WeWorkRemotely Jobs Scraper [Only $0.99💰] [/w EMAILS]
Pricing
from $0.99 / 1,000 results
WeWorkRemotely Jobs Scraper [Only $0.99💰] [/w EMAILS]
Scrape WeWorkRemotely for remote-job leads at $0.99/1K — recruit cross-border, benchmark salaries, mirror the board into your warehouse. Title, company, salary, employment type, eligible-countries list (200+ per job), external apply URL. Auto-routes any WWR URL. JSON or CSV.
Pricing
from $0.99 / 1,000 results
Rating
0.0
(0)
Developer
Muhamed Didovic
Maintained by CommunityActor stats
0
Bookmarked
49
Total users
11
Monthly active users
4 days ago
Last modified
Categories
Share
WeWorkRemotely Jobs Scraper
How it works
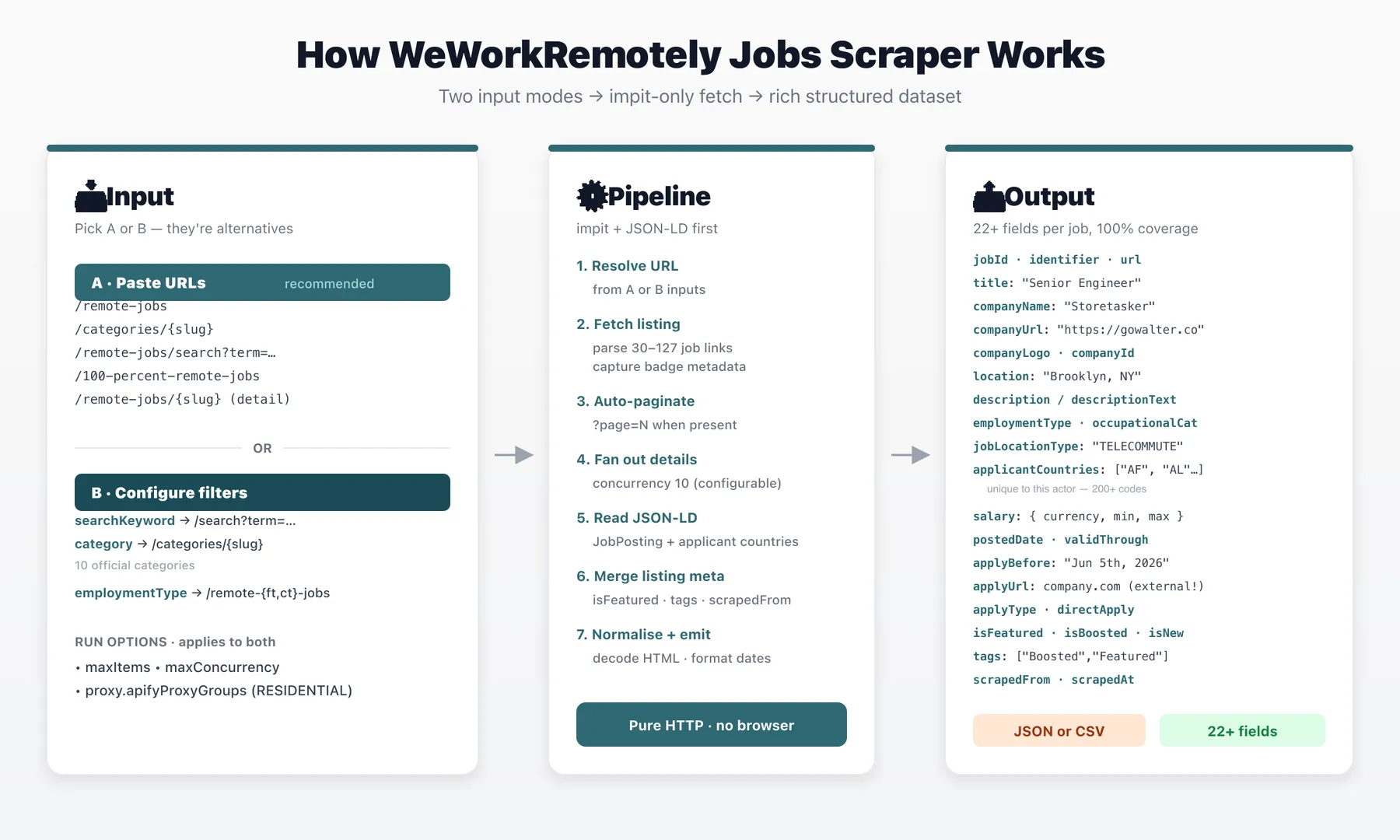
Scrape every remote job on WeWorkRemotely.com — title, company, full description, salary, employment type, applicant country eligibility (200+ countries per job), and the real external apply URL. One actor, JSON or CSV out.
