GC7 01 SimpleRequest
DeprecatedPricing
Pay per usage
Go to Apify Store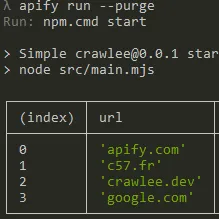

GC7 01 SimpleRequest
DeprecatedSimple Request title from url (Requête du titre de la page depuis une URL) - Retrieve the page title from a list of URLs and display the result in a table sorted by URL (Requête du titre de la page depuis une URL et affiche le résultat sous forme de tableau)
Pricing
Pay per usage
Rating
0.0
(0)
Developer
GC7
Maintained by CommunityActor stats
1
Bookmarked
1
Total users
1
Monthly active users
2 years ago
Last modified
Categories
Share