🔥Indeed Job Data Scraper🔥
Pricing
Pay per event
🔥Indeed Job Data Scraper🔥
Automate your job search data collection with the Indeed Jobs Scraper. Extract detailed job postings, company reviews, and salary information from Indeed efficiently.
Pricing
Pay per event
Rating
5.0
(1)
Developer

NextAPI
Actor stats
1
Bookmarked
69
Total users
27
Monthly active users
5.5 hours
Issues response
8 hours ago
Last modified
Categories
Share
Indeed Job Data Scraper
Unlock Indeed's massive job database with ease.
Indeed is the world's #1 job search engine, aggregating millions of job listings from thousands of company websites, job boards, and staffing agencies. This scraper extracts job listings with detailed descriptions, salary data, company information, and location details at scale. Perfect for job aggregators, recruitment platforms, and workforce analytics.
🌟 Why choose this Actor?
Built for comprehensive Indeed job intelligence, this Actor provides reliable access to the world's largest job aggregator.
| Feature | Indeed Job Data Scraper | Bright Data | Zyte |
|---|---|---|---|
| Pricing Model | ✅ $0.003/job | ❌ $500+/month | ❌ Enterprise only |
| No Commitment | ✅ Pay-per-result | ❌ Monthly contract | ❌ Annual contract |
| Unified Schema | ✅ Normalized output | ✅ Yes | ✅ Yes |
| Setup Complexity | ✅ No-code, 1-click | ⚠️ Technical setup | ❌ Complex setup |
| Indeed Focus | ✅ Specialized | ⚠️ Generic | ⚠️ Generic |
🏆 Key Features
📊 Indeed-Specific Data Extraction
- 🔍 Massive Job Coverage: Access Indeed's aggregated listings from thousands of sources—the largest job database globally.
- 💵 Salary Information: Extract salary ranges when available, with currency and pay period details.
- 📝 Full Job Descriptions: Complete requirements, responsibilities, and qualifications in markdown format.
- 🏢 Company Details: Company name, industry, website, and additional metadata.
- 🌍 60+ Countries: Indeed's global presence from US and UK to Germany, India, Australia, and beyond.
🎯 Use Cases
🔎 Job Aggregation
- Job Board Development: Build your own job portal by aggregating Indeed listings with structured data.
- Career Platform Integration: Power your career services platform with real-time job data.
- Job Alert Systems: Create automated job alert services for specific keywords and locations.
- Recruitment Automation: Feed structured job data into your ATS or recruitment tools.
📈 Job Market Analytics
- Skills Demand Tracking: Analyze job descriptions to identify trending skills and emerging roles.
- Geographic Hotspots: Map hiring activity by location to spot talent hubs and remote-friendly employers.
- Industry Reports: Generate data-backed whitepapers on hiring trends and job market movements.
- Salary Analysis: Compare compensation across roles, industries, and locations.
🏢 Competitive Intelligence
- Competitor Hiring Radar: Track which roles competitors post and at what frequency.
- Talent Market Mapping: Identify which companies are scaling (high job volume) vs. downsizing.
- Industry Benchmarking: Compare hiring patterns across industry peers.
🤖 AI & Automation Pipelines
- Job Matching Engines: Feed structured data into ML models for candidate-job relevance scoring.
- Career Chatbots: Power conversational AI with real-time job data from Indeed.
- Resume Optimization: Analyze job requirements to help candidates tailor their applications.
