Y Combinator · YC · Only $1💰 · Jobs & Companies scraper
Pricing
from $1.00 / 1,000 results
Y Combinator · YC · Only $1💰 · Jobs & Companies scraper
💰 $1/1K One actor for Y Combinator jobs (Work at a Startup) and companies (Startup Directory). Paste any YC URL — auto-routed — or use filters. Companies via Algolia: no proxy, clean schema. Optional founder enrichment: LinkedIn/Twitter URLs, company socials, open jobs. Full batch history to 2005.
Pricing
from $1.00 / 1,000 results
Rating
4.6
(2)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
3
Bookmarked
138
Total users
34
Monthly active users
3 days ago
Last modified
Categories
Share
Y Combinator Scraper — Jobs + Companies + Founders

Y Combinator data, structured. Jobs, companies, founders, socials — one actor, no proxy needed for companies.
Scrape both surfaces of ycombinator.com from a single Apify actor: jobs (Work at a Startup) and companies (Startup Directory). Auto-routes any YC URL to the right scraper, or compose a query from filters.
💰 $1 per 1,000 results — the cheapest YC scraper on Apify Store. Pure HTTP for companies (no proxy, no browser), Crawlee + Cheerio for jobs. JSON or CSV out.
How it works
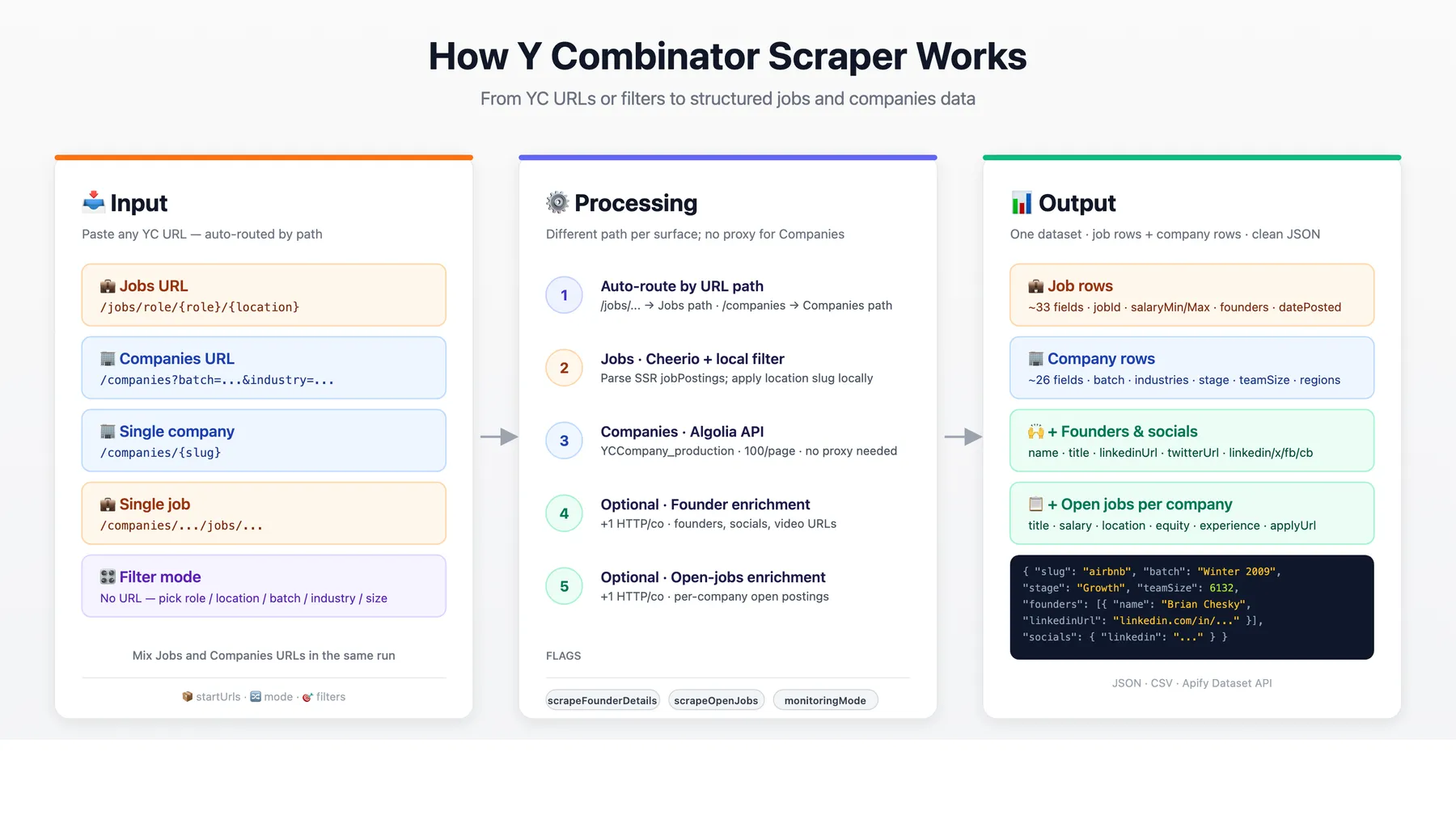
✨ Why use this scraper?
