Facebook Posts Scraper
Pricing
from $2.00 / 1,000 posts
Facebook Posts Scraper
Extract posts, videos, and engagement metrics from Facebook pages. Get text captions, reactions, video transcripts, images, external links, collaborators, and more from Facebook pages and profiles. Export ad data, schedule runs via API, and integrate with other tools or AI workflows.
Pricing
from $2.00 / 1,000 posts
Rating
4.6
(204)
Developer
Apify
Maintained by ApifyActor stats
1.1K
Bookmarked
91K
Total users
11K
Monthly active users
2.1 days
Issues response
9 hours ago
Last modified
Categories
Share
What is Facebook Posts Scraper?
It's a simple but powerful Facebook post extractor that allows you to scrape posts from Facebook pages and profiles. To get that data, just insert the page or profile URL and click "Save & Start" button. With this post scraper tool, you can crawl Facebook posts and download all posts from Facebook page beyond the limitations of the Facebook API:
🗂 Scrape multiple Facebook pages at once
📝 Extract key post data: text, URLs, timestamps, engagement metrics, and thumbnails
👍 Get number of shares, likes, and comments for each Facebook post
🎥 Access video transcripts and media assets
📅 Filter posts by time frame (custom date ranges)
⚡ Get 500 posts for free in less than 2 minutes
🔓 No limitations on requests or number of calls
💾 Export Facebook data in JSON, CSV, Excel, or HTML
🔗 Export via SDKs (Python & Node.js), use API Endpoints, webhooks, or integrate with apps & AI workflows
🔍 Explore 20+ other Facebook scraping tools
What Facebook posts data can I extract?
With this Facebook post API, you can download Facebook posts and extract comprehensive data from any public page or profile. Use this post scraper to analyze engagement patterns, track content performance, and monitor posting trends:
| 📝 Post text and caption | 🔗 Post URL and page/profile URL |
| 🕐 Timestamp and publish date | 👍 Number of likes, reactions, and shares |
| 💬 Comments count and top comments | 👥 Author name and profile ID |
| 🆔 Post ID and Facebook ID | 📊 Engagement metrics breakdown |
| 🖼 Media URLs and thumbnails | 🎥 Video URLs and transcripts |
| 🔗 External links in posts | 📱 Page or profile details |
| 🔢 Reaction breakdowns (like, love, haha, etc.) | 📢 Number of Facebook shares per post |
| 📣 Whether the page runs ads | 🆔 Page ID in Meta Ads Library |
| 🔄 Whether post is shared from another page | 🎬 Whether the post is a video |
How do I use Facebook Posts Scraper?
Facebook Posts Scraper was designed to be easy to start with even if you've never extracted data from the web before. Here's how you can use this Facebook post extractor to crawl Facebook posts:
- Create a free Apify account using your email.
- Open Facebook Posts Scraper.
- Add one or more Facebook page/profile URLs to scrape posts from.
- Choose optional filters: time frame (custom date range), include video transcripts, or number of posts to scrape.
- Click "Start" and wait for the data to be extracted.
- Download your data in JSON, XML, CSV, Excel, or HTML.
For a step-by-step guide on scraping Facebook posts, follow our Facebook Posts Scraper tutorial 📝.
➡️ Input
The input for Facebook Posts Scraper should be Facebook page or profile URLs such as https://www.facebook.com/pagename/. You can insert the URLs one by one, paste a prepared list, or set the input via API. You can also set optional filters like time frame (custom date range) to download Facebook posts from specific periods, enable video transcripts, or limit the number of posts.
Click on the input tab for a full explanation of an input example in JSON.
⬅️ Output
The results will be wrapped into a dataset which you can find in the Output tab. Here's an excerpt from the dataset you'd get when scraping Facebook posts:
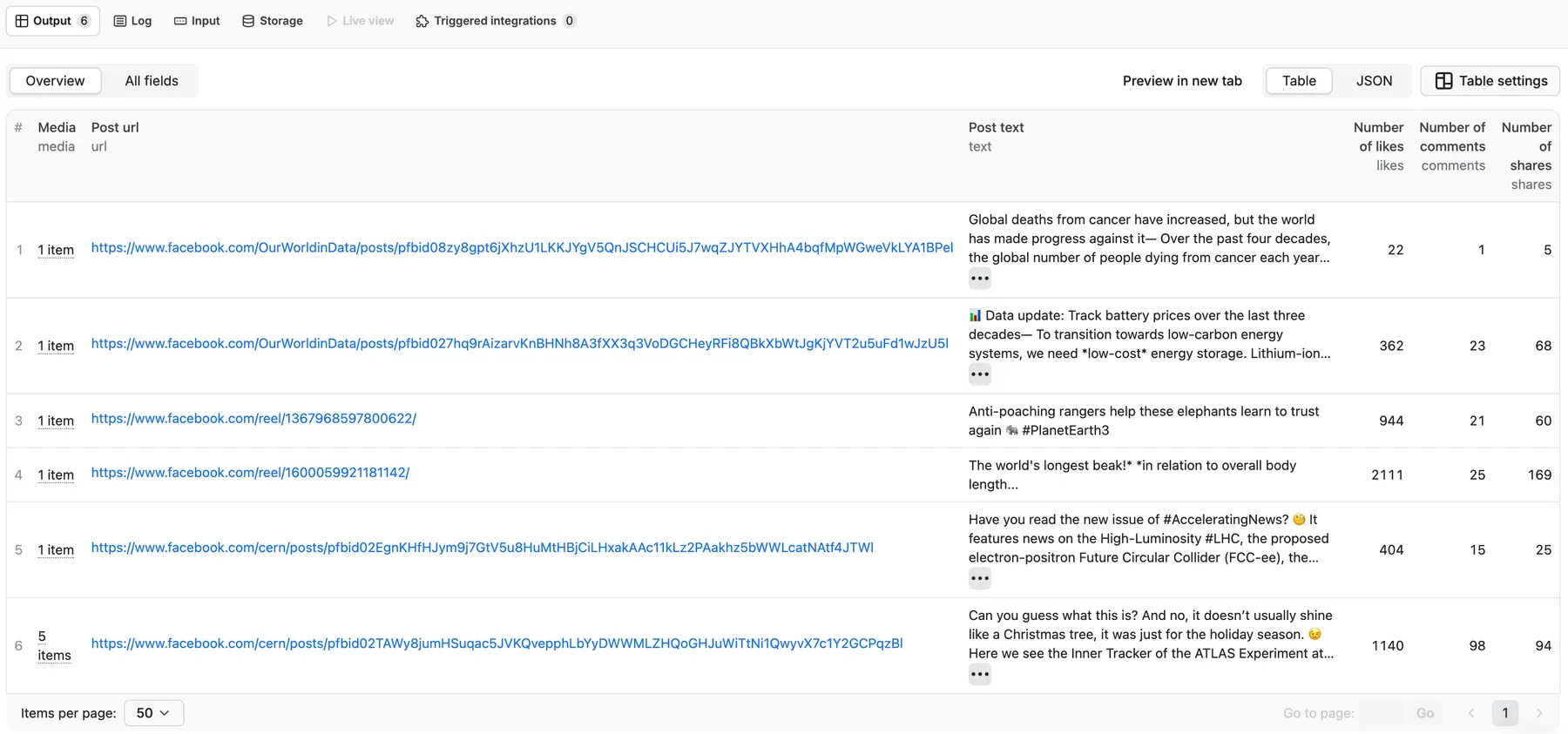
📘 Example of extracted Facebook post data
You can choose in which format to download your Facebook data: JSON, JSONL, Excel spreadsheet, HTML table, CSV, or XML. Here's what a typical post output looks like:
How much will scraping Facebook posts cost you?
