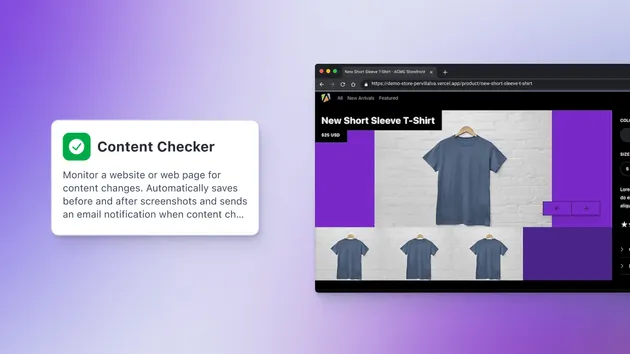
Website Checker Runner Cheerio
Pricing
Pay per usage
Go to Apify Store

Website Checker Runner Cheerio
Checks the provided website using cheerio. This is a low level runner, most likely you want to use the high level master actor - https://apify.com/lukaskrivka/website-checker
Pricing
Pay per usage
Rating
0.0
(0)
Developer
Lukáš Křivka
Maintained by Community
Actor stats
15
Bookmarked
322
Total users
1
Monthly active users
8 months ago
Last modified
Categories
Share