💰 Pricing
| Resource | Cost | Description |
|---|---|---|
| Actor Usage | $0.00001 | Charged for Actor runtime. Cost depends on resource consumption during execution. |
| Job Details | $0.00345 | Charged for each job posting scraped. Includes complete metadata such as salary, company, and location. This is a flat fee per job. |
Example Cost Calculation:
- Scraping "Frontend Developer" + "UX Designer" in Austin, TX
- 2 keywords × 150 jobs = 300 results → 300 × $0.00345 = $1.04 total
🧜 How it Works
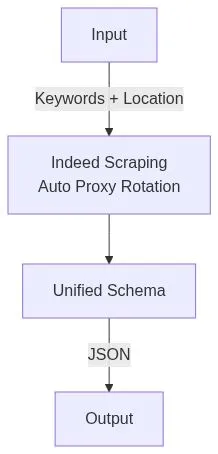
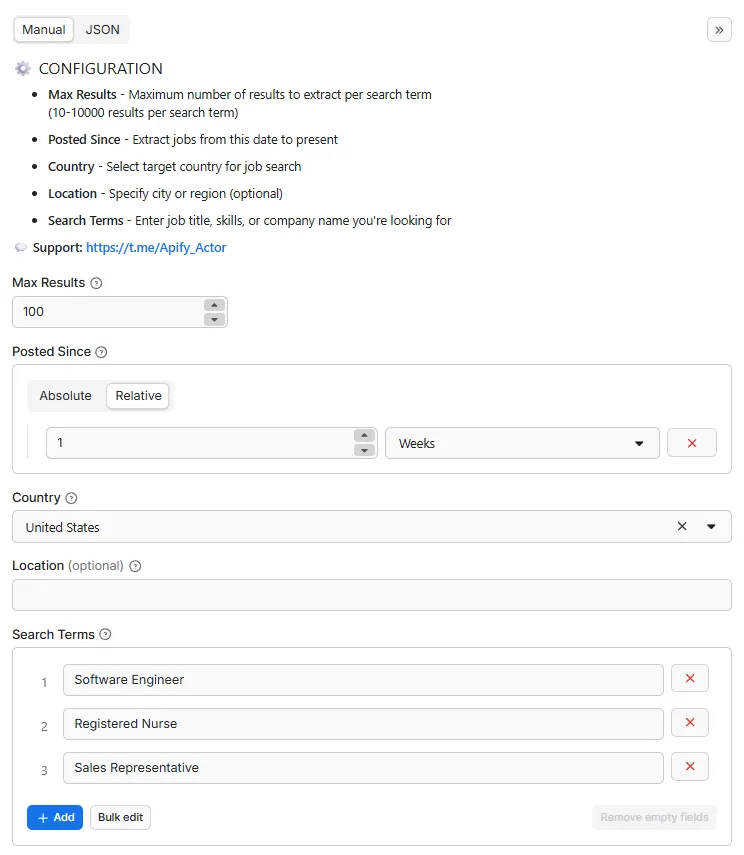
💻 Input Parameters
| Parameter | Type | Required | Description | Example |
|---|---|---|---|---|
search_terms | string[] | ✅ | Keywords to search: job titles, skills, or company names | ["Server", "Line Cook"] |
country | string | ✅ | Target country for job search (60+ countries supported) | United States |
location | string | ❌ | City or region within the country (optional) | Los Angeles |
posted_since | string | ✅ | Filter jobs posted within this period ("7 days", "1 months") | 1 months |
max_results | integer | ✅ | Number of jobs to fetch per keyword (min: 10) | 500 |
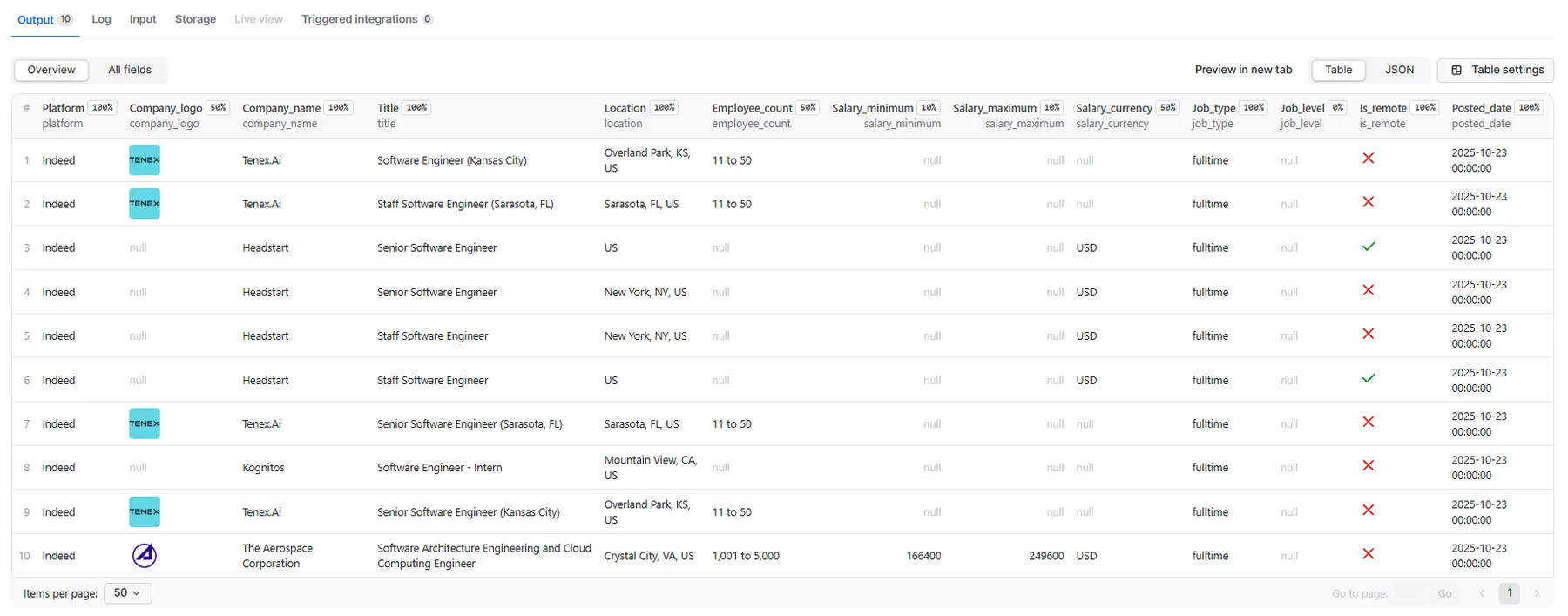
📤 Output Structure
📊 Output Fields Description
Job Information
| Field | Type | Description |
|---|---|---|
processor | string | URL of the Apify actor that processed this data |
processed_at | string | ISO 8601 timestamp when the data was processed |
platform | string | Source platform (Indeed) |
platform_url | string | Job URL on Indeed |
official_url | string | Direct link to company's job posting |
title | string | Job position title |
posted_date | string | Date when job was posted |
location | string | Job location or city |
is_remote | boolean | Whether the job allows remote work |
description | string | Full job description in markdown format |
job_type | string | Employment type (full-time, part-time, contract) |
job_level | string | Seniority level (entry, mid, senior, executive) |
job_function | string | Job category or function area |
listing_type | string | Type of job listing (standard, featured, sponsored) |
emails | string | Contact emails found in job posting |
skills | string | Required skills and technologies |
work_from_home | string | Work arrangement (remote, hybrid, on-site) |
vacancy_count | integer | Number of open positions |
experience_range | string | Required years of experience |
Salary Information
| Field | Type | Description |
|---|---|---|
salary_period | string | Payment period (yearly, monthly, hourly) |
salary_minimum | number | Minimum salary amount |
