Cloudflare Web Scraper
Pricing
$15.00/month + usage
Cloudflare Web Scraper
Advanced web scraper designed to extract data from Cloudflare-protected websites with CAPTCHA bypass, proxy rotation, and JavaScript execution capabilities.
Pricing
$15.00/month + usage
Rating
3.3
(3)
Developer
ecomscrape
Maintained by CommunityActor stats
10
Bookmarked
799
Total users
13
Monthly active users
7.6 days
Issues response
5 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
What does Cloudflare web Scraper do?
Introduction
Cloudflare protection systems present significant challenges for web scraping, with each website setting custom anti-bot thresholds and verification requirements. Millions of websites rely on Cloudflare's security features, including CAPTCHA challenges, bot detection algorithms, and rate limiting mechanisms that can block legitimate data collection efforts.
The Cloudflare Web Scraper addresses these challenges by providing a comprehensive solution for accessing protected websites. This tool becomes essential when businesses need to collect market data, monitor competitor pricing, gather research information, or perform automated testing on Cloudflare-protected platforms where manual access would be time-prohibitive.
Scraper Overview
The Cloudflare Web Scraper is a sophisticated data extraction tool specifically engineered to handle modern web protection mechanisms. By utilizing proxy rotation and residential IP addresses, the scraper mimics natural browsing patterns to avoid detection.
Key advantages include automated CAPTCHA handling, JavaScript execution capabilities, and intelligent retry mechanisms. The scraper maintains session persistence, handles dynamic content loading, and provides detailed logging for troubleshooting. It's designed for developers, data analysts, researchers, and businesses requiring reliable access to protected web resources.
The tool excels in scenarios requiring large-scale data collection, real-time monitoring, and automated workflows where manual intervention isn't feasible.
Input and Output Specifications
Example url 1: https://gitlab.com
Example url 2: https://www.manta.com/
Example url 3: https://www.cardmarket.com/en
Example Screenshot of product information page:
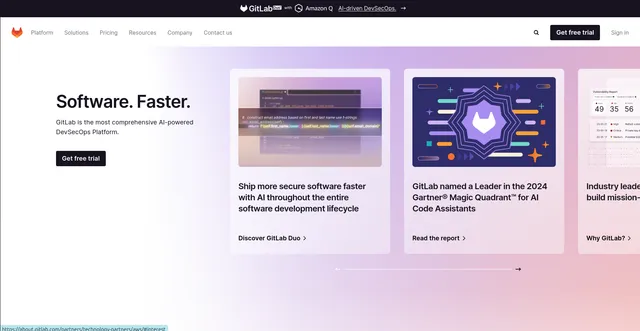
Input Format
The scraper accepts JSON configuration with the following parameters:
Input:
Configuration Structure:
max_retries_per_url(integer): Defines maximum retry attempts when encountering failures or timeoutsproxy(object): Contains proxy configuration for anonymizationuseApifyProxy(boolean): Enables Apify's proxy service integrationapifyProxyGroups(array): Specifies proxy types, typically "RESIDENTIAL" for better success ratesapifyProxyCountry(string): Target country code matching data collection requirements
urls(array): List of target URLs for data extractionjs_script(string): Custom JavaScript code executed on each pagejs_timeout(integer): Maximum execution time for JavaScript operationsretrieve_result_from_js_script(boolean): Whether to capture JavaScript execution resultspage_is_loaded_before_running_script(boolean): Ensures DOM readiness before script executionexecute_js_async(boolean): Controls synchronous vs asynchronous JavaScript executionretrieve_html_from_url_after_loaded(boolean): Captures final HTML after all processing
Output Format
You get the output from the Idealo.de product scraper stored in a tab. The following is an example of the Information Fields collected after running the Actor.
The scraper returns structured data containing three primary components:
URL Field: Contains the processed website address, confirming successful navigation and any redirects encountered. This field helps verify that the correct page was accessed and provides tracking for batch operations.
HTML Field: Delivers the complete page HTML after Cloudflare challenges are resolved and dynamic content is loaded. This includes all rendered elements, loaded JavaScript content, and any dynamically inserted data that wouldn't be visible in the initial page source.
Result from JS Script: Contains the return value from the custom JavaScript code execution. This field enables extraction of specific data points, computed values, or complex page interactions that require JavaScript processing. The result format depends on the script's return statement and can include strings, numbers, objects, or arrays.
Usage Instructions
Step 1: Configuration Setup Configure your input parameters based on target website requirements. Choose appropriate proxy countries and set reasonable retry limits to balance success rates with execution time.
Step 2: URL Preparation Ensure target URLs are accessible and specify the exact pages needed for data extraction. Test a small batch first to verify configuration effectiveness.
Step 3: JavaScript Customization Write JavaScript code tailored to your data extraction needs. Common patterns include DOM element selection, data parsing, and API calls. Test scripts in browser console first.
Step 4: Execution Monitoring Monitor scraper progress through logs and handle any errors appropriately. For persistent CAPTCHA challenges, consider integrating solver services for automated resolution.
Best Practices:
- Use residential proxies for better success rates
- Implement reasonable delays between requests
- Handle dynamic content loading properly
- Monitor for changes in website protection mechanisms
Benefits and Applications
Time Efficiency: Automates complex bypass procedures that would require significant manual effort, enabling 24/7 data collection operations without human intervention.
Real-World Applications: Market research, competitive analysis, price monitoring, content aggregation, and compliance monitoring. Businesses use this for tracking product availability, monitoring competitor strategies, and gathering industry intelligence.
Business Value: Provides access to previously unavailable data sources, enabling data-driven decision making and competitive advantages. Organizations can maintain current market awareness and respond quickly to industry changes.
Scalability: Handles multiple URLs simultaneously with built-in error handling and retry mechanisms, making it suitable for enterprise-level data collection requirements.
Conclusion
The Cloudflare Web Scraper provides a robust solution for accessing protected web content efficiently. By combining advanced bypass techniques with customizable JavaScript execution, it enables reliable data extraction from challenging sources.
Ready to overcome Cloudflare protection barriers? Configure your scraper parameters and start collecting valuable web data today.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about Cloudflare web Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.


