LinkedIn Company Profile Scraper
Pricing
from $2.40 / 1,000 company-results
LinkedIn Company Profile Scraper
Scrape public LinkedIn company pages in bulk and return clean company intelligence (name, industry, website, size, HQ, founded year, specialties, follower/employee signals, locations, profile URLs). Flat CSV-ready output. No login or cookies.
Pricing
from $2.40 / 1,000 company-results
Rating
0.0
(0)
Developer
Delowar Munna
Maintained by CommunityActor stats
0
Bookmarked
4
Total users
1
Monthly active users
2 months ago
Last modified
Categories
Share

Scrape public LinkedIn company pages in bulk and turn them into clean, flat, CSV-ready rows — name, industry, website, company size, headquarters, founded year, specialties, follower / employee signals, locations, and profile URLs. Built for B2B sales teams, lead generation, agencies, recruiters, market researchers, and enrichment workflows.
No LinkedIn login, no cookies, no session IDs, no people scraping. The actor visits each public company profile page directly over HTTP and parses the SSR-ed HTML (JSON-LD Organization → og: tags → visible top-card markup). You pay one flat event per unique company row that passes your filters.
✨ Why this scraper
- Company-first — public company intelligence only. No people scraping, no posts, no email enrichment, no login.
- Bulk input — paste a list of LinkedIn company URLs and/or company slugs.
- 30 flat fields — identity, profile, web, location, derived flags, completeness score. No nested objects, drops straight into Sheets / Excel / CRMs.
- Pay-Per-Event — one flat
company-resultevent per saved unique company. Duplicates, filtered rows, and failed pages are never charged. - No login / cookies / sessions — just URLs or slugs.
- Transparent profile-completeness score — rule-based (no AI), explained below.
🚀 Quick start — sample inputs
Example 1 — bulk URLs + slugs
Example 2 — filtered by industry + minimum followers, custom residential proxy
Provide at least one of
companyUrlsorcompanySlugs. Slugs are converted to canonicalhttps://www.linkedin.com/company/<slug>URLs and merged with the URL list (deduplicated by canonical URL).
