Public ATS Hiring Signal Scraper
Pricing
from $1.80 / 1,000 job-results
Public ATS Hiring Signal Scraper
Scrape public Greenhouse, Lever, Ashby, SmartRecruiters, Workable and Recruitee job boards into clean, CSV-ready hiring-signal data - no login or cookies required.
Pricing
from $1.80 / 1,000 job-results
Rating
0.0
(0)
Developer
Delowar Munna
Maintained by CommunityActor stats
0
Bookmarked
2
Total users
1
Monthly active users
a month ago
Last modified
Categories
Share

Scrape public company ATS job boards — Greenhouse, Lever, Ashby, SmartRecruiters, Workable, and Recruitee — and turn open roles into clean, flat, CSV-ready hiring-signal data. Built for B2B sales teams, lead-gen agencies, recruiters, staffing firms, market researchers, and VC/startup analysts who want company-level hiring intelligence, not just raw job listings.
No login, no cookies, no session tokens, no residential proxy. The actor reads each ATS over its public JSON endpoints (with a small HTML provider-detection fallback for company career pages), so it stays fast and cost-predictable. You pay one flat event per unique job row that passes your filters.
✨ Why this scraper
- Hiring-intelligence focused — every row carries derived signals (department, remote type, seniority, role category, detected technologies, salary when visible, and a transparent hiring-signal score) useful for sales triggers, recruiting, and market research.
- Six ATS providers, one schema — Greenhouse, Lever, Ashby, SmartRecruiters, Workable, Recruitee, all normalized into the same flat row.
- Two input modes — paste board/career URLs (provider auto-detected), or give known boards by
provider+slug. - Flat, CSV-friendly output — no nested objects; drops straight into Sheets/Excel/CRMs.
- Pay-Per-Event — one flat
job-resultevent per saved unique job. Duplicates, filtered, and invalid rows are never charged. - No AI, no enrichment costs — rule-based derivations only, from visible scraped fields.
🚀 Quick start — sample inputs
Example 1 — board/career URLs (provider auto-detected)
Example 2 — known boards by provider + slug, remote-only, with your own proxy
Provide at least one of
startUrlsorcompanySlugs. If you provide both, the actor runs both and deduplicates across the whole run.
The actor blocks Apify Residential proxy; if you need residential routing, supply your own provider via