salary_maximum | number | Maximum salary amount |
salary_currency | string | Currency code (USD, EUR, GBP, etc.) |
Company Information
| Field | Type | Description |
|---|---|---|
company_name | string | Name of the hiring company |
company_industry | string | Industry sector of the company |
company_url | string | Company profile URL on job platform |
company_website | string | Official company website |
company_logo | string | URL to company logo image |
company_addresses | string | Company office locations |
company_revenue | string | Annual revenue range |
company_description | string | About the company |
company_rating | number | Company rating score (out of 5) |
employee_count | string | Number of employees |
review_count | integer | Number of company reviews |
🔌 Integrations
Seamlessly connect this actor to your existing pipelines via the Apify API.
🆔 Actor ID:
Python Client
Node.js Client
🦜 LangChain
Use this actor as a document loader in LangChain to power your RAG pipelines with job market data for career advice chatbots.
🏗️ Metadata for Developers (JSON-LD)
🚀 Performance Tips
Optimize your runs for speed, cost, and reliability with these best practices:
💰 Cost Optimization
- Start Small: Test with
max_results: 10and a single search term before scaling up. - Monitor Costs: Check the "Usage" tab in Apify Console for real-time cost tracking. Each job costs $0.00345.
- Narrow Search: Use specific job titles instead of broad keywords to reduce irrelevant results.
⚡ Speed Optimization
- Fewer Keywords: Each search term creates a separate search. Use focused keywords for faster results.
- Regional Focus: Specify a location to reduce results and speed up processing.
- Recent Posts: Use shorter
posted_sinceperiods (e.g., "7 days") for faster results.
🛡️ Reliability Best Practices
- Valid Country: Ensure the country name matches exactly (e.g., "United States", not "USA").
- Monitor Progress: Use Apify Console's live log to track scraping progress.
📊 Data Quality Tips
- Salary Data: Not all jobs include salary info. Filter by
salary_minimumfield to get jobs with disclosed salaries. - Fresh Data: Job postings change rapidly. Schedule daily runs for time-sensitive applications.
- Remote Jobs: Filter by
is_remote: trueor checkwork_from_homefield for remote opportunities.
❓ FAQ
How to export job listings to Excel?
After the run completes, go to the Output tab in the Apify Console. Click the Export button and select Excel format. You will receive a neatly formatted spreadsheet with all job listings ready for analysis.
How do I search for remote jobs only?