- Two surfaces, one actor. Jobs (Work at a Startup) and Companies (Startup Directory) in the same dataset, distinguishable by row shape (
jobIdvsslug). - Companies fetch via YC's public Algolia index — no HTML parsing, no proxy required, ~2 s for 100 rows. Clean, structured fields with no scraping artefacts (no leaked alt text, no concatenated values).
- Rich output schemas. ~33 fields per job (salary parsed into min/max/currency, equity, founders with bios, JSON-LD
datePosted). ~26 fields per company (batch, industries, regions, team size, stage, status, top-company / hiring / nonprofit flags). - Optional founder enrichment with proper
name/titleseparation (e.g.Brian Chesky/Founder/CEO, not split-on-whitespace), plus LinkedIn + Twitter URLs per founder and company-level socials (linkedin, twitter, facebook, crunchbase, github). - Optional open-jobs enrichment per company, with cleanly separated
title/salary/location/equity/experiencefields. - Multi-keyword company discovery — pass several keywords; each runs as a separate Algolia search and results merge by company id with dedupe.
- Full YC batch history back to Summer 2005.
What makes this richer than alternatives
| Capability | This actor | Other YC scrapers on Apify Store |
|---|---|---|
| Pricing | $1 / 1,000 results | $1.99 – $2.80 / 1K |
| Surfaces covered | Jobs + Companies (one actor, two row shapes) | Jobs only on most |
| Companies fetch | Direct via YC's public Algolia — no proxy, ~2s for 100 rows | HTML scraping with proxy |
| Founder enrichment | LinkedIn + Twitter URLs, separate name / title fields, optional toggle | Often missing or whitespace-split |
| Salary parsing | salaryMin, salaryMax, salaryCurrency parsed numerically | Raw display string only |
| Multi-keyword discovery | Union + dedupe across multiple Algolia queries in one run | Single keyword only |
| Batch history | Back to Summer 2005 (every YC cohort) | Recent batches only |
| Output options | JSON or CSV (data.csv auto-exported) | JSON only |
| Monitoring mode | Per-user dedup for incremental scheduled runs | Not supported |
Overview
Built for recruiters, sourcers, BD/sales teams, investors, and anyone doing market research on YC-backed startups. The actor produces a heterogeneous dataset: each row is either a job posting or a company profile. You can run jobs and companies in the same job (mix URLs of both kinds), and tell them apart in downstream tooling by the presence of jobId (jobs) vs slug (companies).
Companies-mode goes through YC's Algolia search API — fast, no proxy, no HTML parsing. Jobs-mode uses Crawlee + Cheerio against YC's server-rendered job listing/detail pages.