The actor blocks Apify Residential proxy; if you need residential routing, supply your own provider via
proxyConfiguration.proxyUrls. See 🚦 Proxy policy below.
📦 Output
The dataset has one view: Company profiles — a 30-column flat table.
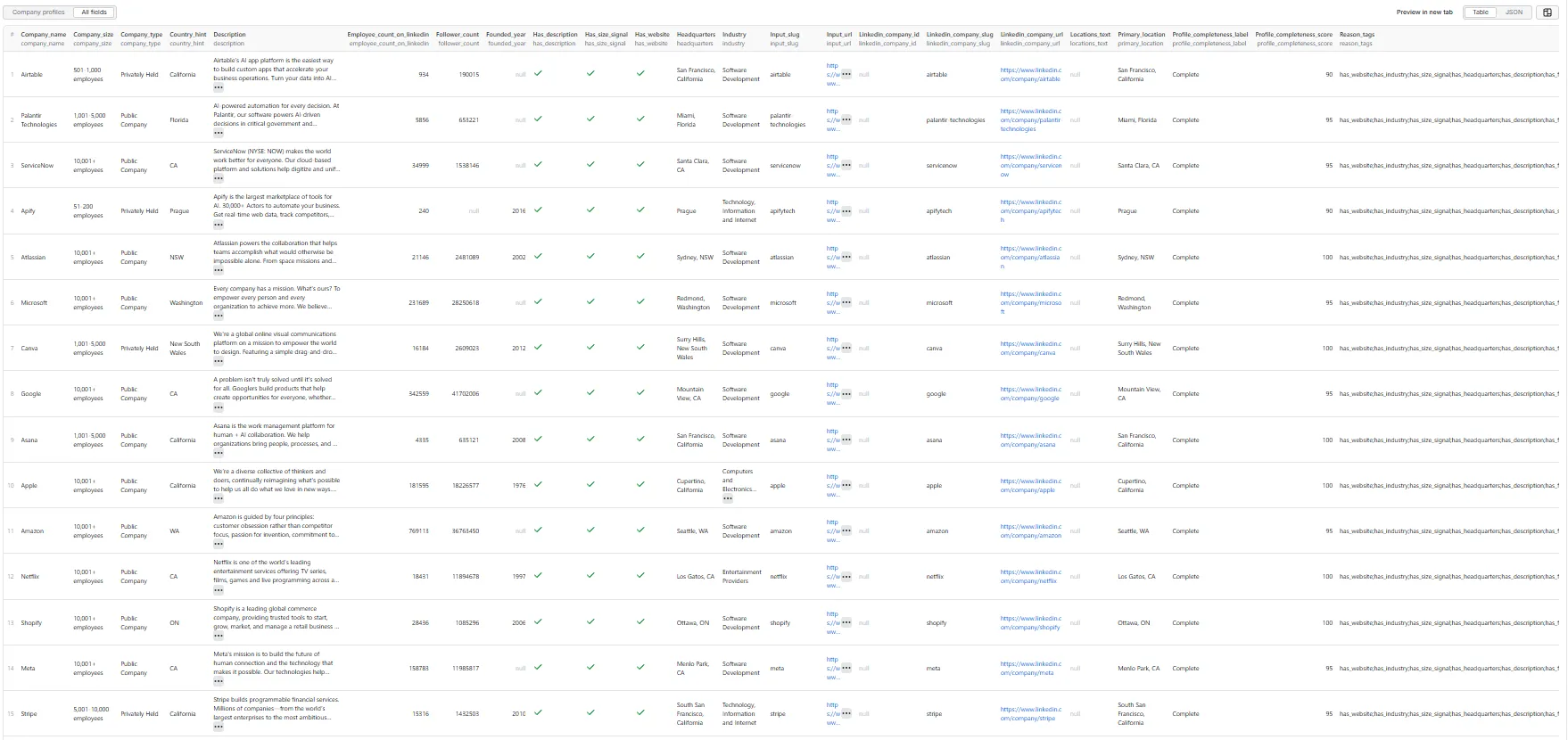
Output fields (30)
input_url, input_slug, source_type, linkedin_company_url, linkedin_company_slug, linkedin_company_id, company_name, tagline, description, industry, company_size, employee_count_on_linkedin, follower_count, company_type, founded_year, specialties, website, website_domain, headquarters, locations_text, primary_location, country_hint, has_website, has_description, has_size_signal, profile_completeness_score, profile_completeness_label, reason_tags, scrape_status, scraped_at.
Sample record — Company profiles
(Real run output.)
🎯 Profile-completeness score
Transparent rule-based score (0–100) computed from extracted fields — no AI, no external enrichment.
| Signal | Points |
|---|---|
| Company name found | +20 |
| Website found | +15 |
| Industry found | +15 |
| Company size or employee count found | +10 |
| Headquarters or primary location found | +10 |
| Description found | +10 |
| Follower count found | +10 |
| Founded year found | +5 |
| Specialties found | +5 |
Score is capped at 100.
Labels: Complete (80–100) · Good (60–79) · Partial (40–59) · Sparse (0–39).
reason_tags is a ;-separated list of which signals fired (e.g. has_website;has_industry;has_size_signal;has_followers;has_specialties, plus missing_website or partial_profile when applicable).
💰 Pricing
Pay-Per-Event. One flat event per saved row (final per-event price is configured on the Apify console):
| Event | Charged when |
|---|---|
company-result | Once per unique company row that passed all filters and was successfully written to the dataset. |
So your bill is simply results_saved × price_per_event. The actor honors the user-configured per-run spending cap (Apify eventChargeLimitReached): it both caps how many results it collects up-front to what the limit can pay for, and stops cleanly the moment the cap is reached during charging.
