Facebook Comments Scraper
Pricing
from $1.40 / 1,000 comments
Facebook Comments Scraper
Extract data from hundreds of Facebook comments from one or multiple Facebook posts. Get comment text, timestamp, likes count and basic commenter info. Download the data in JSON, CSV, Excel and use it in apps, spreadsheets, and reports.
Pricing
from $1.40 / 1,000 comments
Rating
4.7
(76)
Developer
Apify
Maintained by ApifyActor stats
381
Bookmarked
34K
Total users
3K
Monthly active users
17 hours
Issues response
2 hours ago
Last modified
Categories
Share
What is Facebook Comments Scraper?
Facebook Comments Scraper is a simple but powerful tool that lets you extract comments from Facebook posts, videos, posts with images, and reels. Just paste in a post URL and click "Save & Start". Unlike the limited Facebook API, this scraper gives you access to publicly visible comments in bulk:
❖ Scrape thousands of Facebook comments from a post, photo, reel, and video
❖ Extract comment text, replies, likes count, timestamp, and more
❖ Extract basic public profile info of the comment author
❖ Presort comments based on sorting type (newest, most relevant, all), filter out comments based on timeframe
❖ Get 2,000 comments for free in less than 2 minutes
❖ No limitations on requests or number of calls
❖ Export to JSON, CSV, Excel, or HTML
❖ Export via SDKs (Python & Node.js), use API Endpoints, webhooks, or integrate with apps & AI workflows
❖ Combine with 20+ other Facebook scraping tools
What Facebook comments data can I extract?
With this Facebook API, you will be able to extract the following data from Facebook posts:
| 📝 Post title | 🔗 Post URL |
| 💬 Comment text and URL | ⌨️ Replies count |
| 🧛 Commenter name and profile ID | 🖼 Profile picture |
| 🕐 Timestamp | 👍 Likes count |
| 🙋 Replier's name | 🧵 Threading depth |
| 🆔 Post, Comment, Facebook ID | 🛍️ Ad Library activity status |
How do I use Facebook Comments Scraper?
Facebook Comments Scraper was built to work even if you’ve never scraped data before. Here’s how to get started:
- Create a free Apify account.
- Open Facebook Comments Scraper.
- Paste in one or more Facebook post URLs.
- Choose the number of comments and replies to scrape.
- Choose the way the comments are sorted (most relevant, newest, or non-filtered)
- Click "Start" to begin the scrape.
- Download your results as JSON, CSV, Excel, HTML, or use the API.
If you want a walkthrough, check out our step-by-step tutorial 🔗.
⬇️ Input
The input for Facebook Comments Scraper should be Facebook post URLs (reels, videos, posts with images, or regular posts). Paste them manually, import a list, or set up your own input via API.
