Product Hunt [Only $0.80💰] Scraper ·Launches, Reviews & Emails
Pricing
from $0.80 / 1,000 results
Product Hunt [Only $0.80💰] Scraper ·Launches, Reviews & Emails
[Only $0.80💰] Product Hunt scraper — leaderboards (daily–yearly), topics, collections, products & makers, any URL auto-classified. 50+ fields plus optional detailed reviews, comments & contact emails harvested per site. Pure HTTP, JSON/CSV.
Pricing
from $0.80 / 1,000 results
Rating
0.0
(0)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
0
Bookmarked
53
Total users
17
Monthly active users
6 days ago
Last modified
Categories
Share
Product Hunt Scraper — Launches, Reviews, Comments & Contact Emails
Turn any Product Hunt URL into a clean, structured dataset. Start from daily/weekly/monthly/yearly leaderboards, topics, collections, individual products, or maker profiles — all auto-classified from one input.
Get 50+ fields per product including votes, rank, comments, and a media gallery — plus optional detailed reviews, discussion threads + comments, contact emails harvested from each product's own website, and makers + hunter via the Product Hunt API. Pure HTTP, no browser.
Why Use This Scraper?
- ✅ Every Product Hunt entry point in one input — paste leaderboards, topics, collections, products, and maker profiles together; each is auto-classified
- ✅ Rankings built in — vote counts, daily/weekly/monthly rank, comment counts, and the featured timestamp on every leaderboard-sourced row
- ✅ Optional detailed reviews — full review text, per-dimension ratings, and selected pros/cons per product
- ✅ Optional discussion threads + comments — launch discussions with author and comment counts (full comment bodies with a token)
- ✅ Contact emails harvested from each product's own website (mailto + plain-text, junk-filtered, deduped per site)
- ✅ Optional makers + hunter via your own free Product Hunt API token — data not available in the page HTML
- ✅ JSON or CSV output, ready for spreadsheets and CRMs
Overview
The Product Hunt Scraper is built for founders, marketers, VCs, and researchers who need Product Hunt data in a spreadsheet instead of a browser tab.
The output is primarily product-shaped rows. Even when you start from a leaderboard, topic, or collection URL, the resulting dataset is a stream of product rows (rowType: "product") — not separate leaderboard or collection rows. The exception is a direct maker profile URL (/@username), which emits a single maker row (rowType: "maker").
The parser reads Product Hunt's server-rendered Apollo cache (the same data the page UI uses) rather than scraping rendered HTML, so it stays resilient to PH's frequent visual redesigns. URLs are auto-classified by shape — you just paste them, you don't tag them.
Supported Inputs
URL types
| URL type | Pattern | Example |
|---|---|---|
| Homepage | producthunt.com/ | https://www.producthunt.com/ |
| Daily leaderboard | /leaderboard/daily/YYYY/M/D | https://www.producthunt.com/leaderboard/daily/2026/5/22 |
| Weekly leaderboard | /leaderboard/weekly/YYYY/WW | https://www.producthunt.com/leaderboard/weekly/2026/20 |
| Monthly leaderboard | /leaderboard/monthly/YYYY/M | https://www.producthunt.com/leaderboard/monthly/2026/5 |
| Yearly leaderboard | /leaderboard/yearly/YYYY | https://www.producthunt.com/leaderboard/yearly/2025 |
| Topic page | /topics/{slug} | https://www.producthunt.com/topics/artificial-intelligence |
| Collection | /collections/{slug} | https://www.producthunt.com/collections/best-ai-tools |
| Collections index | /collections | https://www.producthunt.com/collections |
| Product detail | /products/{slug} or /posts/{slug} | https://www.producthunt.com/products/bolt-new |
| Maker profile | /@{username} | https://www.producthunt.com/@ericsimons40 |
Homepage and listing URLs (leaderboards, topics, collections) fan out to product rows and stop once maxItems is reached. The homepage walks recent daily leaderboards (newest first).
Copy-pasteable startUrls
startUrls accepts both plain strings ("https://…") and request objects ({ "url": "https://…" }) — mix freely.
