Twitter X-Plorer 🦜
Pricing
$30.00/month + usage
Pricing
$30.00/month + usage
Rating
0.0
(0)
Developer
cat
Maintained by CommunityActor stats
11
Bookmarked
758
Total users
5
Monthly active users
8 months ago
Last modified
Categories
Share
💫 Welcome to Twitter X-Plorer

🦜 About Twitter.com

Twitter is an online social media and social networking service owned and operated by American company X Corp., the legal successor of Twitter, Inc. Twitter users outside the United States are legally served by the Ireland-based Twitter International Unlimited Company, which makes these users subject to Irish and European Union data protection laws[9][10]
🦜 About This Actor
💫 All-In-One Twitter Data Extractor
- ⭐Scrape User timeline, followers, following, media, likes, lists, topics, highlights, etc.
- ⭐Scrape List timeline, members, followers
- ⭐Scrape Specific Topic
- ⭐Scrape Status & Threads
- ⭐Scrape Media: Photo / Video / Gif, etc.
- ⭐Advanced Search
- ⭐Content Formatting: HTML or Plain TEXT
- ⭐Low Memory Cost
- ⭐A.S.A.P
DISCLAIMER:
- This Twitter scraper only collects data that’s publicly available. This means data that’s accessible without logging in to Twitter and without accepting Twitter’s terms of use. Please note that if you accepted Twitter’s terms of use, your ability to scrape Twitter data may be limited. If that is the case, please review the terms and make an informed decision yourself.
- By providing your personal auth_token, you agree to obey twitter TOS, especially regarding rate-limit policy 50 request per 15 minutes enforced by elonmusk
🦜 Tutorial
👉 Parameters
| Parameter | Type | Options | Description |
|---|---|---|---|
query | string | List of Query, Keywords or URL | |
filters | object | Advanced search filters | |
limit | integer | numeric | Number of results (per-query) |
content | string | text, html | Format of results content |
auth_token | string | cookie | Value of auth_token cookie |
💫 NOTES :
If a multiline Query is provided (Queries separated by line breaks), each line will be processed separately.
Example :
👉 Basic Usage
Scrape user profiles
Scrape user posts
Advanced Search (Cookies required)
Scrape an URL
👉 Advanced Usage
Twitter Query Language (TQL)
❓ QUERIES Overview
| Format | Examples | Description |
|---|---|---|
| <KEYWORD> | web scraping | Search Anything |
| jobs:<KEYWORD> | jobs:python engineer | Search Jobs |
| #<HASHTAG> | #AI | Search Hashtag |
@<USER> /info /about /replies /media /articles /likes /affiliates /followers /following /lists /topics /highlights /subscriptions /jobs | @elonmusk@elonmusk/info @elonmusk/about @elonmusk/replies @elonmusk/followers | Scrape User Data |
<STATUS_ID> /info /quotes /reposts /likes | 1562015197543497728 | Scrape Posting (Tweet) |
| topic:<TOPIC_ID> | topic:1280550787207147521 | Scrape Topic |
list:<LIST_ID> /info /posts /members /followers | list:1334803406523953152list:1334803406523953152/posts list:1334803406523953152/members | Scrape List |
| comm:<COMM_ID> | Scrape Community | |
| https:<URL> | https://x.com/... | Start URL |
❓ Possible QUERY Values :
| Format | Example | Description |
|---|---|---|
| <KEYWORD> | web scraping | Search Anything |
| #<HASHTAG> | #AI | Search Hashtag |
| @<USER> | @elonmusk | Scrape User Data |
/info | @elonmusk/info | User info |
/about | @elonmusk/about | User about |
/replies | @elonmusk/replies | User replies |
/highlights | @elonmusk/highlights | |
/media | @elonmusk/media | |
/jobs | @elonmusk/jobs | Jobs opportunity |
/articles | @elonmusk/articles | |
/likes | @elonmusk/likes | |
/lists | @elonmusk/lists | |
/topics | @elonmusk/topics | |
/affiliates | @elonmusk/affiliates | |
/followers | @elonmusk/followers | |
/verified_followers | @elonmusk/verified_followers | |
/followers_you_know | @elonmusk/followers_you_know | |
/following | @elonmusk/following | |
/subscriptions | @elonmusk/subscriptions | |
| <STATUS_ID> | 1562015197543497728 | Scrape Posting (Tweet) |
/info | 1562015197543497728/info | Post content |
/replies | 1562015197543497728/replies | |
/quotes | 1562015197543497728/quotes | |
/reposts | 1562015197543497728/reposts | |
/likes | 1562015197543497728/likes | |