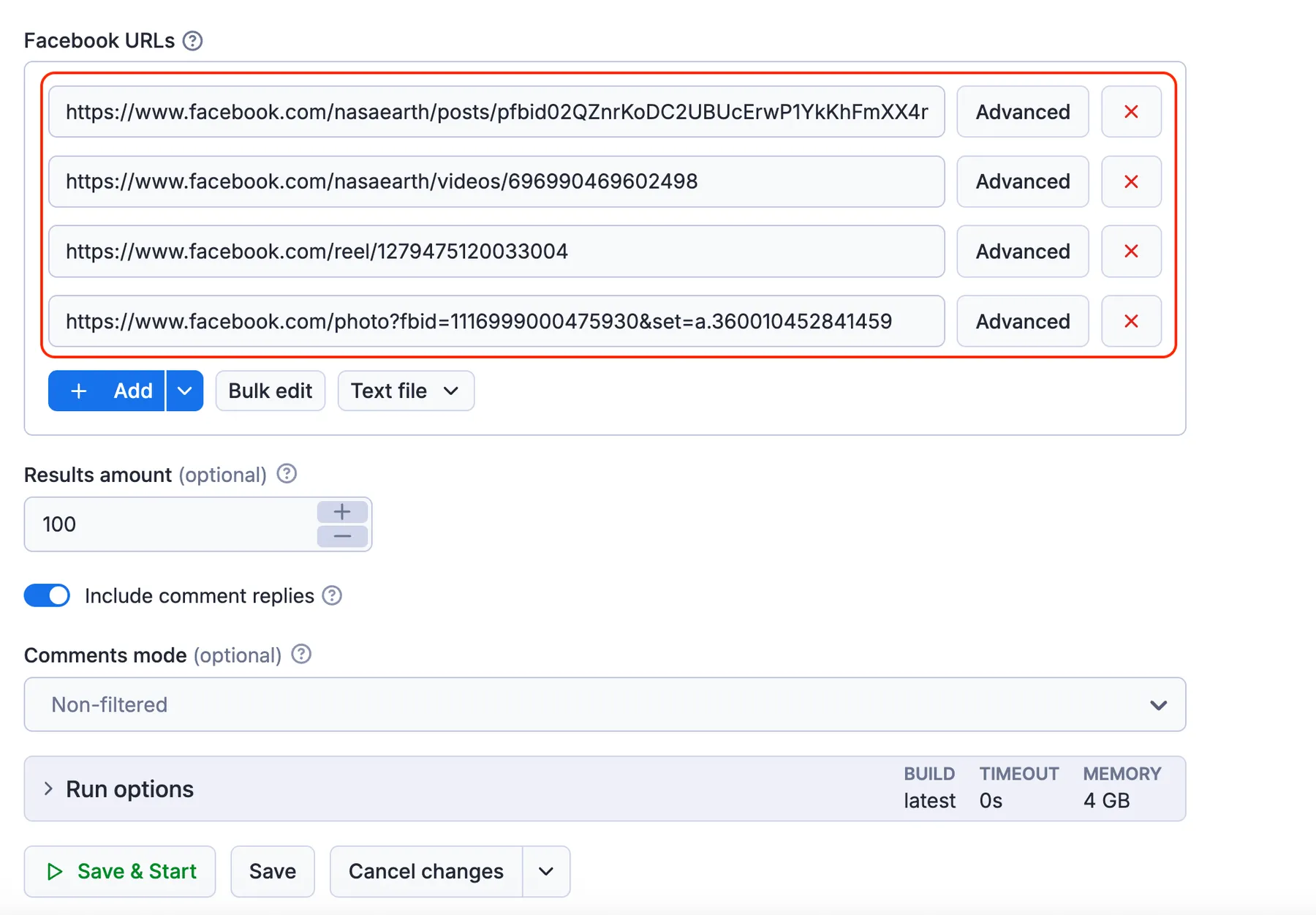
Click on the input tab for a full explanation of an input example in JSON.