Unsupported inputs
- ❌ Keyword search (
/search?q=…) — Product Hunt loads search results client-side after page load, so they aren't available to an HTML-based scraper - ❌ Content behind a Product Hunt login (private/draft launches, account settings)
- ❌ Hosts outside
producthunt.com
Use Cases
| Audience | Use case |
|---|---|
| Founders & indie makers | Track competitor launches, benchmark votes/rank, study winning taglines, reviews, and media |
| Marketing & growth teams | Build outreach lists from new launches with contact emails attached |
| VCs & scouts | Source deals from daily/weekly leaderboards; filter by funding, YC alumni, traction, review sentiment |
| Sales / lead-gen | Turn leaderboards + collections into a ready-to-import prospect list |
| Researchers & analysts | Bulk-export launches, reviews, and discussions across topics and time periods |
| Agencies | Deliver client-ready Product Hunt datasets without writing a scraper |
How It Works
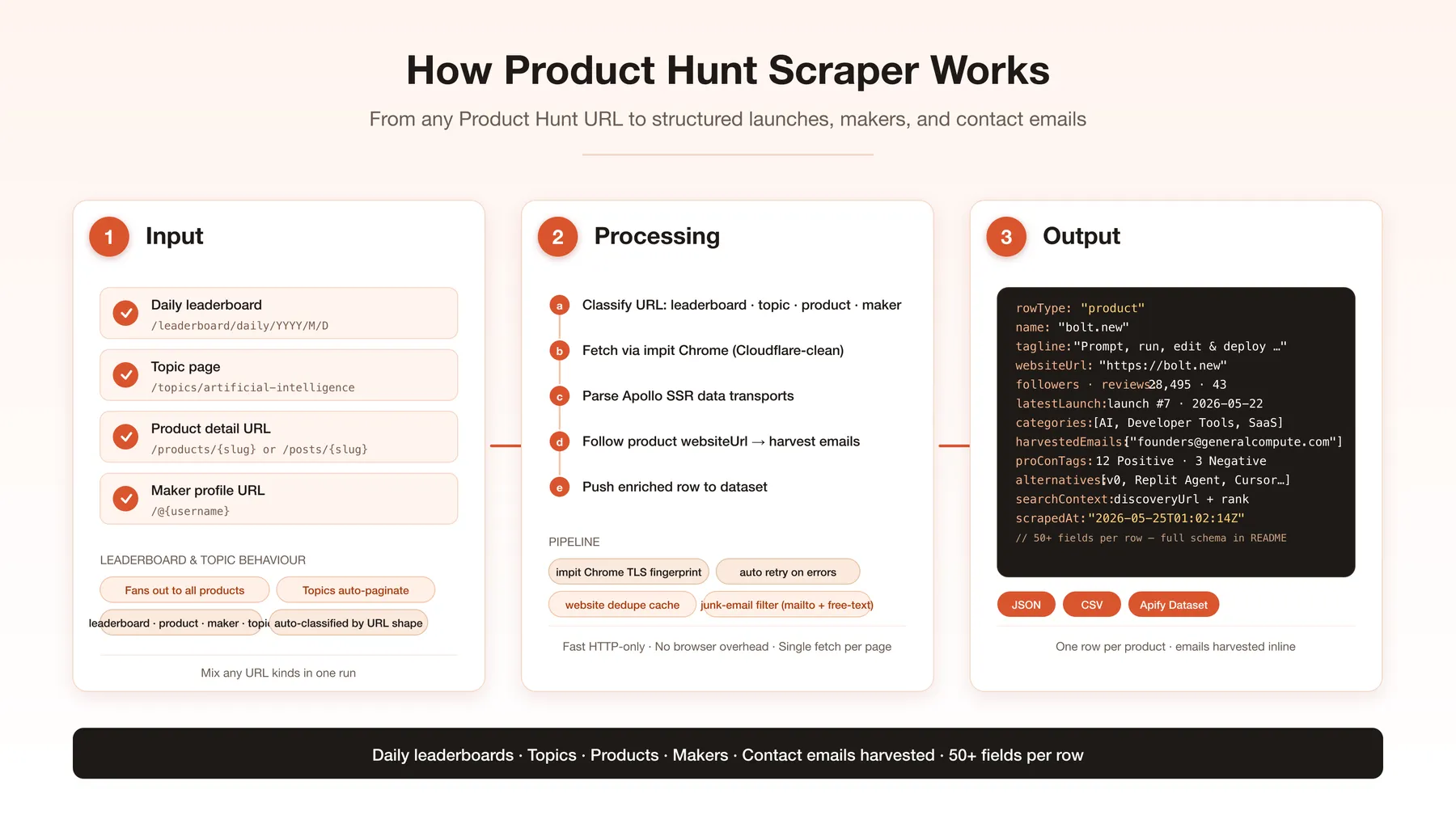
- Input — paste any mix of Product Hunt URLs (homepage, leaderboards, topics, collections, products, makers)
- Auto-classify & fan out — each URL is routed to the right handler; listing URLs expand to their products
- Fetch — pages are retrieved over HTTP with a real Chrome TLS fingerprint (passes Cloudflare without a browser)
- Parse & enrich — the Apollo cache is read for 50+ fields, votes/rank/comments, and the media gallery; optionally add reviews, discussion threads/comments, contact emails from each product's site, and makers/hunter
- Output — one product row per launch (or one maker row per
/@username), as JSON or CSV
Input Configuration
| Field | Type | Required | Notes |
|---|---|---|---|
startUrls | array<string | { url }> | yes | Any mix of supported Product Hunt URLs. Auto-classified. |
enrichMakerEmails | boolean | no | Default true. For each product, fetch its websiteUrl and harvest emails (junk-filtered, capped at 10/site, deduped per URL). Each unique email found is billed as a small add-on (see Store pricing). Disable for pure PH metadata (~30% faster). |
scrapeReviews | boolean | no | Default false. Attach detailed reviews per product (one extra request each). |
maxReviews | integer | no | Default 50. PH server-renders ~10, so higher values rarely add more. |
scrapeComments | boolean | no | Default false. Attach the launch's discussion threads (one extra request each). Full comment bodies require an API token. |
maxComments | integer | no | Default 20. Cap on comment bodies fetched per launch via the API. |
apiToken | string (secret) | no | Your own Product Hunt developer token. Unlocks makersEnriched + hunter, and comment bodies when scrapeComments is on. Blank = skip. |
maxItems | integer | no | Hard cap on total dataset rows. Default 2000. Free-tier runs are capped at 100. |
maxConcurrency | integer | no | Detail pages fetched in parallel. Default 8 (6–10 is the sweet spot). |
