Goat Product Search Scraper
Pricing
$15.00/month + usage
Goat Product Search Scraper
Extract verified sneaker and apparel data from GOAT.com marketplace. Get product IDs, prices, release dates, and images from the leading authentication platform.
Pricing
$15.00/month + usage
Rating
0.0
(0)
Developer
ecomscrape
Maintained by CommunityActor stats
0
Bookmarked
30
Total users
1
Monthly active users
5 months ago
Last modified
Categories
Share
Contact
If you encounter any issues or need to exchange information, please feel free to contact us through the following link: My profile
GOAT.com Product Search Scraper
The sneaker resale market has exploded into a multi-billion dollar industry, with GOAT hitting $2 billion in gross merchandise value (GMV) over the last 12 months. As the global platform for the greatest products from the past, present and future, GOAT.com stands as the premier authenticated marketplace for sneakers, apparel, and accessories. For businesses, researchers, and developers looking to access this valuable product data, manual collection is time-consuming and inefficient. Our GOAT.com Product Search Scraper solves this challenge by automating data extraction from this authenticated marketplace.
Why Scrape GOAT.com?
GOAT not only acts as a marketplace between buyers and sellers, but also verifies the authenticity of sneakers (to combat the many fake and counterfeits in the sneaker resale market). This makes GOAT's data uniquely valuable - every product listed has been verified for authenticity using proprietary AI technology. The platform features new releases, iconic styles and exclusive collaborations from Nike and Air Jordan to adidas and New Balance, making it an essential data source for:
- Market researchers analyzing sneaker trends and pricing
- Retailers monitoring competitor pricing and inventory
- Investment analysts tracking luxury goods markets
- E-commerce platforms seeking authentic product data
- Brand managers monitoring resale market performance
GOAT.com Scraper Overview
Our scraper efficiently extracts comprehensive product information from GOAT's authenticated marketplace. Built with advanced proxy rotation and retry mechanisms, it ensures reliable data collection while respecting the platform's infrastructure. The scraper handles dynamic content loading and provides structured output suitable for immediate analysis or database integration.
Key Features:
- Automatic retry handling for reliable data extraction
- Residential proxy support to avoid detection
- Country-specific proxy selection for localized data
- Configurable item limits per URL
- Structured JSON output with essential product fields
Target Users:
- Market research companies analyzing sneaker trends
- E-commerce businesses monitoring pricing strategies
- Data analysts studying luxury goods markets
- Developers building sneaker-focused applications
Input Configuration
Example url 1: https://www.goat.com/search?query=Jordan%204
Example url 2: https://www.goat.com/search?query=t-shirt
Example url 3: https://www.goat.com/apparel/outerwear
Example Screenshot of product information page:
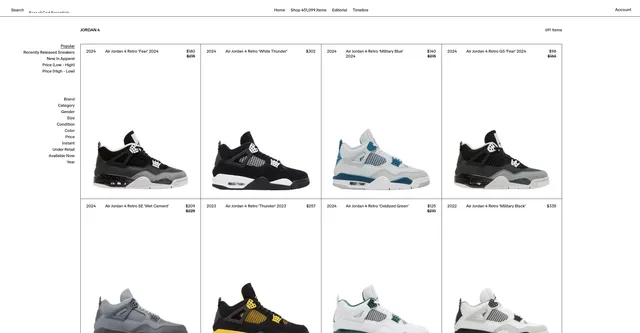
Input Format
The scraper accepts configuration through a JSON object with several key parameters:
Scrape with URLs:
The urls parameter: List of product list page URLs that you want to scrape. You can add URLs one by one, or use the Bulk edit section to add a prepared list.
The ignore_url_failures parameter: If set to true, the scraper will continue running even if some URLs fail to be scraped after reaching the maximum number of retries. This ensures that one problematic URL doesn't stop your entire scraping job.
When you provide a list of URLs for scraping, all options in the "Scrape with search filters" section will be disabled. The system will only collect data from the URLs you specified.
Scrape with Search Filters:
The keyword parameter: The search keyword to find products (e.g., "Jordan 4", "Yeezy", "Nike Dunk", "hoodie").
The gender parameter: Filter products by gender/category:
"men"- Men's items"women"- Women's items"youth"- Youth items"infant"- Infant items
The condition parameter: Filter products by condition:
"new_no_defects"- New (no defects)"used"- Used"new_with_defects"- New with Defects
The sort_by parameter: Sort products by various criteria:
"popular"- Popular (most popular first)"new_in_apparel"- New In (Apparel) - latest arrivals"price_low_high"- Price (low to high)"price_high_low"- Price (high to low)
The page parameter: Starting page number for scraping, useful for continuing interrupted scrapes or targeting specific result ranges.
When using search filters for scraping, you need to leave the urls field empty (or set it to null) in the "Scrape with URLs" configuration.
General Options:
The max_items_per_url parameter: Limits the number of products extracted from each product list page or search results page. The default value is 20, providing a manageable batch size while allowing for comprehensive data collection.
The max_retries_per_url parameter: Sets the maximum number of retry attempts for each URL or search filters if the scrape is detected as a bot or the page fails to load. The default value is 2, providing a good balance between thoroughness and efficiency.
The proxy parameter: Proxy configuration is essential for maintaining anonymity and avoiding detection. The residential proxy option ensures that your scraping activities appear as legitimate browsing, reducing the risk of being blocked or rate-limited. You should choose a country that matches the location of the website you're scraping (e.g., US for goat.com).
Output:
The scraper returns structured data with six essential fields for each extracted product:
Output Fields Explained:
- Id: GOAT's unique product identifier, typically corresponding to the style code. Essential for tracking specific products across different listings and variations.