⬆️ Output
The results will be wrapped into a dataset which you can find in the Storage tab. Here's an excerpt from the dataset you'd get if you apply the input parameters above:
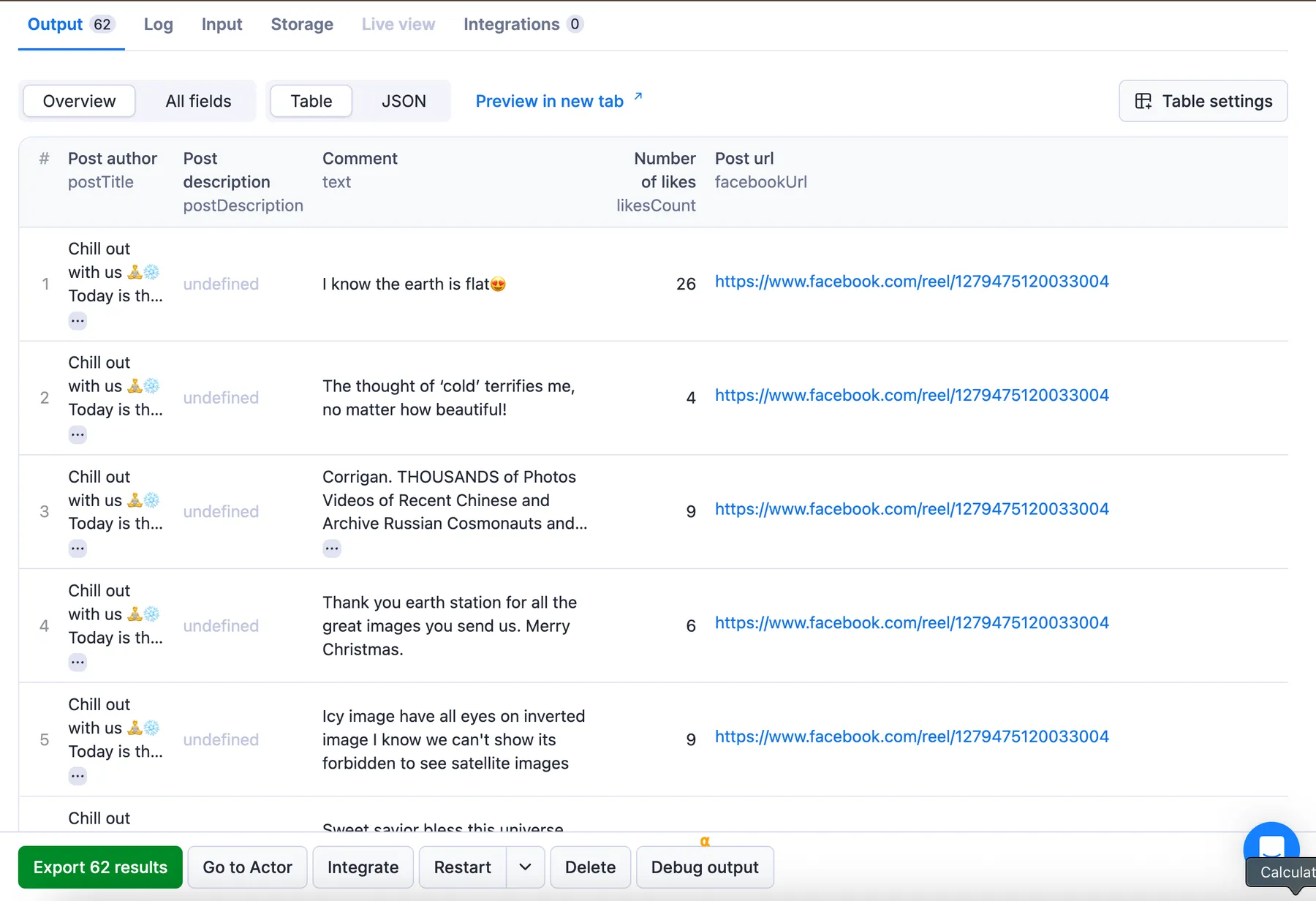
💬 Extracted Facebook comments & replies sample
You can export this data in JSON, JSONL, CSV, XML, Excel, or HTML.
How many comments can it scrape?
You can expect to scrape 2,000–3,000 comments per post, depending on the structure and visibility of the post. However, results vary due to:
- Post type (e.g. public post vs. private post)
- Facebook’s dynamic comment loading
- Pagination structure
- Geographic or login-based restrictions
The best way to know how much data you'll get is to run a test scrape with your actual input. More details on maximizing your scraping results in the ❓ FAQ section.
What is the best Facebook scraper?
Need to scrape more than comments? These tools are built for different scraping needs across Facebook:
❓ FAQ
Can I filter Facebook comments by date?
Yes. Use onlyCommentsNewerThan section to extract only comments newer than a selected date/time.