Scraping data from Facebook posts costs approximately $5-8 for every 1,000 posts, or $0.005-0.008 per post. If you're on Apify Free plan, you will be able to scrape up to 500 posts before needing to upgrade.
For more frequent or extensive Facebook data scraping, consider upgrading to the $29/month Starter plan, which can get you up to 3,600-5,800 Facebook posts per month. For scalable scraping of Facebook posts, check out $199/month Scale or $999/month Business plan.
What is the best Facebook scraper?
You can use the dedicated scrapers below if you want to scrape specific Facebook data. Each of them is built particularly for the relevant Facebook scraping case be it groups, reviews, comments or search. If you need to scrape posts from Instagram instead, check out our Instagram Post Scraper.
❓ FAQ
Can I export Facebook Posts data using API?
Yes, you can access the extracted Facebook data through the Apify API. You'll need an Apify account and your API token (available under Integrations settings in Console). Apify API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify actors. The API also lets you access any datasets, monitor actor performance, fetch results, create and update versions, and more. To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package.
Click on the API tab for code examples or check out the Apify API reference docs for full detail.
Can I use Facebook Posts Scraper through an MCP server?
With Apify API, you can use Facebook Posts Scraper within your AI workflows. You can connect to the MCP server using clients like ClaudeDesktop and LibreChat or build your own. Here's how you can set up Facebook Posts Scraper via Model Context Protocol (MCP) server:
- Start a Server-Sent Events (SSE) session to receive a
sessionId. - Send API messages using that
sessionIdto trigger the scraper. - The message starts the Facebook Posts Scraper with the provided input.
- The response should be:
Accepted.
This makes Facebook Posts Scraper compatible with Facebook MCP server implementations and allows you to use it as a Facebook post extractor within your AI agent workflows.
Is there a difference between scraping a Facebook profile and Facebook page?
Yes, there is. Facebook Pages are created for businesses, companies, non-profits, and other social causes. Those are the Facebook accounts that strive to provide "public-first" content and are often managed by a group of people. An easy way to distinguish between a Facebook profile and a Facebook page is that pages usually have a category of content and activity they would like to be associated with (news, software, hospitality, etc.) Facebook Pages that are particularly popular often include a blue verification badge. Facebook profiles are created for personal use.
This scraper can extract information from both Facebook pages and Facebook profiles.
Do I need proxies to scrape data from Facebook posts?
You need proxies in general but you don't need to do anything extra to apply them if you run the scraper on the Apify platform. For successful scraping of Facebook posts, we run residential proxies in the background which are included in Apify's monthly Starter plan ($29).
Can I integrate data from Facebook Posts Scraper with other apps?
Yes. Facebook Posts Scraper can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate with Make, Zapier, ChatGPT, Slack, Airbyte, GitHub, Google Sheets, Asana, Google Drive, Keboola, MCP Servers, and more.
Is it legal to scrape Facebook Posts data?
Our Facebook scrapers are ethical and do not extract any private user data. They only extract what the user has chosen to share publicly. However, you should be aware that your results could contain personal data. You should not scrape personal data unless you have a legitimate reason to do so.
If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping and ethical scraping.
Facebook Posts Scraper is not working?
We're always working on improving the performance of our Actors. So if you've got any technical feedback for Facebook Posts Scraper or simply found a bug, please create an issue on the Actor's Issues tab.