/analytics | 1562015197543497728/analytics | |
| topic:<TOPIC_ID> | topic:1280550787207147521 | Scrape Topic Timeline |
| list:<KEYWORD> | list:java script | Search List |
| list:<LIST_ID> | list:1334803406523953152 | List Data |
/info | list:1334803406523953152/info | List info |
/posts | list:1334803406523953152/posts | List posts |
/members | list:1334803406523953152/members | List members |
/followers | list:1334803406523953152/followers | List followers |
| com:<KEYWORD> | com:python | Search Community |
| com:<COM_ID> | com:1672458762852921344 | Community Data |
/info | com:1672458762852921344/info | Community info |
/top | com:1672458762852921344/top | Top posts |
/latest | com:1672458762852921344/latest | Latest posts |
/media | com:1672458762852921344/media | Media posts |
/members | com:1672458762852921344/members | Members list |
/moderators | com:1672458762852921344/moderators | Moderators list |
| job:<KEYWORD> | job:python engineer | Search Jobs |
| job:<JOB_ID> | job:1723106649395671391 | Job Data |
| https:<URL> | https://x.com/... | Start URL |
👉 TheAUTH_TOKEN parameter (auth_token cookie)
Some function require auth_token cookie to work properly (required sign-in to Twitter.com). When you receive log error something like below, then probably you need to supply parameters with auth_token value.
Important Notes :
- This is NOT your APIFY Token, instead a value from your browser cookie, named auth_token.
- Use this only if necessary, as it have risk your account getting blocked by @elonmusk.
- Your cookies is your SECRET. Please don't share it with someone else.
- The auth_token value will always valid until you logged out from Twitter.com
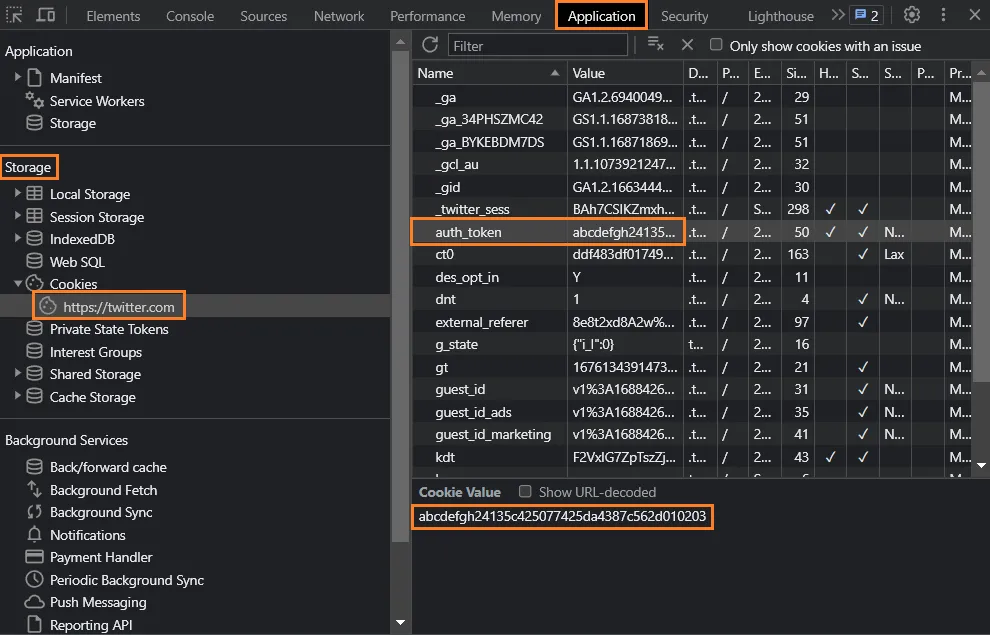
To get auth_token cookie value :
- Login to Twitter.com
- Open Chrome Developer Tools
(Ctrl + Shift + I) - Open Application Tab
- On left panel, go to:
Storage -> Cookies -> https://twitter.com - Find cookie named auth_token
(40 characters string value). - Copy & Paste Here :
🦜 Input Examples
👉 Example #1 : Searching
Search for Posts by Keyword
Search for Posts by #Hashtag
👉 Example #2 : User Info
User profile @USERNAME
User media @USERNAME/media
User following Lists: @USERNAME/lists
👉 Example #3 : Topic
Topic latest Posts : topic/<TOPIC_ID>
List lates Posts :list/<LIST_ID>
👉 Example #4 : Advanced Searchfilters
👉 Example #5 : Content Formatting
In case you want content format in HTML use content parameter :
🦜 Advanced Search Filters
| Parameter | Type | Example | Summary | Description |
|---|---|---|---|---|
filters.raw | string | Animals +cat -dog lang:en | Searching raw query | |
filters.type | string | One of: latest, top, photos, videos, people | Post type | |
filters.word | string | what’s happening | both “what’s” and “happening” | All of these words |
filters.phrase | string | happy hour | the exact phrase “happy hour” | This exact phrase |
filters.any | string | cats dogs | either “cats” or “dogs” (or both) | Any of these words |
filters.exclude | string | cats dogs | does not contain “cats” and does not contain “dogs” | None of these words |
filters.hashtag | string | #ThrowbackThursday | the hashtag #ThrowbackThursday | These hashtags |
filters.from | string | @Twitter | sent from @Twitter | From these accounts |
filters.to | string | @Twitter | sent in reply to @Twitter | To these accounts |
filters.mention | string | @SFBART @Caltrain | mentions @SFBART or mentions @Caltrain | Mentioning these accounts |
filters.replies | integer | 250 | Minimum replies | |
filters.faves | integer | 200 | Minimum likes | |
filters.retweets | integer | 100 | Minimum retweets | |
filters.since | date | 2022-01-20 | Since date YYYY-MM-DD | |
filters.until | date | 2022-02-30 | Until date YYYY-MM-DD |
🦜 Did You Know ?
Twitter internally detect faces on images.

🦜 To-Do List
- Constructing status URL:
https://twitter.com/_/status/<status_id>orhttps://twitter.com/<screen-name>/status/<status-id> - Resize and format images URL:
https://pbs.twimg.com/media/xxxxxxxxxx.jpg?format=[jpg|png|webp]&name=[orig|normal|large|medium|thumb]
🦜 Support
⚡️ Feel free to reach out to the developer for any issues or suggestions for improvement.