Paste any WeWorkRemotely URL — the main listing, a category, a search, or a direct job link — and get a clean dataset with one row per job. Auto-routes by URL pattern. Pure HTTP (no browser, no CAPTCHA solver).
💰 $1.99 per 1,000 results. Half the price of the next-tier competitor, with a richer schema and the only WWR scraper that surfaces
applicantCountries.
✨ Why use this scraper?
- Every URL surface, one actor. Main listing (
/remote-jobs), category pages (/categories/{slug}), search results (/remote-jobs/search?term=...), and direct job-detail URLs are all accepted. URLs are auto-classified — mix freely in one run. - JSON-LD-first parsing. Every WWR detail page exposes a structured
JobPostingblock. We extract from that, not brittle DOM selectors — your scrapes don't break when WWR redesigns. - The
applicantCountriesdifferentiator. WeWorkRemotely encodes a per-job country eligibility list (often 200+ countries). No other scraper on the Apify Store exposes this cleanly. It's the field for geo-targeted recruiting. - Real external apply URL. The on-page "Apply now" button is locked behind a WWR login on most jobs. We extract the JSON-LD
urlfield, which is the actual company-side apply URL — what your buyers actually want. - Salary parsing.
salaryMin,salaryMax,salaryCurrency, andunitparsed from JSON-LDbaseSalary. (Note: WWR sometimes uses 0/0 as a placeholder when the employer didn't supply a salary — that's surfaced asmin: 0, max: 0, not omitted.) - Pagination handled. Category and search listings paginate via
?page=N; the actor walks all pages untilmaxItemsis hit. - JSON or CSV out. Auto-exported to both formats for every run.
What makes this richer than alternatives
| Capability | This actor | Other WWR scrapers on Apify Store |
|---|---|---|
| Pricing | $1.99 / 1,000 results | Free up to $4 / 1K |
applicantCountries | ✅ Full country array (200+ entries) | ❌ Not exposed by any other scraper |
| External apply URL | ✅ Real company-side URL from JSON-LD | ⚠️ Often returns WWR's locked "Apply now" link |
| Salary parsing | ✅ min, max, currency, unit from JSON-LD | ⚠️ Often raw string only |
| URL surfaces | Main + category + search + direct | Mostly main listing or single URL only |
| Pagination | Auto-walks ?page=N | Mixed (some scrapers stop at page 1) |
| Output options | JSON + CSV (auto-exported) | JSON only on most |
| HTTP stack | impit (Firefox/Chrome TLS fingerprints) + retry chain | Plain HTTP on some |
Supported inputs
The actor has two alternative input paths — pick one:
Option A — Search by URL 🔗 (recommended)
Paste any weworkremotely.com URL in startUrls. Any WWR page that lists jobs is supported — the actor extracts every /remote-jobs/{slug} anchor from whatever page you paste.
Listing URLs
| Pattern | Example | What it does |
|---|---|---|
/remote-jobs | /remote-jobs | Main remote-jobs listing |
/categories/{slug} | /categories/remote-front-end-programming-jobs, /categories/remote-customer-support-jobs, etc. | Category listings (every WWR category works) |
/100-percent-remote-jobs | /100-percent-remote-jobs | Location / scope filter pages |
/remote-full-time-jobs / /remote-contract-jobs | same | Employment-type filters |
/remote-jobs/search?term={query} | /remote-jobs/search?term=javascript | Search results |
Job detail URLs
| Pattern | What it does |
|---|---|
/remote-jobs/{company-slug}-{job-slug} | Single job — fetched and parsed directly. URL may end with -1/-2/-3 etc. when the company has multiple jobs with similar slugs. |
Mix any combination in startUrls; each URL is auto-classified by shape.