Supported inputs
Jobs URLs
| Pattern | What it does |
|---|---|
/jobs | YC's curated jobs index (~20 jobs) |
/jobs/role/{role} | All jobs in a role (software-engineer, designer, product-manager, operations, marketing, sales-manager, recruiting-hr, support, science) |
/jobs/role/{role}/{location} | Role + location (san-francisco, new-york, los-angeles, seattle, austin, chicago, india, remote) — location applied locally because YC filters it client-side |
/jobs/location/{location} | Location-only listing |
/companies/{co}/jobs/{job} | A single job-detail page |
Companies URLs
| Pattern | What it does |
|---|---|
/companies | All companies (paginated through Algolia) |
/companies?batch=…&industry=…&query=…&isHiring=true&top_company=true&minEmployeeSize=10%2B&maxEmployeeSize=100 | Companies search with any combination of filters |
/companies/{slug} | Single-company lookup (e.g. …/companies/airbnb) |
Filter form (when no URLs)
mode = jobs (default) or companies. Then the matching filter set:
- 💼 Jobs:
role,location. - 🏢 Companies:
queries[],topCompany,isHiring,nonprofit,batch[],industries[],regions[],minEmployeeSize,maxEmployeeSize.
🎯 Use cases
| Team | Typical use |
|---|---|
| Recruiters / talent sourcing | Pull active YC job postings filtered by role + city, watch for new postings in monitoringMode |
| Investors / VCs | Track company batches, stages, and team sizes across every YC cohort back to 2005 |
| BD / sales | Build a target list of YC companies by industry, region, employee size; enrich with founder LinkedIns for outreach |
| Founder / market research | Discover companies by keyword across the full directory; find similar / competitive companies to map a market |
| Data engineering / pipelines | Schedule daily runs into a warehouse for YC startup intelligence; monitoringMode keeps datasets incremental |
- You provide YC URLs (Option A) or filters (Option B). Mix Jobs and Companies URLs freely; the actor routes each one.
- Jobs URLs hit a Crawlee CheerioCrawler. The listing's inlined
jobPostingsJSON is parsed; the location slug from the URL is applied as a local substring filter against each job's location string (YC's listings filter location client-side, so we compensate). - Companies URLs hit YC's public Algolia index (
YCCompany_production). All Algolia filters compose with AND across attributes / OR within attribute. Multi-keyword runs union the results and dedupe byobjectID. - Optional company enrichment. When
scrapeFounderDetailsorscrapeOpenJobsis on, the actor fetches/companies/{slug}and/or/companies/{slug}/jobsper row and merges the parsed founders/socials/openJobs into the company row. Concurrency = 5. - Output to dataset. Job rows and company rows go into the same dataset; jobs are also exported as
data.csv/data.json.
Banner source is readme-stuff/how-it-works-yc-v1.svg — edit the SVG and re-rasterize when you change the copy. A 2× retina version is at readme-stuff/how-it-works-yc-v1@2x.png (this is the version hosted at the URL above). The hosted PNG is served from a GitHub Pages repo so it renders in both GitHub and the Apify Console.
Quick start
Input configuration
The form is two collapsible sections — alternatives, not steps:
Three top-level sections. Option A and Option B are alternatives; Run options apply to both regardless of which you pick.
- Option A | Search by URL 🔗 — Jobs or Companies (recommended) —
startUrls[]. If non-empty, Option B is ignored. - Option B | Configure with Filters 🎛️ — used only when Option A is empty. Field titles inside the panel are prefixed by category:
Mode—"jobs"(default) or"companies".💼 Jobs · …—role,location.🏢 Companies · …—queries[],topCompany,isHiring,nonprofit,batch[],industries[],regions[],minEmployeeSize,maxEmployeeSize.🙌 Companies Enrich · …—scrapeFounderDetails,scrapeOpenJobs(each adds one HTTP per company; concurrency 5).
- Run options ⚙️ — applies to both — shared run-time settings:
maxItems— per-URL output cap (default 100). Each entry instartUrls(Option A) and each filter run (Option B) gets its own quota of this many records. Pasting 3 URLs withmaxItems=100returns up to 300 rows total. Free-tier accounts are capped at 100 per URL regardless.maxPages— pagination depth: max listing pages per URL (default 10). Jobs scraper only; Companies paginates Algolia automatically until its per-URLmaxItemsquota is hit.monitoringMode,maxConcurrency,minConcurrency,maxRequestRetries,proxy— Jobs scraper only. Companies hits Algolia directly and ignores them.
Multi-select filters (batch[], industries[], regions[]) use AND across attributes, OR within. The "All …" sentinel values (default) are stripped before the Algolia query so leaving them = no filter.
Non-paying users are capped at 100 items and have monitoringMode disabled.