Not charged:
- Duplicates (deduplicated by company ID, canonical URL, slug, or name + domain / location).
- Rows filtered out by website / industry / location / followers / employee-count filters.
- Rows missing both
company_nameandlinkedin_company_url. - Failed or blocked requests.
🚦 Proxy policy
Use Apify Datacenter proxy or no proxy for normal runs — both work for LinkedIn's public company profile pages at this actor's conservative concurrency.
Apify Residential proxy is not supported. The actor will fail at startup if proxyConfiguration.apifyProxyGroups includes RESIDENTIAL. Reason: in pay-per-event actors, residential bandwidth (~/GB) is billed to the developer, not the run user, so a single bandwidth-heavy run could exceed the per-result event revenue.
If you genuinely need residential routing, supply your own residential provider via the proxy editor's Custom proxy URLs field — that traffic goes through your provider, not Apify, and is unaffected:
📊 Run summary
After each run, a RUN_SUMMARY entry is written to the key-value store:
charged_events equals the number of successfully saved unique rows.
⚙️ Filters
| Filter | Effect |
|---|---|
requiredWebsite | Drop rows with no website value. |
industryKeywords | Case-insensitive substring across industry, specialties, description. Missing fields fail the filter. |
locationKeywords | Case-insensitive substring across headquarters, primary_location, locations_text. Missing = fails. |
minFollowers | Drop rows with follower_count < minFollowers. Missing follower count fails when minFollowers > 0. |
minEmployeeCount | Drop rows with employee_count_on_linkedin < minEmployeeCount. Missing fails when minEmployeeCount > 0. |
includeShowcasePages | When false, linkedin.com/showcase/* URLs are skipped at input time as invalid. |
deduplicate | Remove duplicates by company ID → canonical URL → slug → name + domain → name + location. Richer kept. |
Filters are applied before any dataset push or event charge.
🚧 Limitations (V1)
- Public profile data only: no login, cookies, or member-only content. Fields that LinkedIn does not expose publicly for a given company stay
null. - No people, posts, jobs, emails, or website crawling. Out of scope for V1.
- No Sales Navigator / private / gated fields.
maxResultscaps saved unique rows across the whole run (not per input).partial_successrows may have minimal fields when LinkedIn returns an auth-walled page that still exposes name / URL via meta tags.
❓ FAQ
Do I need a LinkedIn account or cookies? No. The actor only visits public LinkedIn company pages.
What if I only have company slugs, not full URLs?
Use the companySlugs field. Slugs like microsoft or apifytech are converted to https://www.linkedin.com/company/<slug> automatically.
Why are some rows marked partial_success?
LinkedIn occasionally returns an auth-walled response with only meta-tag identity (name + URL) and not the full top-card / about-card. Those rows still push when they have enough identity — flagged so you can filter them out downstream.
How is dedup done?
Priority order: company ID → canonical URL → slug → normalized company_name + website_domain → normalized company_name + primary_location. The richer record (more non-empty fields, success over partial) is kept on collision.
Can I export to CSV?
Yes — every field is flat (no nested objects). Use Apify's CSV / Excel export, or call the dataset API with format=csv.
Will I get blocked? The actor uses conservative concurrency, realistic headers, session rotation, and retry / backoff. Default Apify Proxy is sufficient for typical small / medium runs. For large runs, supply your own proxy provider via Custom proxy URLs.
🛠️ Technical notes
- Stack: Node.js 22 · Apify SDK 3 · Crawlee
CheerioCrawler· Cheerio + native fetch. No browser. - Extraction priority: JSON-LD
Organization→og:/ Twitter meta tags → visible top-card / about-card HTML. - Concurrency:
min=1,max=5(conservative; tune after real runs). - Memory: 1 GB min · 2 GB default · 4 GB max.
- Proxy: Apify Proxy enabled by default; custom configs accepted; Apify Residential rejected at startup.