Currently, the actor fetches all matching jobs. Filter the results by checking the is_remote field (boolean) or work_from_home field for remote/hybrid opportunities.
Why are some salary fields empty?
Not all job postings include salary information. Indeed aggregates jobs from many sources, and salary disclosure varies by employer. Use the salary_minimum field to filter jobs with disclosed compensation.
How long does a typical scrape take?
Runtime depends on the number of search terms and max_results setting. A typical run with 2-3 keywords and 100 results completes in 1-3 minutes.
Why do some job titles not match my search keywords?
This is expected behavior. Indeed uses its own search algorithm that considers job relevance, not just exact keyword matching. The platform may return jobs based on:
- Related job titles and synonyms (e.g., "Developer" may return "Engineer" roles)
- Skills mentioned in job descriptions
- Industry and category associations
- Location-based relevance
This is the same behavior you would see when searching directly on Indeed.
⚖️ Legal & Compliance
This actor scrapes publicly available job postings only. It does not log in, access private data, or collect personal information of job seekers. You are responsible for adhering to each platform's Terms of Service and applicable privacy laws (GDPR/CCPA).
🏷️ Indeed Job Data Scraper
🔥 Search Terms: indeed scraper, indeed jobs api, indeed job listings, indeed salary data, job search api, indeed data extraction, job listings scraper, indeed job search, employment data api, job posting scraper, indeed automation, job market data, hiring data scraper, indeed job aggregator, recruitment data api, job board scraper, indeed job parser, workforce analytics, talent acquisition data, indeed job feed
💼 Use Cases: job-aggregation recruitment-automation job-market-research competitive-intelligence career-platform job-alert-system hr-analytics talent-acquisition workforce-planning job-matching salary-research hiring-trend-analysis job-board-development employment-data
🤝 Support & Community
- 📧 Support: Contact Us | 💬 Community: Telegram Group
🔗 Related Actors
- Job Search Engines - One API, multiple platforms. Aggregate job listings from LinkedIn, Indeed, Glassdoor, ZipRecruiter, and regional boards with unified schema. Smart region detection auto-selects optimal platforms.
- LinkedIn Job Data Scraper - Tap into the world's largest professional network. Extract applicant counts, company growth signals, skills taxonomy, and hiring team visibility unique to LinkedIn's ecosystem.
- Glassdoor Job Data Scraper - Unlock salary transparency and employer intelligence. Extract crowd-sourced salary ranges, company ratings, employee reviews, and workplace culture insights from Glassdoor.
- Indeed Job Data Scraper - Access the world's #1 job aggregator with millions of listings from thousands of sources. Extract salary data, full descriptions, and company details across 60+ countries.
- Reddit User Analyzer - Reconstruct complete digital personas from Reddit activity. Forensic timeline analysis, karma forensics, influence detection, and moderator role identification for OSINT research.
- Reddit Community Analyzer - Map any subreddit's DNA in seconds. Extract rules, wikis, stickies, complete comment trees with hierarchical structure, and granular upvote/downvote engagement metrics.
- Reddit Trends Analyzer - Spot viral content before it peaks. Real-time trend tracking, emerging topic detection, and sentiment analysis across Reddit's most active communities.
- Telegram Scraper - Extract member profiles from Telegram groups with dual modes. Standard extraction for public groups, Deep Search for hidden members and historical data discovery.
- Telegram Message - Scrape messages and download media from Telegram channels. Comprehensive analytics including views, replies, forwards, reactions, and full forwarding chain data.
- Telegram Profile - Batch extract profiles from users, bots, groups, and channels. MTProto-powered extraction with verification status, premium features, and detailed privacy settings.
- 4K Video Downloader - Download 4K/HD videos from YouTube, TikTok, Instagram, Twitter and 1000+ platforms. Unified JSON output with metadata, comments, and engagement analytics.
- TikTok Video Downloader - Download TikTok videos without watermarks in 4K/HD/SD. Extract trending hashtags, audio tracks, creator profiles, and viral engagement metrics.
- TikTok Live Recorder - Capture TikTok live streams with real-time analytics. Automated recording with viewer counts, streamer insights, and engagement tracking as it happens.
- Youtube Video Downloader - Professional YouTube video downloader with SEO analytics. Extract metadata, comments, thumbnails, and channel growth data for content strategy research.
- Video To Text - AI-powered video transcription across 1000+ platforms. Automatic language detection, time-stamped segments, and instant translation to 100+ languages.
- Social Media Marketing - Transform one video into 864 unique social posts. AI generates platform-optimized content with styled images across 12 platforms, 12 tones, and 6 AI models.