Note on YC's location filtering
YC's listing pages include a location segment in the URL but apply that filter client-side — the SSR'd jobPostings JSON is role-filtered only. This actor compensates by parsing the location slug out of the URL and applying a substring filter against each job's location string locally. Special cases: remote matches anything containing "Remote"; india matches the country (/\b(india|IN)\b/i). Cities use a case-insensitive substring match against the slug with - replaced by space.
A job listed as "San Francisco, CA, US / Remote (US)" matches both the san-francisco and remote slugs.
Output overview
Heterogeneous dataset — job rows and company rows have different shapes but share the same dataset. Distinguish by:
- presence of
jobId(jobs) vsslug(companies) - or the
urlpath (/companies/{co}/jobs/{job}vs/companies/{slug}).
Output samples
Job row (truncated for display)
Captured with startUrls=["https://www.ycombinator.com/jobs/role/software-engineer/san-francisco"], maxItems=1:
Company row, with both enrichment toggles on (truncated)
Captured with startUrls=["https://www.ycombinator.com/companies/airbnb"], scrapeFounderDetails=true, scrapeOpenJobs=true:
Output fields
Jobs row (~33 fields)
| Field | Description |
|---|---|
jobId | YC's job id, e.g. gD334As-systems-engineer. |
title, url | Posting title and absolute URL (https://www.ycombinator.com/companies/{co}/jobs/{id}). |
companyName, companySlug, companyUrl, companyTagline | Company display name, slug, profile URL, one-liner. |
ycBatch | YC batch (e.g. S21, W18). |
jobType, roleCategory, roleSubcategory | E.g. Full-time, Engineering, Devops. |
salaryRange | Raw display string from the listing ("$185K - $225K"). |
salaryMin, salaryMax, salaryCurrency | Parsed numeric range and currency (USD/GBP/EUR/INR). |
equity | Equity range string from YC. |
location | Job location string from YC. |
postedAgo | Relative time from listing (e.g. "2 days"). |
applyUrl | Direct apply link (the YC OAuth bridge to workatastartup.com). |
experience | Min experience requirement. |
visaSponsorship | "Will sponsor" if offered, else empty. |
description, descriptionHtml | Full description as text and as HTML (preserves newlines). |
companyDescription, companyFounded, companyTeamSize, companyStatus, companyLocation | Company metadata. |
founders | Array of { name, role } — role falls back through founder_bio → title → "Founder". |
datePosted | ISO datetime from the embedded JobPosting JSON-LD. |
companyWebsite, companyLogo | External website and YC small-logo URL. |
scrapedAt | ISO timestamp of when the row was produced. |
Companies row (~26 fields, plus enrichment fields)
| Field | Description |
|---|---|
id, slug, name | YC company id, slug, display name. |
url | Profile URL (https://www.ycombinator.com/companies/{slug}). |
batch | E.g. "Winter 2009", "Spring 2026". |
industry, subindustry, industries[] | Top-level industry, second-level subindustry, full industries array. |
regions[] | HQ region tags. |
allLocations | Free-form location string. |
oneLiner, longDescription | Short tagline and full description. |
teamSize | Headcount or null. |
status | "Active" / "Acquired" / "Public" / "Inactive" / etc. |
stage | YC's stage label: "Early" / "Growth" / "Public" / etc. |
topCompany, isHiring, nonprofit | Booleans. |
launchedAt | ISO datetime (converted from epoch). |
website | External company website. |
logo | Small-logo URL from YC's S3. |
tags[] | Free-form YC tags. |
formerNames[] | Past company names if YC has them. |
appVideoPublic, demoDayVideoPublic | Whether YC's videos are publicly available. |
scrapedAt | ISO timestamp. |
With scrapeFounderDetails: true:
| Field | Description |
|---|---|
founders[] | { name, title, bio, linkedinUrl, twitterUrl, avatarUrl, isActive, hasEmail }. name and title are properly separated. |
socials | { linkedin, twitter, facebook, crunchbase, github } (non-empty values only). |
appVideoUrl, demoDayVideoUrl | Direct video URLs when YC has them and they're public. |
With scrapeOpenJobs: true:
| Field | Description |
|---|---|
openJobs[] | { jobId, title, url, type, roleCategory, roleSubcategory, salaryRange, equity, location, experience, applyUrl, postedAgo, visaSponsorship }. |
Monitoring mode
When monitoringMode is enabled (jobs only), the actor only emits jobs whose numeric id has not been seen in previous runs by the same Apify user. Useful for:
- Tracking new YC job postings as they appear
- Building a historical archive without re-scraping
- Keeping downstream notifications free of duplicates
The actor maintains a per-user Key-Value store keyed YC-JOBS-SEEN-{apifyUserId}. On each run with monitoringMode: true, every listing job is checked against this store; new ids are added (with a small stub: id, url, title) and only those new jobs are enqueued for detail scraping. Reset by deleting the corresponding KV store from the Apify console.
