Yandex Maps Places Scraper
Pricing
from $2.00 / 1,000 results
Yandex Maps Places Scraper
Extract structured data from thousands of Yandex Maps locations and businesses, including phone numbers, emails, websites, reviews, images, addresses, coordinates, ratings, categories, opening hours & more.
Pricing
from $2.00 / 1,000 results
Rating
5.0
(10)
Developer
Mikhail Mamaev
Maintained by CommunityActor stats
21
Bookmarked
983
Total users
87
Monthly active users
2 months ago
Last modified
Categories
Share
This actor extracts structured business data from Yandex Maps, including reviews, contacts, addresses, coordinates, ratings, categories, opening hours, photos, menu data, websites, and identifiers. Collect rich data without an API key.
💡 Examples
- "coffee near Nevsky Prospect, Saint Petersburg"
- "dentist in Astana"
- "hotels in Istanbul Taksim"
- "строительные магазины, Екатеринбург"
Tip: Specify only one location per run.
🧾 Inputs
query: what you would type into Yandex Maps, with or without city/area.locations: City or district to search. Select from the list or enter your own option.maxItems: Number of places to extract (per each search term).language:english,russian,kazakh,turkish,azerbaijani.Filters, categories: Rating, Price categories, Good place, Categories.maxPhotos: Number of images to extract intophotos.maxReviews: Number of reviews to extract.includeMenu: Collect full menu data.organizationIds: Optional list of Yandex business/organization IDs or URLs
📦 What data does Yandex Maps Places Scraper extract?
| Category | What you get |
|---|---|
| IDs & links | placeId, geoId, url, query |
| Contact & location | address, fullAddress, addressComponents, state, country, phone, phones, website, businessLinks, location {lat,lng} |
| Ratings & hours | totalScore, ratingCount, reviewsCount, statusText, isOpenNow, workingHoursText, workingHours, visitsHistogram |
| Categories & extras | categories, features, socialLinks, sources |
| Transport & media | metroDetails, stopDetails, logoUrl, photos (images controlled by maxPhotos), photoDetails, photosCount, panoramaPreviewUrl, videoCount, videos |
| Menu | menu, menuTop, menuCategories, menuItemCount when full menu is available |
| Reviews (optional) | neuroCrop, neurosummary, reviews, reviewTags, reviewAspects |
Output example:
Adding images:
Adding reviews
📤 Output