Option B — Configure with Filters 🎛️
Leave startUrls empty and pick filters instead. The actor builds the matching WWR URL from your selection.
| Filter | Routes to | Notes |
|---|---|---|
searchKeyword | /remote-jobs/search?term=… | Highest priority — wins over category if both are set |
category | /categories/{slug} | 10 official categories supported (Full-Stack Programming, Front-End, Back-End, DevOps, Design, Product, Management & Finance, Sales & Marketing, Customer Support, All Other) |
employmentType: full-time | /remote-full-time-jobs | Only applied when keyword + category are empty |
employmentType: contract | /remote-contract-jobs | Same |
| nothing | /remote-jobs | Default — all jobs |
WWR filters do not combine (a keyword on a category URL is ignored by WWR's server), so the actor picks exactly one URL from your filter inputs in the priority order above. If you need multi-filter behavior, use Option A and paste multiple URLs.
Option A wins when both are set — if startUrls is non-empty, Option B filters are ignored entirely.
🎯 Use cases
| Team | Typical use |
|---|---|
| Recruiters / talent sourcing | Pull active remote jobs by category (programming, design, marketing, support, etc.) and country eligibility. Filter on applicantCountries to find jobs open to candidates in your region. |
| Job-board aggregators | Mirror WWR's listings into your own dataset with normalised fields. Schedule daily runs to capture new postings. |
| Salary benchmarking | Build a remote-salary dataset from salaryMin / salaryMax / salaryCurrency across categories. |
| Sales / BD | Build a target list of remote-first companies hiring engineers / designers / etc., with their external website (companyUrl) for outreach. |
| Market research | Track which job categories and countries are most heavily represented across WWR over time. |
Quick start
Input configuration
| Field | Type | Required | Notes |
|---|---|---|---|
startUrls | string[] | yes (or use Option B) | Listing, category, search, or detail URLs. Mix freely. |
category | string | optional (Option B) | One of the 10 WWR categories. Routes to /categories/{slug}. |
searchKeyword | string | optional (Option B) | Keyword search. Wins over category if both are set. |
employmentType | string | optional (Option B) | full-time / contract. Only used when category and searchKeyword are empty. |
includeDetailPages | boolean | no (default true) | ON — fetch every job's detail page (full 23+ field schema). OFF — emit rows directly from listing cards (~12 fields, ~30× faster). |
countries | string[] | no | Post-filter on applicantCountries[]. ISO-2 codes (e.g. ["US", "GB", "DE"]). Empty = no filter. No effect in listing-only mode. |
timeFilter | string | no (default any) | Post-filter on postedDate. One of "", "24h", "7d", "30d", "90d". |
regions | string[] | no | Post-filter on listing-card region labels. Case-insensitive substring match against tags[]. WWR uses values like "Anywhere in the World" and "United States of America" (with flag emojis). |
jobTypes | string[] | no | Post-filter on employmentType[]. Multi-select array (e.g. ["Full-Time", "Contract"]). Distinct from Option B's URL-routing employmentType. |
minSalary | integer | no (default 0) | Post-filter — keep rows where salary.min >= minSalary OR salary is unspecified. Permissive on null/0 to avoid dropping jobs with no posted salary. USD. |
includeDescription | boolean | no (default true) | When false, drops description, descriptionHtml, descriptionText from output. Lighter dataset. |
cleanHtml | boolean | no (default false) | When true, emits only plain-text description (from our descriptionText); drops the HTML variants. Ignored when includeDescription is false. |
maxItems | integer | no (default 1000) | Hard cap on jobs collected. Non-paying users are capped at 100. |
maxConcurrency | integer | no (default 10) | Parallel job-detail fetches. |
minConcurrency | integer | no (default 1) | Min parallel fetches. |
maxRequestRetries | integer | no (default 5) | Retries per failed request. |
proxy | object | no (default RESIDENTIAL) | Apify proxy config. WWR blocks datacenter IPs — keep RESIDENTIAL. |
Output overview
One row per job. Schema is flat (no nested arrays of rows). Each row uses these fields:
- Identifiers:
jobId,identifier,url - Job info:
title,description,descriptionHtml,employmentType[],occupationalCategory[],jobLocationType,postedDate,validThrough - Company:
companyName,companyLogo,companyUrl,companyDescription - Geography:
applicantCountries[] - Compensation:
salary(object:currency,min,max,value,unit) - Application:
applyUrl,applyType,directApply - Meta:
ogImage,scrapedAt
Output samples
Job row (real smoke-test data, slightly truncated for display)
Key output fields
Identifiers
| Field | Description |
|---|---|
jobId | Stable slug pulled from JSON-LD identifier.value. Unique per job. Example: codesignal-software-engineer-business-experience-1. |
identifier | Full { "@type":"PropertyValue", "name":"{company}", "value":"{slug}" } object from JSON-LD. |
url | Canonical WWR job-detail URL. |
Job information
| Field | Description |
|---|---|
title | Job title. |
description | Full job description (HTML preserved). |
descriptionHtml | Same content but with double-encoded HTML entities normalised. |
employmentType[] | "Full-Time", "Part-Time", "Contract", "Freelance", etc. |
occupationalCategory[] | WWR category labels (e.g. "Full-Stack Programming", "Customer Support"). |
jobLocationType | Typically "TELECOMMUTE" (WWR is remote-only). |
postedDate | UTC posted timestamp. |
validThrough | When the posting expires. |
Company
| Field | Description |
|---|---|
companyName | Hiring organisation display name. |
companyLogo | URL to WWR-hosted small logo. |
companyUrl | Company's own website (when WWR provides it). |
companyDescription | Sometimes provided; often null. |
companyId | WWR company-profile URL, e.g. https://weworkremotely.com/company/walter. Populated when the URL was discovered via a listing card. |
location | Company HQ as a free-form string ("Brooklyn, NY", "Colombo, 1, Sri Lanka", "NYC and TLV"). Distinct from applicantCountries — that's where remote workers can apply from; this is where the company itself is based. |
Geography (the unique field)
| Field | Description |
|---|---|
applicantCountries[] | Array of country codes (often 200+ entries) the employer says they'll consider applicants from. Pulled from JSON-LD applicantLocationRequirements. No other Apify WWR scraper exposes this. |
Compensation
| Field | Description |
|---|---|
salary.currency | ISO currency code ("USD", "EUR", etc.). |
salary.min / salary.max | Parsed numeric range. 0/0 when the employer didn't specify. |
salary.value | Single numeric value (when a range isn't given). |
salary.unit | "YEAR", "MONTH", "HOUR", etc. |
Application
| Field | Description |
|---|---|
applyUrl | The external company-side apply URL from JSON-LD. This is the differentiator — competitors return WWR's locked button instead. |
applyType | "external" when an apply URL was found, otherwise "unknown". |
directApply | Real boolean (WWR's own claim about whether the apply flow is direct). |
❓ FAQ
What URLs can I paste?
Any weworkremotely.com URL. Listing pages (/remote-jobs, /categories/..., /remote-jobs/search?term=...) and direct job-detail URLs (/remote-jobs/{slug}-{numeric}) are both auto-classified.
Why does salary.min / salary.max sometimes read 0?
WeWorkRemotely uses 0 as a placeholder when the employer chose not to supply a salary range. The field is left as 0 (not omitted) so you can distinguish "no salary published" (0/0) from a real 0 (rare).
Does the actor need a proxy? WWR blocks Apify's datacenter IPs but works fine through RESIDENTIAL proxies (the default). Direct HTTP also works for small runs.
How does pagination work?
Category listings and search results paginate via ?page=N. The actor walks every page until maxItems is hit. The main /remote-jobs index is a single-page view (no pagination).
Is the applyUrl always external?
WWR's JSON-LD url field is the external apply URL on most jobs. A small number of jobs route apply through WWR itself — those return https://weworkremotely.com/... as the apply URL. We surface whatever WWR provides.
Why does the JSON-LD url field hold the apply URL, not the job URL?
Quirk of WeWorkRemotely's schema.org implementation. The canonical job URL is in our url field; the JSON-LD's url is what they treat as the "where to apply" link.
How fresh is the data?
Each run hits WWR live — no caching. scrapedAt is the per-row timestamp.
What's the difference between detail mode and listing-only mode?
