Facebook Likes and Reactions Scraper
Pricing
from $2.60 / 1,000 results
Facebook Likes and Reactions Scraper
Extract Facebook likes data from one or multiple Facebook posts. Get post URL, reaction type (like, love, care, sad, angry, laugh), and basic liker info such as Facebook name and profile URL. Download the data in JSON, CSV Excel and use it in apps, spreadsheets, and reports.
Pricing
from $2.60 / 1,000 results
Rating
3.9
(16)
Developer
Apify
Maintained by ApifyActor stats
47
Bookmarked
7.5K
Total users
110
Monthly active users
3.3 days
Issues response
a day ago
Last modified
Categories
Share
What is Facebook Likes Scraper?
It's a simple and powerful tool that allows you to extract data about reactions to Facebook posts. To get that data, just insert the post URL and click "Save & Start" button.
What Facebook likes data can I extract?
With this Facebook API, you will be able to extract the following likes data from Facebook:
| 🔗 Post URL | 😢 Reaction type (like, love, care, angry, sad, laugh) |
| 🖼 Liker Profile URL | 💂♀️ Basic liker info |
| 👍 Facebook ID | ✍️ Post ID |
Why scrape Facebook likes?
🤬 Analyze social media and identify hot spots of misinformation or hate speech
🔎 Conduct market research or product analysis
🤺 Monitor competition
🤔 Track brand sentiment and shifts in customer engagement
How do I use Facebook Likes Scraper?
Facebook Likes Scraper was designed to be easy to start with even if you've never extracted data from the web before. Here's how you can scrape Facebook data with this tool:
- Create a free Apify account using your email.
- Open Facebook Likes Scraper.
- Add one or more Facebook post URLs to scrape its likes and other reactions.
- Click "Start" and wait for the data to be extracted.
- Download your data in JSON, XML, CSV, Excel, or HTML.
Input
The input for Facebook Likes Scraper should be URLs of Facebook posts you want to scrape reactions from. Click on the input tab for a full explanation of input in JSON.
Output sample
The results will be wrapped into a dataset which you can find in the Storage tab. Here's an excerpt from the dataset you'd get if you apply the input parameters above:
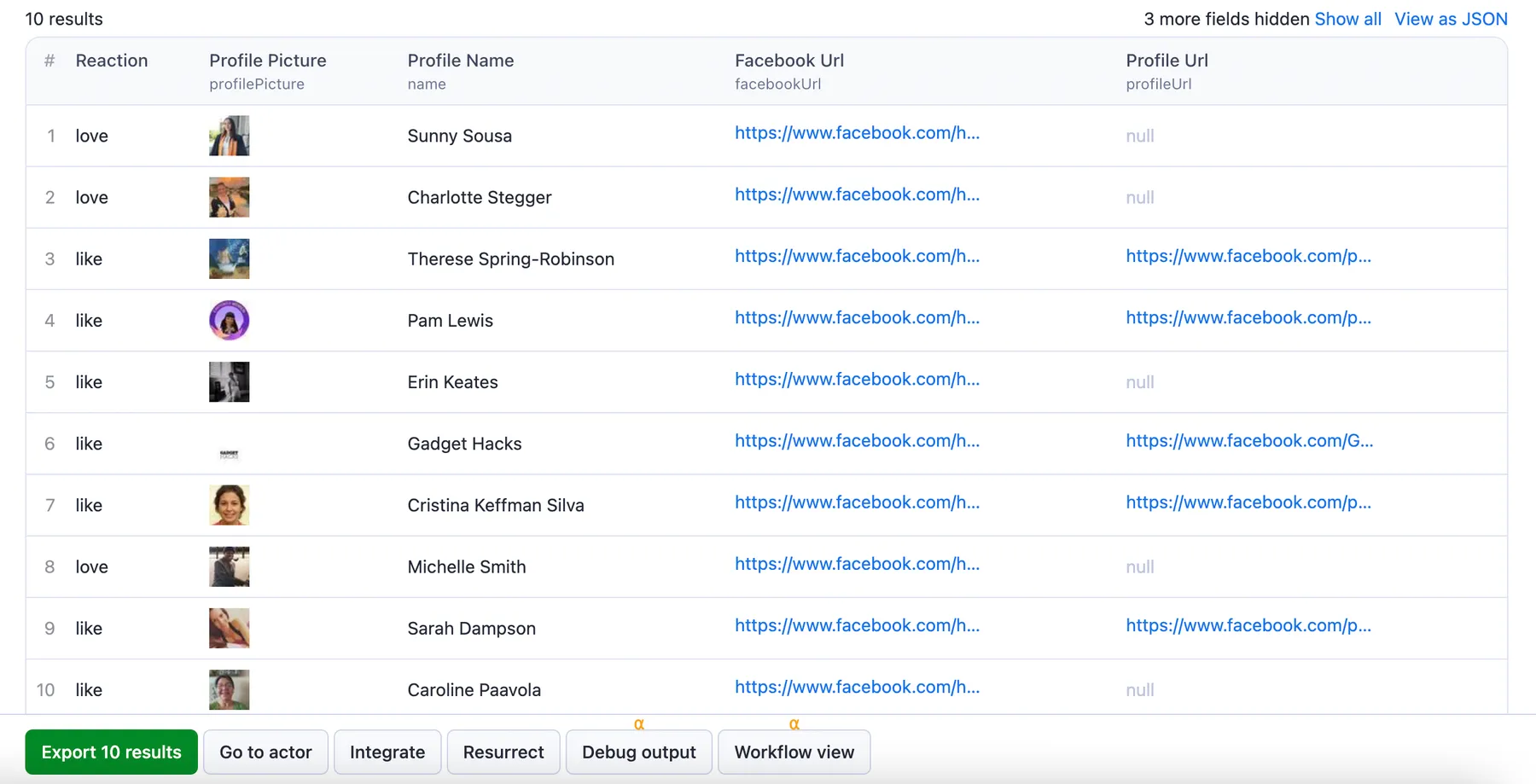
And here is the same data but in JSON. You can choose in which format to download your Facebook data: JSON/JSONL, Excel, HTML table, CSV, or XML.
How many results can you scrape with Facebook Likes scraper?
Facebook Likes scraper can currently return 20 results on average - the preview of likes (reactions) you see per every post. However, you have to keep in mind that scraping facebook.com has many variables to it and may cause the results to fluctuate case by case. There’s no one-size-fits-all-use-cases number. The maximum number of results may vary depending on the complexity of the input, location, and other factors. Some of the most frequent cases are:
- website gives a different number of results depending on the type/value of the input
- website has an internal limit that no scraper can cross
- scraper has a limit that we are working on improving
Therefore, while we regularly run Actor tests to keep the benchmarks in check, the results may also fluctuate without our knowing. The best way to know for sure for your particular use case is to do a test run yourself.
How much will scraping Facebook Likes cost you?
When it comes to scraping, it can be challenging to estimate the resources needed to extract data as use cases may vary significantly. That's why the best course of action is to run a test scrape with a small sample of input data and limited output. You’ll get your price per scrape, which you’ll then multiply by the number of scrapes you intend to do.
Watch this video for a few helpful tips. And don't forget that choosing a higher plan will save you money in the long run.
Want to scrape Facebook Pages or comments?
You can use the dedicated scrapers below if you want to scrape specific Facebook data. Each of them is built particularly for the relevant Facebook scraping case be it group posts, reviews, events, or images. Feel free to browse them:
Integrations and Facebook Likes Scraper
Last but not least, Facebook Likes Scraper can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate with LangChain, Make, Trello, Zapier, Slack, Airbyte, GitHub, Google Sheets, Google Drive, Asana, and more.
You can also use webhooks to carry out an action whenever an event occurs, e.g., get a notification whenever Facebook Likes Scraper successfully finishes a run.
Using Facebook Likes Scraper with the Apify API
The Apify API gives you programmatic access to the Apify platform. The API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify actors. The API also lets you access any datasets, monitor actor performance, fetch results, create and update versions, and more. To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package.
Check out the Apify API reference docs for full details or click on the API tab for code examples.
Is it legal to scrape Facebook Likes data?
Our Facebook scrapers are ethical and do not extract any private user data, such as email addresses, gender, or location. They only extract what the user has chosen to share publicly. However, you should be aware that your results could contain personal data. You should not scrape personal data unless you have a legitimate reason to do so.
If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping and ethical scraping.
Your feedback
We’re always working on improving the performance of our Actors. So if you’ve got any technical feedback for Facebook Likes Scraper or simply found a bug, please create an issue on the Actor’s Issues tab in Apify Console.