The results will be wrapped into a dataset which you can find in the Output or Storage tab. Note that the output is organized in tables and tabs for viewing convenience. You can view results as a table, JSON, or as a map.
Once the run is finished, you can also download the dataset in various data formats (JSON, CSV, Excel, XML, HTML). Before exporting, you can pick or omit specific output fields; alternatively, you can also choose to download the whole view, which includes thematically connected data.
📊 Table view
The table view can be manipulated in different ways. There is a general overview
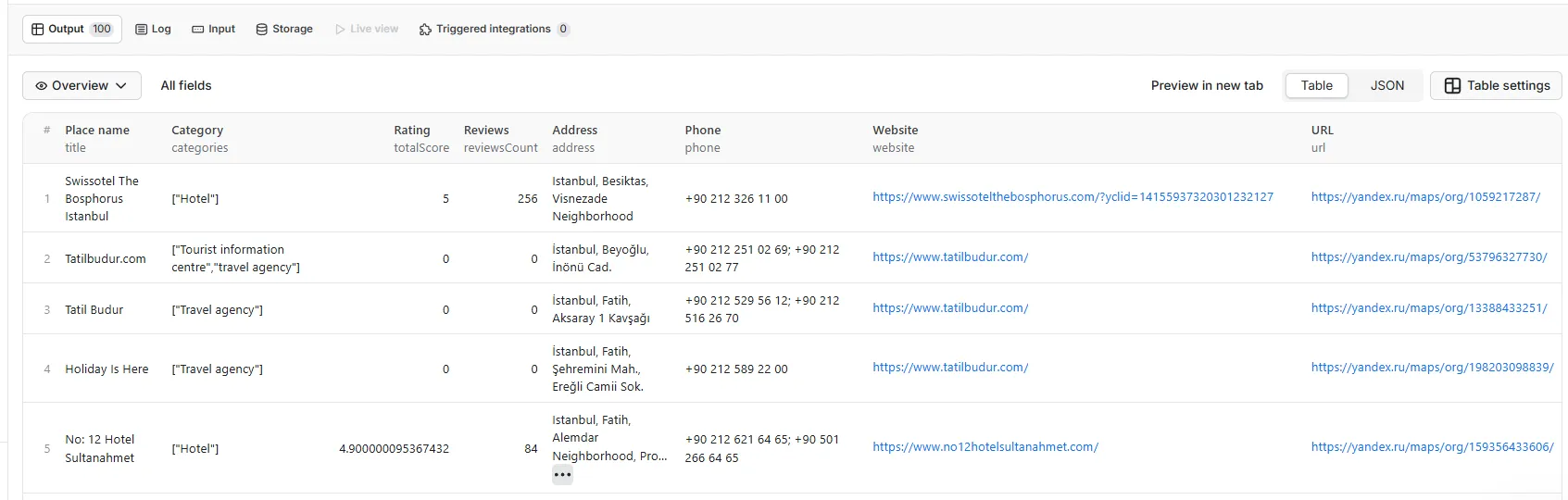
but you can also sort the table by contact info
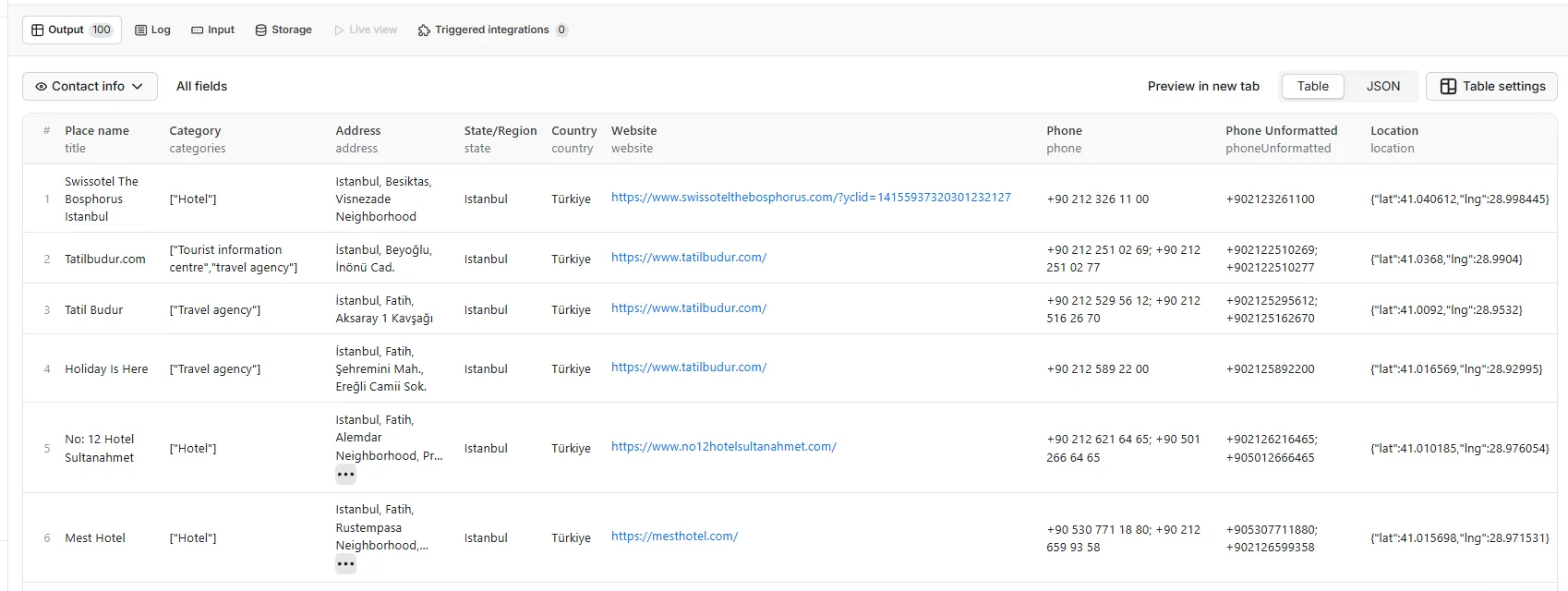
or Social media

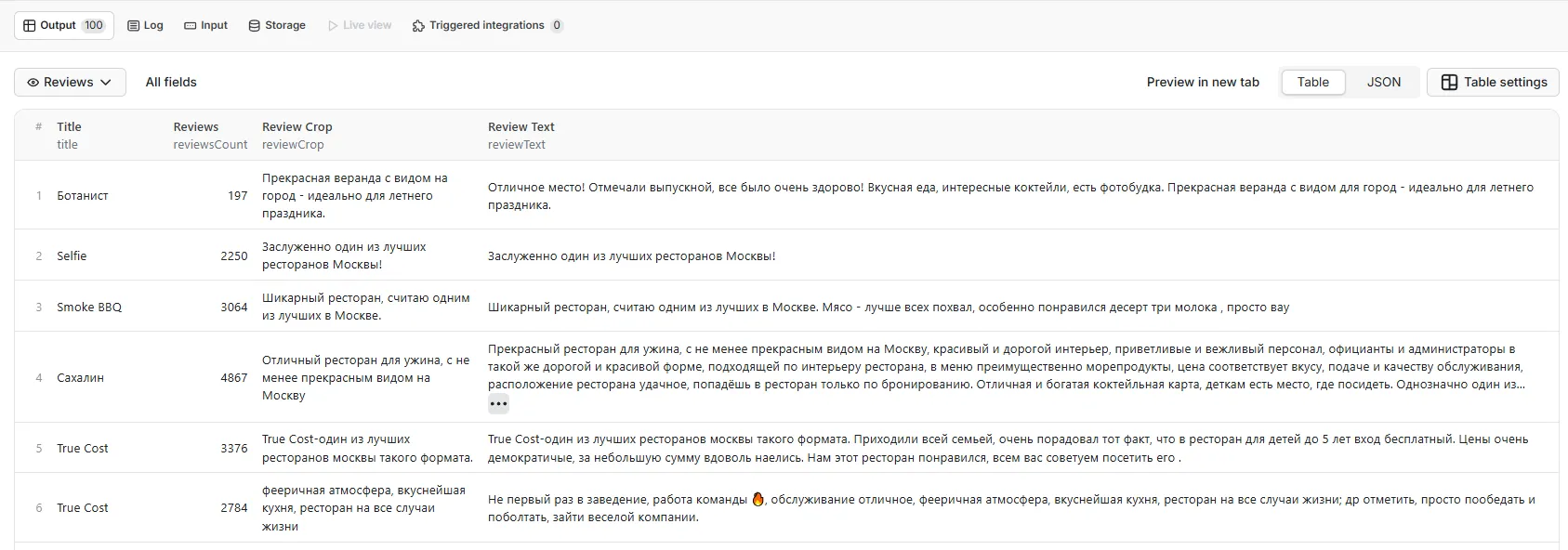
The "Review" table also contains a short and full overview from Alice AI based on user feedback.
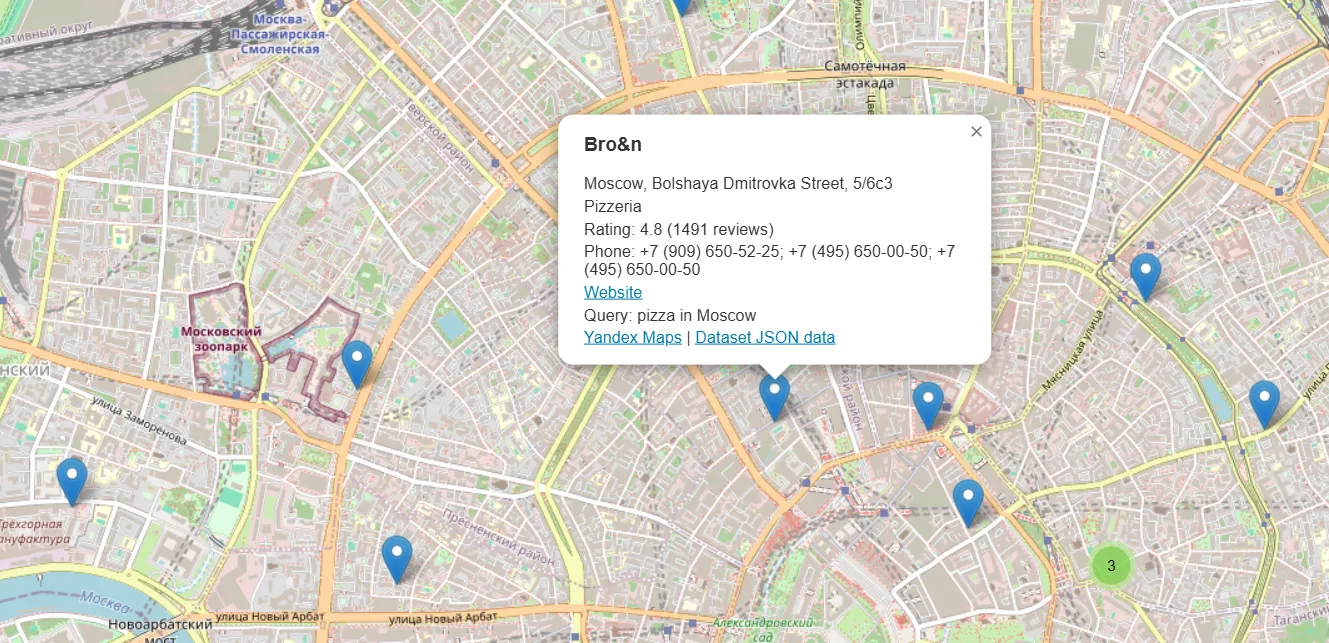
🗺 Map view
After scraping, the actor generates an interactive HTML map showing all collected places.
The map is saved to the Key-Value Store as:
results-map.html
| Also useful • Tools for adjacent workflows | |
|
Apify Actor A good alternative if your workflow is centered around 2GIS. |
Chrome Extension Browser-based scraping with real-time manual control. |