- Detail mode (
includeDetailPages: true, the default) fetches every job's detail page and returns the full 23+ field schema, includingapplicantCountries[], parsedsalary, real externalapplyUrl, fulldescription,validThrough, etc. - Listing-only mode (
includeDetailPages: false) emits rows directly from the listing card — no detail fetch. Returns ~12 fields:title,companyName,companyLogo,companyId,location,tags,isFeatured,isBoosted,postedAge,url,scrapedFrom. About 30× faster when you just need a list of jobs + headlines. TheapplicantCountries,salary,description,applyUrlfields are absent. - A
listingOnly: truemarker is on every listing-only row so downstream consumers can tell them apart.
How do the countries and timeFilter filters work?
Both are post-filters applied client-side after scraping (WWR doesn't accept these as URL params). countries matches rows where applicantCountries[] contains any of the supplied ISO-2 codes (case-insensitive). timeFilter keeps rows where postedDate is within the selected window. Filtered rows are silently dropped — the run stats show how many.
Can I combine filters? Yes. Country + time filters are post-applied to all rows. Option B filters (category / keyword / employment type) determine which URL gets scraped; the post-filters then narrow down the results.
Can I get only new jobs in scheduled runs?
Not built-in (the JSON-LD doesn't carry a stable created-at the way some boards do — postedDate is what we have). For deduping across scheduled runs, store seen jobIds in a downstream system.
Support
- File an issue or feature request via the Apify Console Issues tab.
- For custom output shapes, additional filters, or scheduled feeds into a warehouse, open an issue describing the use case.
Additional Services
Need a remote-jobs dataset shaped to your pipeline? Custom integrations available:
- Custom output schemas — alternative field names, flattened structures, filtered subsets for warehouse loaders (Postgres, BigQuery, Snowflake).
- Webhook delivery — push new WWR jobs to Slack, Discord, your CRM, or any HTTP endpoint.
- Scheduled feeds — daily/weekly runs into S3, Google Sheets, or your DB.
- Multi-source bundles — combine WWR with other remote job boards (RemoteOK, JustRemote, Remotive) for full-coverage remote-job intelligence.
Reach out via the Apify Issues tab or contact memo23 on Apify.
Explore More Scrapers
Looking for related remote-work, jobs, or recruiting data? Other actors by the same maintainer:
- HiringCafe Scraper — All HiringCafe job postings with company info, salary, and remote/location filters
- Stepstone Search Scraper — DACH + EU jobs by URL or keywords
- Y Combinator Scraper — YC jobs + companies + founders, $1/1K
- LinkedIn Jobs Scraper — Public LinkedIn job listings by keyword + location
- Naukri Scraper — India's #1 job board with full job details + recruiter info
⚠️ Disclaimer
This Actor accesses publicly available data on WeWorkRemotely.com for legitimate research, market intelligence, recruiting, and business-analysis purposes. Use of this Actor must comply with WeWorkRemotely's Terms of Service and all applicable laws, including data protection regulations (GDPR, CCPA, etc.). "WeWorkRemotely" and "We Work Remotely" are trademarks of We Work Remotely, Inc. This Actor is not affiliated with, endorsed by, or sponsored by WeWorkRemotely. The Actor's authors are not responsible for any misuse. Users must:
- Respect rate limits and avoid overloading WeWorkRemotely's infrastructure
- Not use scraped data to violate user privacy or any platform terms
- Use the data in compliance with applicable jurisdictions
- Not republish scraped content in violation of copyright
We do not store any scraped data; the Actor returns it directly to your Apify dataset for your authorized use.
SEO Keywords
weworkremotely scraper, we work remotely scraper, weworkremotely jobs scraper, remote jobs scraper, remote work scraper, weworkremotely api alternative, remote programming jobs scraper, remote developer jobs scraper, remote marketing jobs scraper, remote customer support jobs scraper, telecommute jobs scraper, work-from-home jobs scraper, remote job listings api, remote job feed, job aggregator, remote recruiter tool, job board scraper, weworkremotely json export, weworkremotely csv export, apify weworkremotely scraper, remote job lead generation, applicant country eligibility, salary benchmarking remote, remote-first companies database
License
ISC. See package.json.