proxyConfiguration.proxyUrls. See 🚦 Proxy policy below.
📦 Output
The dataset has one view: Jobs & hiring signals — a flat 33-column table.
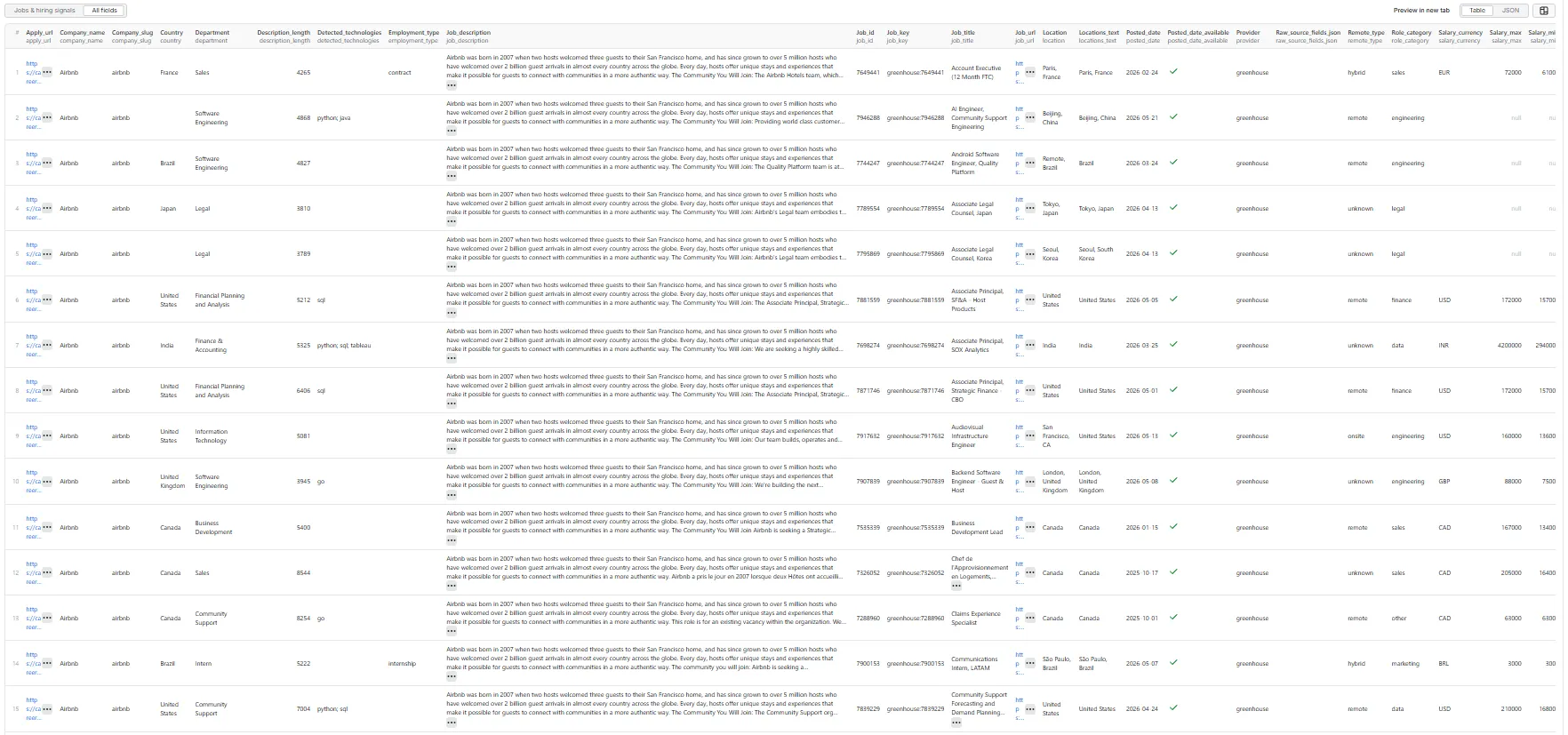
Output fields (33)
job_id, job_key, provider, company_name, company_slug, job_title, department, team, location, locations_text, country, remote_type, employment_type, seniority, role_category, salary_min, salary_max, salary_currency, salary_period, job_description, description_length, detected_technologies, signal_score, signal_label, signal_tags, posted_date, posted_date_available, apply_url, job_url, source_url, source_type, raw_source_fields_json, scraped_at.
Sample record — Jobs & hiring signals
(Real run output; job_description truncated here for readability.)
🎯 Hiring-signal score
Transparent rule-based score (0–100) computed only from visible scraped fields — no AI, no external enrichment.
| Signal | Points |
|---|---|
| Company has 5+ open jobs in this run | +20 |
| Company has 15+ open jobs in this run | +15 |
| Role is engineering, data, sales, or product | +10 |
| Seniority is senior, lead, or executive | +10 |
| Remote or hybrid | +10 |
| At least one technology detected | +10 |
| Salary / compensation visible | +10 |
| Description longer than 800 characters | +10 |
| Posted within the last 30 days | +5 |
| Growth language in title (growth, expansion, scale, …) | +5 |
Score is capped at 100. Labels: low (0–39) · medium (40–69) · high (70–100).
signal_tags is a semicolon-separated list explaining the score — e.g. many_open_roles, large_hiring_batch, revenue_role, technical_role, senior_role, remote_hiring, tech_stack_visible, salary_visible, detailed_job_description, recent_posting, growth_language. The score is a transparent sorting aid, not a prediction.
💰 Pricing
Pay-Per-Event. One flat event per saved row (final per-event price is configured on the Apify console):
| Event | Charged when |
|---|---|
job-result | Once per unique job row that passed all filters and was successfully written to the dataset. |
So your bill is simply results_saved × price_per_event. The actor honors the user-configured per-run spending cap (Apify eventChargeLimitReached): it caps how many results it collects up-front to what the limit can pay for, and stops cleanly the moment the cap is reached.