Supported formats:
YYYY-MM-DD- Full or partial ISO absolute timestamp (UTC)
- Relative values such as
1 day,2 months,3 years,1 hour, or2 minutes
When onlyCommentsNewerThan is set, the scraper uses newest-first sorting (RECENT_ACTIVITY) so the filter works correctly.
Why do I see fewer comments than is seen on the Facebook post itself?
You might see fewer comments than what’s shown on the Facebook post itself because the Actor only gets public comments. If someone has privacy settings that hide their comments from the public, those won’t be scraped. Also, Facebook’s comment counter includes both top-level comments and all replies. So, especially on larger threads, it’s normal that the number of comments scraped is lower than the number shown by Facebook.
Why am I getting way more results than I had set in Results amount?
The Results amount limit covers both comments and their replies. The Actor can return up to 3 levels — comments, replies, and nested replies — so the total number of items can be higher than what you set.
How can I get the most comments possible using the Facebook Comments Scraper?
To maximize the number of comments scraped, make sure to enable replies (nested comments) and set sorting to "newest". Facebook’s total comment count includes public, private comments and replies, but the scraper can only access public ones. So if you’re seeing fewer results than the total shown, it’s likely due to private content you can’t scrape — not a bug or blocking issue.
Can the scraper get both public and private comments from Facebook, and what's the difference?
Yep, there is a difference! Public comments are visible to everyone and can be scraped. But if someone with a private profile leaves a comment, it might only be visible to their friends or followers—and not to the scraper. So if a post has 200 comments but the scraper only grabs 100, it’s likely the rest are from private accounts and can’t be accessed. We just assume those are private ones hiding in the shadows.
Can I use Facebook Comments Scraper through an MCP Server?
With Apify API, you can use 💬 Facebook Comments Scraper within your AI workflows. You can connect to the MCP Server using clients like ClaudeDesktop and LibreChat or build your own. Here's you can set up Facebook Scraper via Model Context Protocol (MCP) server, you should:
- Start a Server-Sent Events (SSE) session to receive a
sessionId. - Send API messages using that
sessionIdto trigger the scraper. - The message starts the 💬 Facebook Comments Scraper with the provided input.
- The response should be:
Accepted.
Can I integrate Facebook comments data with other apps?
Yes, Facebook Comments Scraper can be integrated with most tools and services via the Apify platform:
- Zapier, Make, Slack, Airbyte, Google Sheets, Asana, GitHub, Keboola, and more
- MCP for your AI agents and workflows
- Webhooks to trigger actions on scrape completion
- Apify API for full automation
Is there a simpler way to get Facebook comments directly on Make?
We have a dedicated make.com/en/integrations/apify-facebook-scraper with a Facebook Comments module, so you don’t need to set up the full Apify integration. It has a regular input schema and a few templates to start from. All you need to set it up is to add your Apify API token.
Can I export Facebook comments data using API?
Yes, you can access the extracted Facebook data through the Apify API. You’ll need an Apify account and your API token (available under Integrations settings in Console). Use your Apify API token to:
- Schedule runs
- Trigger scrapes on demand
- Access datasets
- Monitor runs and logs
You can access the API from Console or use apify-client for Python or Node.js. Click the API tab for code snippets.
Do I need proxies to scrape data from Facebook comments?
Yes, Facebook requires proxies for stable scraping. The scraper runs on Apify Proxy with residential IPs automatically when used on the platform. You don’t need to configure anything. Residential proxies are included with the Starter plan or higher.
Is it legal to scrape Facebook comments and replies?
Yes, as long as the data is public. Facebook Comments Scraper — and Apify's Facebook scrapers in general — only extract publicly available comments. They don’t access private data like DMs or closed groups.
That said, scraped content may still contain personal data. If you plan to store, process, or reshare that data, make sure you have a legitimate legal basis. Read our take on legal web scraping and ethical scraping.
Facebook Comments Scraper not working
Got a feature request, question, or bug to report? Drop us a note on the Issues tab — someone from the Apify team will address it shortly.