monitoringMode is currently jobs-only. Companies-mode dedup is planned but not implemented.
Local development
Local input is read from storage/key_value_stores/default/INPUT.json. For fully isolated runs set APIFY_LOCAL_STORAGE_DIR and CRAWLEE_STORAGE_DIR to a temp path.
Limitations / known gaps
- Single-company URL uses Algolia full-text query + post-filter to exact slug match (slug isn't in YC's filterable attributes). Returns 1 row max regardless of
maxItems. - Companies mode ignores
monitoringMode— dedup is jobs-only for now. maxItemsis per URL, not global. With 5 startUrls andmaxItems=100, total output can be up to 500 rows (100 per URL). Set the cap accordingly to control cost.- Multi-
queriesbudget is shared across keywords within a single companies search URL/filter run. IfmaxItemsis small, later keywords may not fire (the first keyword fills the quota and the remaining keywords don't run). - Companies enrichment cost —
scrapeFounderDetailsandscrapeOpenJobseach add one HTTP per company (concurrency = 5). For 100 companies, expect ~10–20 seconds extra per toggle.
❓ FAQ
Can I scrape both jobs and companies in the same run?
Yes. Mix any /jobs/... and /companies... URLs in startUrls; each one auto-routes. maxItems is per URL, not global — pasting 5 URLs with maxItems=100 can return up to 500 rows total.
Does the Companies path need a proxy? No. It hits YC's public Algolia index directly, no rate-limit issues, no IP blocks. The proxy setting only applies to the Jobs scraper.
What does the Jobs location slug actually filter on?
A case-insensitive substring of the slug (with - → ) against each job's location string. remote matches anything containing "Remote"; india matches the country code IN or the word India. YC applies that filter client-side, so we replicate it locally.
Can I get founders' LinkedIn URLs?
Yes — set scrapeFounderDetails: true. Each founder row includes linkedinUrl and twitterUrl parsed from the inlined company JSON on /companies/{slug}.
Does scrapeOpenJobs overlap with running Jobs mode?
Different surface. scrapeOpenJobs enriches a company row with that company's open postings. Jobs mode (or a /jobs/... URL) returns each job as its own row in the dataset.
What's monitoringMode and when should I use it?
Jobs-only flag that dedupes against a per-user KV store of seen job ids. Use it for scheduled runs that should only emit new postings.
Can I use the actor with a single-company URL like /companies/airbnb?
Yes. It returns exactly one row regardless of maxItems because slug isn't a filterable Algolia attribute — the actor full-text-searches the slug and post-filters to an exact match.
How do I control cost?
Use maxItems strictly — both modes stop emitting once that ceiling is hit. Disable both enrichment toggles if you don't need founders/socials/jobs — they add HTTP per row.
Support
- File an issue or a feature request via the Apify Console Issues tab on the actor page.
- Custom integrations (different output shape, additional filters, scheduled feeds into a warehouse) — open an issue describing the use case.
- The repo source is open in src/ —
main.tsorchestrates dispatch,lib/ycScrape.tshandles jobs HTML parsing,lib/ycCompanies.tsis the Algolia client + enrichment.
Additional Services
Need a Y Combinator dataset shaped to your pipeline? Custom integrations available:
- Custom output schemas — alternative field names, flattened nested structures, filtered subsets for warehouse loaders.
- Webhook delivery — push new YC jobs or company changes to Slack, Discord, your CRM, or any HTTP endpoint.
- Scheduled feeds — daily/weekly runs into Postgres, BigQuery, Snowflake, S3, or Google Sheets.
