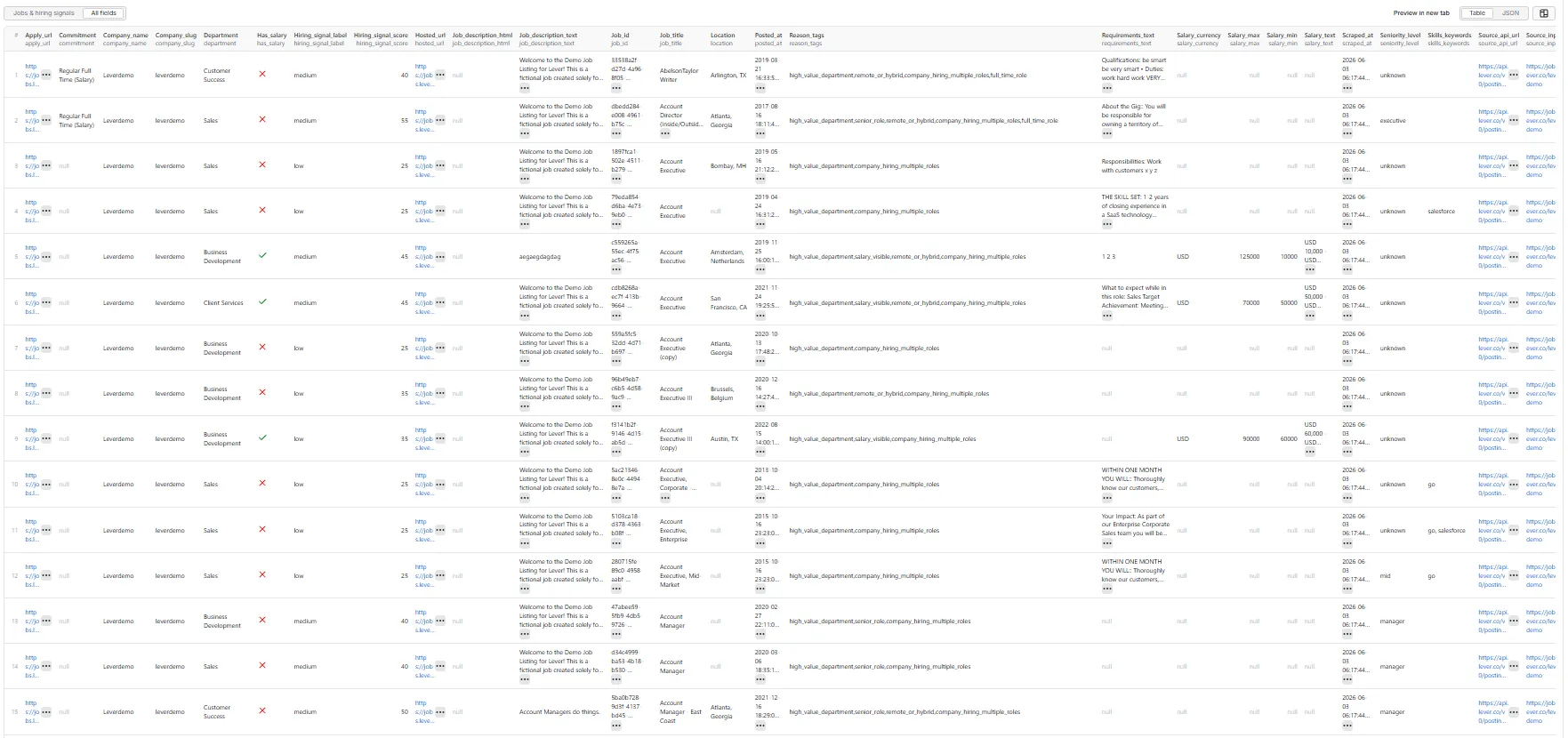
Output fields (31)
job_id, job_title, company_slug, company_name, team, department, location, commitment, workplace_type, seniority_level, posted_at, updated_at, hosted_url, apply_url, job_description_text, job_description_html, requirements_text, salary_text, salary_min, salary_max, salary_currency, has_salary, skills_keywords, hiring_signal_score, hiring_signal_label, reason_tags, source_platform, source_region, source_input, source_api_url, scraped_at.
Sample record — Jobs & hiring signals
Real actor output (from a run against Lever's public leverdemo board; the long text fields are truncated here with … for readability):
This sample is from Lever's public
leverdemoboard (demo data, sosalaryis empty and the description is placeholder text). On real company boards these fields populate from the live posting.
🎯 Hiring-signal score
Transparent rule-based score (0–100) computed from visible scraped fields — no AI, no external enrichment.
| Signal | Points |
|---|---|
| Posted within the last 14 days | +20 |
| Posted within the last 30 days (but over 14 days) | +15 |
| High-value department / role¹ | +15 |
| Seniority is manager / director / executive | +15 |
| Salary visible | +10 |
| Remote or hybrid | +10 |
| 3+ detected skills / tools | +10 |
| Company has 5+ open jobs in this run | +10 |
| Full-time commitment | +5 |
¹ sales, marketing, engineering, product, data, security, finance, operations, or customer success.