minConcurrency | integer | no | Minimum parallelism. Default 1. |
maxRequestRetries | integer | no | Per-URL retry budget. Soft-blocks/thin bodies auto-retried with a fresh session. Default 5. |
proxy | object | no | Defaults to Apify Proxy. Supply your own residential pool for geo-locked output or heavy runs. |
Common scenarios
1. A day's launches with contact emails
2. Launches with reviews and discussion threads
3. Full enrichment — emails + makers + hunter + comment bodies
To get a token: log in to Product Hunt → producthunt.com/v2/oauth/applications → Add an application → Create Token. Paste it into apiToken. It's used only for your runs.
Output Overview
Each dataset item is one of two shapes, set by rowType:
product— emitted for every product (from leaderboards, topics, collections, the homepage, or direct product URLs). Carries the full 50+ field schema, plusreviews[],discussionThreads[], andcomments[]when enabled.maker— emitted only for a direct/@usernameURL. Profile + the maker's launched products.
Notes on when fields are populated:
- Votes, rank, comments count,
featuredAtare present on rows discovered via a leaderboard/topic/collection. They'renullon a direct/products/{slug}URL (no ranking context). reviews[]appears only withscrapeReviews;discussionThreads[]only withscrapeComments;comments[](bodies) only when a token is available.makersEnriched+hunterrequire anapiToken.harvestedEmailsrequiresenrichMakerEmailsand a site that exposes an email.
Output is nested JSON by default; the Apify Console "Export" tab flattens it to CSV.
Output Samples
Product row — leaderboard-discovered, with reviews + threads
Maker row — direct /@username
Key Output Fields
Identity & links
rowType,productId,slug,name,tagline,description,sourceUrl,canonicalUrlwebsiteUrl,githubUrl,iosUrl,androidUrl,twitterUrl,linkedinUrl,facebookUrl,instagramUrl
Ranking, engagement & media
votesCount,launchDayScore,dailyRank,weeklyRank,monthlyRank,commentsCount,featuredAtreviewsCount,reviewsRating,followersCountmedia[]—mediaType(image/video),imageUuid,width,height,videoId
Business, categories & sentiment
employeeSize,fundingAmount,wasInYCombinator,isTopProduct,isNoLongerOnlinecategories[],latestLaunch,firstPost,alternatives[],proConTags[]
Reviews (with scrapeReviews)
reviews[].overallRating,.easeOfUseRating,.reliabilityRating,.valueForMoneyRating,.customizationRatingreviews[].overallExperience,.positiveFeedback,.negativeFeedback,.selectedPros,.selectedCons,.votesCount,.reviewer
Discussion & comments (with scrapeComments)
discussionThreads[].title,.descriptionPreview,.commentsCount,.isPinned,.authorcomments[].body,.votesCount,.url,.author(require an API token)
Enrichment (optional)
harvestedEmails[](withenrichMakerEmails),makersEnriched[],hunter(withapiToken)
Discovery context
searchContext.discoveryUrl,.resultPosition,.leaderboardDate,.topicSlug,.collectionSlug
FAQ
Which Product Hunt URLs are supported?