Not charged: duplicates, filtered-out rows, invalid rows (missing title and URL/ID), failed sources, or provider-discovery attempts.
🚦 Proxy policy
Use Apify Datacenter proxy or no proxy for normal runs — both work reliably for public ATS endpoints at this actor's conservative concurrency.
Apify Residential proxy is not supported. The actor will fail at startup if proxyConfiguration.apifyProxyGroups includes RESIDENTIAL. Reason: in pay-per-event actors, residential bandwidth (~/GB) is billed to the developer, not the run user, so a single bandwidth-heavy run could exceed the per-result event revenue.
If you genuinely need residential routing, supply your own residential provider via the proxy editor's Custom proxy URLs field — that traffic goes through your provider, not Apify, and is unaffected:
📊 Run summary
After each run, a RUN_SUMMARY entry is written to the key-value store:
charged_events equals the number of successfully saved unique rows.
⚙️ Filters
| Filter | Effect |
|---|---|
includeKeywords / excludeKeywords | Case-insensitive match on title, department, team, location, and description. Exclusion wins. |
locationQuery | Case-insensitive substring on location, locations text, and country. |
remoteOnly | Keep only jobs classified as remote. |
departments | Match against department, team, and role category. |
postedAfter (YYYY-MM-DD) | Minimum posted date; rows with no reliable date are kept (posted_date_available=false). |
dedupe | Remove duplicates across sources and repeated URLs (recommended ON). |
Filters are applied before any dataset push or event charge.
🚧 Limitations (V1)
- Public board data only — no login, cookies, or member-only content.
- Some providers (SmartRecruiters, Workable) expose the description only on a per-job detail call; turning
includeDescriptionoff skips those calls (faster, fewer fields). - Salary is populated only when a provider exposes explicit compensation — Greenhouse pay-transparency ranges, Ashby's structured salary component, Lever, and Recruitee. It is never inferred from free text.
- Employment type comes from the provider's own field where available (Lever, Ashby, SmartRecruiters, Workable, Recruitee). For Greenhouse (which has no employment-type field), it is inferred conservatively from the title and a few high-confidence description phrases, and is left empty when not certain.
- Posted date is normalized to
YYYY-MM-DDonly where the provider exposes a reliable date; otherwiseposted_date_available=false. - No recruiter/contact extraction, email enrichment, company-website crawling, LinkedIn enrichment, or AI scoring.
- Company career pages are resolved only when they embed a supported ATS board link.
❓ FAQ
Do I need an account or cookies for any board? No. The actor only uses public ATS endpoints. Boards that require login are marked unsupported and skipped.
Which providers are supported? Greenhouse, Lever, Ashby, SmartRecruiters, Workable, and Recruitee.
Can I just paste a company careers page URL?
Yes — put it in startUrls. If it embeds a supported ATS board, the actor detects the provider and slug automatically. Otherwise it's recorded as unsupported and the run continues.
Why are some rows missing salary or posted date? Those fields only appear when the provider exposes them. Salary is never guessed; posted date is kept only when reliable.
Can I export to CSV?
Yes — every field is flat. Use Apify's CSV / Excel export, or call the dataset API with format=csv.
Will I get blocked? The actor uses conservative concurrency, realistic headers, session rotation, and retry/backoff. Default Apify Proxy is sufficient for typical runs; supply your own proxy for very large runs.
🛠️ Technical notes
- Stack: Node.js 22 · Apify SDK 3 · Crawlee
HttpCrawler(JSON-first) · nativefetch/got-scraping. No browser. - Endpoints: each provider's public job-board JSON API (Greenhouse boards API, Lever postings, Ashby posting-api, SmartRecruiters postings, Workable accounts API, Recruitee offers).
- Concurrency:
min=1,max=10(conservative; tune after real runs). - Memory: 1 GB min · 2 GB default · 4 GB max.
- Proxy: Apify Proxy enabled by default; custom configs accepted; Apify Residential rejected at startup.
- Modular adapters: each provider lives in its own
src/providers/*.jsfile with a uniform interface, ready to lift into single-provider clone actors.