- Url: Direct link to the product page on GOAT. Useful for deep-linking, verification, and accessing additional product details.
- Title: Complete product name including brand, model, colorway, and year. Critical for product identification and catalog matching.
- Release Date: Original release date in YYYY-MM-DD format. Valuable for analyzing product age, investment potential, and historical pricing trends.
- Price: Current market price in cents (multiply by 100). GOAT displays the lowest available price, making this field crucial for pricing analysis.
- Currency: Price currency code (USD, EUR, etc.). Important for international market analysis and currency conversion.
- Image Url: High-resolution product image link. Essential for visual product catalogs, authentication verification, and marketing materials.
Usage Instructions
Step 1: Choose Your Scraping Approach
Option A - URL-Based Configuration: Navigate to GOAT.com and use the website's navigation and search features to find the products you need. Input GOAT product list page URLs or search result pages. Copy the complete URLs ensuring they are properly formatted and accessible.
Option B - Filter-Based Configuration: Define your search parameters using the built-in filters:
- Set
keywordfor specific products (e.g., "Jordan 4", "Yeezy 350", "Nike Dunk") - Select
genderto target specific categories (men, women, youth, infant) - Choose
conditionto filter by item state (new, used, new with defects) - Select
sort_byto organize results (popular, new arrivals, price sorting) - Set
pageto start from a specific results page
Step 2: Set Proxy Configuration Use residential proxies with US country selection for best results and reduced blocking. GOAT.com is primarily US-based, so US proxies provide optimal performance.
Step 3: Configure Additional Parameters
Set your desired retry limits (max_retries_per_url), item limits (max_items_per_url), and enable ignore_url_failures to ensure robust scraping.
Step 4: Run Extraction Execute the scraper and monitor progress through the provided logging system.
Step 5: Process Output The structured JSON output can be directly imported into databases, spreadsheets, or analysis tools for further analysis.
Best Practices:
Method Selection:
- Use URL-based scraping for specific product categories or complex search queries with multiple filters
- Use filter-based scraping for keyword searches with standard filtering options
- Combine both approaches: use filters for product discovery, then URLs for targeted collection
Scraping Strategy:
- Limit concurrent requests to avoid overwhelming GOAT's servers
- Use US residential proxies to maintain access reliability
- Monitor extraction logs for any blocked requests
- Implement delays between batches for sustainable scraping
- Regularly update your URL list or search keywords to capture new releases
Filter Optimization:
- Gender/Category Strategy: Target specific demographics by filtering by
gender(men, women, youth, infant) - Condition Analysis: Use
conditionfilters to analyze pricing differences between new and used items - Sorting Strategy:
- Use
"popular"to identify trending products - Use
"new_in_apparel"to track latest releases - Use
"price_low_high"for budget-conscious research or finding deals - Use
"price_high_low"to identify premium or rare items
- Use
Advanced Filter Combinations:
- Budget finds:
keyword: "Nike", condition: "used", sort_by: "price_low_high" - Latest releases:
keyword: "Jordan", condition: "new_no_defects", sort_by: "new_in_apparel" - Premium items:
gender: "men", condition: "new_no_defects", sort_by: "price_high_low" - Youth market:
keyword: "sneakers", gender: "youth", sort_by: "popular"
Common Use Cases:
- Market Research: Use filter combinations to analyze pricing trends across different conditions and categories
- New Release Tracking: Use
sort_by: "new_in_apparel"with specifickeywordto monitor latest drops - Price Comparison: Compare prices across different
conditionfilters for the same product - Demographic Analysis: Use
genderfilters to segment product data by target audience
Troubleshooting:
Empty Results:
- For filter-based: Verify keyword spelling and try broader terms
- Test different
genderorconditioncombinations - Ensure the product category exists on GOAT
Access Issues:
- Verify you're using US residential proxies
- Enable
ignore_url_failuresto continue despite some failures - Adjust retry limits if experiencing frequent timeouts
Data Quality:
- Validate extracted data for completeness, especially pricing and size availability
- For filter-based searches, confirm results match your search criteria
- Monitor for changes in GOAT's website structure that might affect extraction
Business Applications and Benefits
Our GOAT.com scraper delivers significant time savings and competitive advantages. Manual data collection from GOAT can take hours per hundred products, while automated extraction completes the same task in minutes. The authenticated nature of GOAT's marketplace means you're accessing verified, high-quality product data that's immediately actionable.
Key Benefits:
- Market Intelligence: Track pricing trends and identify investment opportunities in authenticated sneakers
- Competitive Analysis: Monitor competitor inventory levels and pricing strategies
- Product Catalogs: Build comprehensive databases of authenticated products with verified details
- Investment Research: Analyze historical pricing data to identify appreciating assets
- Brand Monitoring: Track how specific brands perform in the resale market
Conclusion
The GOAT.com Product Search Scraper transforms manual data collection into an automated, efficient process. By extracting authenticated product data from the leading sneaker marketplace, you gain access to verified information that drives informed business decisions. Whether you're conducting market research, monitoring competitor pricing, or building product catalogs, this tool delivers the reliable data you need.
Ready to automate your GOAT.com data collection? Start extracting authenticated sneaker marketplace data today and gain the competitive edge that comes from actionable market intelligence.
Related Actors
- Goat.com Product Details Page Scraper: A streamlined automation tool that extracts product data from product details page in Goat.com and converts it into structured JSON format.
Your feedback
We are always working to improve Actors' performance. So, if you have any technical feedback about Goat.com Product Search Scraper or simply found a bug, please create an issue on the Actor's Issues tab in Apify Console.