Homepage, daily/weekly/monthly/yearly leaderboards, topics, collections (and the /collections index), product detail (/products/{slug} or /posts/{slug}), and maker profiles (/@username). Mix any of them in startUrls. Keyword search (/search) is not supported — PH loads those results client-side.
Do I get product rows or leaderboard/collection rows?
Product rows. Leaderboards, topics, collections, and the homepage all fan out to product rows (rowType: "product"). Only a direct /@username URL produces a maker row.
What do scrapeReviews and scrapeComments add?
scrapeReviews attaches a reviews[] array (full text, five ratings, pros/cons, reviewer) from each product's reviews page. scrapeComments attaches discussionThreads[] (title, preview, count, author). Each adds one HTTP request per product and is off by default.
Do I need a token for comments?
Only for comment bodies. The discussion-thread metadata (discussionThreads[]) is in the page HTML and works with no token. The actual comment text (comments[]) is loaded by Product Hunt over its API, so it's fetched only when a token is available (your apiToken, or an operator-configured fallback).
How do I get makers and the hunter?
Supply your own free Product Hunt developer token in apiToken (see Input Configuration). Makers + hunter are not in Product Hunt's server-rendered HTML, so they appear only when a token is provided.
Why are votesCount / dailyRank sometimes null?
Those come from a leaderboard/topic/collection's ranking data. A direct /products/{slug} URL has no ranking context, so they're null. Reach a product via a leaderboard to get them.
Some products have harvestedEmails: [] — why?
Email harvesting is best-effort. A site may not publish an email, may load it via JavaScript, or may obfuscate it. Realistic harvest rate is roughly 30–50% of product sites.
Can I scrape private or login-gated content?
No. The actor only reads publicly available pages. Anything behind a Product Hunt login is out of scope.
What about rate limits?
The scraper runs cleanly at maxConcurrency=8; lower it or add a residential proxy if you see soft-blocks. The optional apiToken enrichment (makers/hunter/comment bodies) is subject to Product Hunt's API limits (complexity-based, ~6250 units per 15 minutes) — large runs may enrich only part of the set, and the row is always emitted regardless.
Support
Found a bug, hit a soft-block we don't detect, or want another URL kind supported? Open an issue on the actor's Issues tab, or reach out via the memo23 profile on Apify.
Additional Services
Need a custom export shape, a new entry point, or scheduled monitoring? I build tailored scrapers and enrichment pipelines — get in touch via the memo23 profile.
Explore More Scrapers
If you track Product Hunt launches, founders, and prospects, these pair well:
- Y Combinator Scraper — companies + jobs from YC; cross-reference the
wasInYCombinatorflag - G2 Scraper — see how a launched SaaS ranks on G2 reviews
- Trustpilot Scraper — customer sentiment for products you discover
- LinkedIn Profiles Scraper — backfill founder profiles for makers
- PagesJaunes Leads Scraper — bulk B2B leads with emails
Full portfolio: apify.com/memo23.
⚠️ Disclaimer
This Actor is an independent tool and is not affiliated with, endorsed by, or sponsored by Product Hunt or any of its parent companies or subsidiaries. All trademarks mentioned are the property of their respective owners.
The scraper accesses only publicly available Product Hunt pages — no authenticated endpoints, private launches, or content behind the producthunt.com login wall. The optional API enrichment uses Product Hunt's official API with a token you supply under your own account. Users are responsible for ensuring their use complies with Product Hunt's Terms of Service, the Product Hunt API terms, applicable data-protection law (GDPR, CCPA, etc.), and any contractual obligations of their own organization. Harvested contact emails are personal data — process them responsibly, honor opt-outs, and seek legal advice before outbound marketing.
SEO Keywords
product hunt scraper, scrape product hunt, producthunt scraper, product hunt api, product hunt.com scraper, Apify product hunt, product hunt leaderboard scraper, product hunt topic scraper, product hunt collections scraper, product hunt reviews scraper, product hunt comments scraper, maker profile scraper, product launch scraper, product hunt maker emails, founder contact scraper, saas launch tracker, b2b lead generation data, vc deal sourcing, ai product tracker, startup launch intelligence