- Bundled scrapers — combine YC data with LinkedIn, Crunchbase, or AngelList for a multi-source pipeline.
- Private / dedicated builds — your own version of the actor with niche filters, custom enrichment, or different rate behavior.
Reach out via the Apify Issues tab or contact memo23 on Apify.
Explore More Scrapers
Looking for related job, recruiting, or startup-intelligence data? Other actors by the same maintainer:
- HiringCafe Scraper — All HiringCafe job postings with company info, salary, remote/location filters
- Stepstone Search Scraper — DACH + EU jobs by URL or keywords
- LinkedIn Jobs Scraper — Public LinkedIn job listings by keyword + location
- Glassdoor Reviews — Company reviews + ratings + interview reports
- Capterra Reviews Scraper — B2B SaaS reviews + scoring + competitor analysis
🤖 For AI Agents & LLM Apps
Compact reference for AI agents calling this actor via the Apify MCP server or the Apify API (actor: memo23/y-combinator-scraper).
Purpose: Scrapes both YC surfaces — jobs (Work at a Startup) and companies (Startup Directory) — from one actor; companies fetch via YC's public Algolia index (no proxy), with optional founder/social and open-jobs enrichment.
Minimal input:
URL mode variant: { "startUrls": ["https://www.ycombinator.com/companies/airbnb"], "maxItems": 25 } (any /jobs/... or /companies... URL, auto-routed).
Output: heterogeneous dataset — one row per job OR company (tell apart by jobId vs slug). Job rows: jobId, title, url, companyName, companySlug, ycBatch, jobType, roleCategory, salaryRange, salaryMin, salaryMax, salaryCurrency, equity, location, postedAgo, experience, description, founders[] (name, role), datePosted, companyWebsite, scrapedAt. Company rows: id, slug, name, url, batch, industry, industries[], regions[], oneLiner, teamSize, status, stage, topCompany, isHiring, nonprofit, launchedAt, website, tags[], scrapedAt, plus enrichment founders[] (name, title, linkedinUrl, twitterUrl), socials (linkedin, twitter, facebook, crunchbase, github), openJobs[].
Behaviors an agent should know:
maxItemsis a per-URL / per-filter-run cap (default 100), not global — 3 start URLs atmaxItems=100returns up to 300 rows; free-tier accounts are capped at 100 per URL.startUrls(Option A) overrides the filter form (Option B) entirely when non-empty.- Companies mode hits YC's Algolia directly (no proxy); Jobs mode uses Cheerio —
proxy, concurrency, retries, andmonitoringModeapply to Jobs only. scrapeFounderDetailsandscrapeOpenJobs(companies mode) each add one HTTP per company (concurrency 5); a single/companies/{slug}URL returns exactly one row regardless ofmaxItems.monitoringMode(jobs only) emits only job ids not seen in prior runs by the same Apify user.- Billing: $1 per 1,000 results.
⚠️ Disclaimer
This Actor accesses publicly available data on Y Combinator's website (ycombinator.com) and its public Algolia search index for legitimate research, market intelligence, and business-analysis purposes. Use of this Actor must comply with Y Combinator's Terms of Service and all applicable laws, including data protection regulations (GDPR, CCPA, etc.). "Y Combinator" and "YC" are trademarks of Y Combinator Management, LLC. This Actor is not affiliated with, endorsed by, or sponsored by Y Combinator. The Actor's authors are not responsible for any misuse. Users must:
- Respect rate limits and avoid overloading YC's infrastructure
- Not use scraped data to violate user privacy or any terms
- Use the data in compliance with applicable jurisdictions
- Not republish scraped content in violation of copyright
We do not store any scraped data; the Actor returns it directly to your Apify dataset for your authorized use.
SEO Keywords
y combinator scraper, ycombinator scraper, yc jobs scraper, work at a startup scraper, yc companies scraper, yc startup directory scraper, yc batch scraper, y combinator api alternative, yc data extraction, yc founder scraper, ycombinator founders linkedin, yc startup intelligence, startup data scraping, yc recruiter tool, yc lead generation, yc sales prospecting, yc batch winter 2026, yc spring 2026, yc demo day scraper, yc graduates list, y combinator json export, y combinator csv export, apify yc scraper, b2b startup database, vc lead generation
License
ISC. See package.json.