Score is capped at 100.
Labels: high (70–100) · medium (40–69) · low (0–39).
reason_tags is a comma-separated list explaining the score — e.g. recent_posting, high_value_department, senior_role, salary_visible, remote_or_hybrid, skills_detected, company_hiring_multiple_roles, full_time_role.
💰 Pricing
Pay-Per-Event. One flat event per saved row (final per-event price is configured on the Apify console):
| Event | Charged when |
|---|---|
job-result | Once per unique job row that passed all filters and was successfully written to the dataset. |
So your bill is simply results_saved × price_per_event. The actor honors the user-configured per-run spending cap (Apify eventChargeLimitReached): it caps how many results it collects up-front to what the limit can pay for, and stops cleanly the moment the cap is reached during charging.
Not charged:
- Duplicates (deduplicated by
job_id+company_slug+source_region, then canonicalhosted_url/apply_url). - Rows filtered out by query / location / team / commitment / workplace / seniority / date / remote-only filters.
- Empty boards, failed inputs, and rows missing a valid identity (
job_id/hosted_url+job_title+company_slug).
🚦 Proxy policy
Use Apify Datacenter proxy or no proxy for normal runs — both work reliably for Lever's public Postings API at this actor's conservative concurrency.
Apify Residential proxy is not supported. The actor will fail at startup if proxyConfiguration.apifyProxyGroups includes RESIDENTIAL. Reason: in pay-per-event actors, residential bandwidth (~/GB) is billed to the developer, not the run user, so a single bandwidth-heavy run could exceed the per-result event revenue.
If you genuinely need residential routing, supply your own residential provider via the proxy editor's Custom proxy URLs field — that traffic goes through your provider, not Apify, and is unaffected:
📊 Run summary
After each run, a RUN_SUMMARY entry is written to the key-value store:
charged_events equals the number of successfully saved unique rows.
⚙️ Filters
| Filter | Effect |
|---|---|
query | Case-insensitive substring across title, team, department, location, commitment, and description. |
locations | Keep jobs whose location matches any keyword. |
teams | Keep jobs whose team or department matches any keyword. |
commitments | Keep jobs whose commitment matches any keyword (e.g. Full-time, Contract, Internship). |
workplaceTypes | remote / hybrid / onsite / unknown (derived). |
seniorityLevels | intern / junior / mid / senior / lead / manager / director / executive / unknown. |
postedAfter | Keep jobs created on or after an ISO date (YYYY-MM-DD). |
remoteOnly | Keep only remote roles. |
deduplicate | Drop duplicates across overlapping inputs (recommended ON); keeps the most complete row. |
All filters are applied after extraction and before any dataset push or event charge.
🚧 Limitations (V1)
- Public Postings API only: published public jobs, no login/cookies/private Data API. No candidate, applicant, interview, or pipeline data.
company_nameis title-cased from the site slug (the public postings API does not expose a company display name).seniority_level/workplace_typeare derived from visible text (and Lever'sworkplaceTypewhen present); treat them as best-effort labels.salary_*comes from Lever's structuredsalaryRangewhen present, otherwise a best-effort parse of salary text in the description / requirements — no currency conversion. Most Lever boards do not publish salary, so these fields are often empty.updated_atis alwaysnull: Lever's public Postings API exposes only a creation timestamp (createdAt→posted_at), not a last-updated timestamp. The field is kept for schema stability.- No recruiter/contact extraction, email enrichment, company-website crawling, or AI scoring.
maxResultscaps saved unique rows across the whole run (not per board).
❓ FAQ
Do I need a Lever account or API key?
No. The actor only uses Lever's public Postings API (?mode=json).
What is a "site slug"?
The company segment of a Lever board URL — e.g. for https://jobs.lever.co/netflix the slug is netflix. You can paste full URLs in startUrls or just slugs in siteSlugs.
Global vs EU boards?
Both are supported. URLs use their own host's region; for bare slugs, region: "auto" tries the global API first and falls back to EU.
How is company_jobs_in_run reflected?
The hiring-signal score adds points when a company has 5+ jobs in the same run — a cheap hiring-demand signal computed across the run's saved set (no extra requests).
Can I export to CSV?
Yes — every field is flat (no nested objects). Use Apify's CSV / Excel export, or call the dataset API with format=csv.
🛠️ Technical notes
- Stack: Node.js 22 · Apify SDK 3 · Crawlee
HttpCrawler· native fetch · Cheerio (HTML→text only). No browser. - Endpoint: Lever public Postings API —
https://api.lever.co/v0/postings/{slug}?mode=json(and EUapi.eu.lever.co). - Concurrency:
min=1,max=5(conservative; tune after real runs). - Memory: 1 GB min · 2 GB default · 4 GB max.
- Proxy: Apify Proxy enabled by default; Datacenter/no-proxy/custom URLs accepted; Apify Residential rejected at startup.