Booking Scraper
Pricing
from $2.00 / 1,000 scraped place results
Booking Scraper
Scrape Booking with this hotels scraper and get data about accommodation on Booking.com. You can crawl by keywords or URLs for hotel prices, ratings, addresses, number of reviews, stars. You can also download all that room and hotel data from Booking.com with a few clicks: CSV, JSON, HTML, and Excel
🛎 What does Booking Scraper do?
This web scraping tool allows you to extract data from Booking.com, one of the best-known platforms for hotels, apartments, resorts, villas, and other types of accommodation worldwide.
Booking Scraper expands Booking data extraction beyond the official Booking.com limitations. It allows you to scrape over 1,000 basic listings data at once from the Booking.com. To scrape only the basic details of each listing, use our dedicated Fast Booking Scraper 🏎💨
🧳 What data can I scrape from Booking?
Our Booking Scraper is capable of extracting data such as:
| 🏖 Hotel names, descriptions and URLs | 📍 Full address |
| ⏱ Check-in and check-out times | 🛏 Room availability and room specs |
| 💵 Room prices | 🛁 Features of each listing |
| ✍️ Total number of reviews | ⭐️ Rating and stars |
| 🌆 Image URLs | 🧑🦰 Number of persons |
| 🗺 Hotel surroundings (nearby landmarks, transport, dining, beaches, airports) (add-on) | 🛏 Detailed room offerings (size, bed config, occupancy, facilities, photos) (add-on) |
⬇️ Input
For input, you can either specify a Destination ✈️ or use specific URLs from Booking.com website 🔗 (you can apply all the necessary filters on the website beforehand).
You can then configure the scraper on which content you want to scrape (property type, minimum rating, price range, currency, language, etc.) You can also set the range of check-in and check-out dates and how many results you want.
Enable the Scrape hotel surroundings & room offerings add-on to extract surroundings (nearby landmarks, transport, dining, beaches, and airports with distances) and roomOfferings (detailed room specs including size, bed configurations, occupancy, facilities, and photos) for each property. This is an optional paid add-on that requires an extra API call per hotel.
If you want a step-by-step tutorial on how to scrape Booking, read our blog post on how to scrape Booking.com or watch this quick video tutorial:
Tips for scraping hotels on Booking
1️⃣ Booking.com website will only display a maximum of 1,000 results so that’s how much the scraper can get at once. If you need more than that, you can use the Get more than 1000 results toggle. However, in that case, you won’t be able to apply any limiting filters in URLs because the scraper will override them. Scraping by Destination will not be affected by the toggle.
2️⃣ If you need to get detailed data about pricing or specific rooms, you need to provide checkIn and checkOut dates. The reason for this is that Booking.com only shows complete room and pricing info when dates are indicated.
3️⃣ Sometimes Booking.com may return some suggested hotels outside of the expected city/region as a recommendation. The scraper will return all of them in the data results, so you may get more results than expected for your search.
⬆️ Output example
The scraped Booking listings will be shown as a dataset which you can find in the Storage tab. Note that the output is organized as a table for viewing convenience:
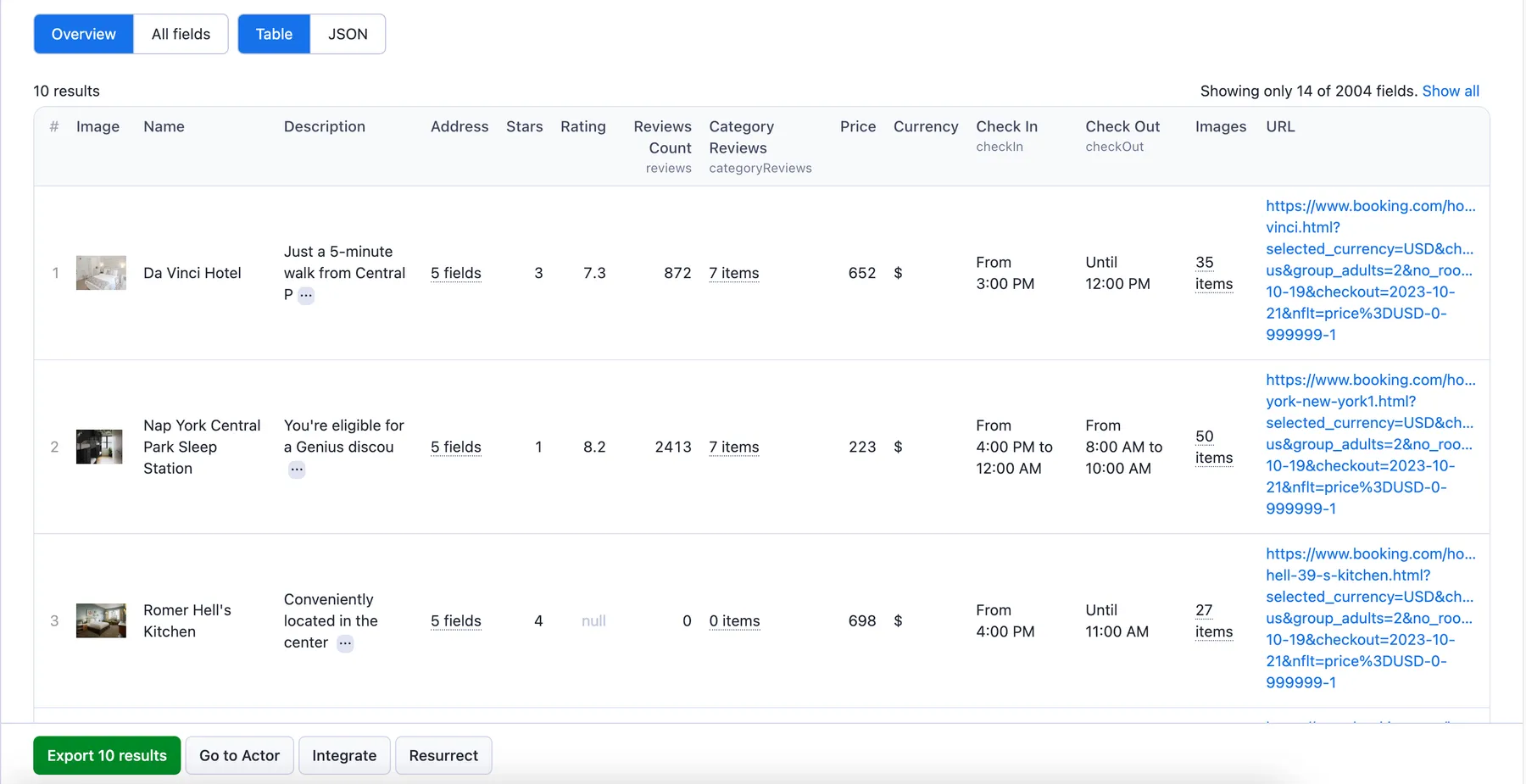
You can preview all the fields and choose in which format to download the data you’ve extracted: JSON, Excel, HTML table, CSV, or XML. Here below is the same dataset in JSON:
⭐️ Need to scrape reviews from Booking.com?
Use a dedicated ⭐️ Booking Reviews Scraper. It was built to extract review text, ratings, stars, basic reviewer info, length of stay, liked/disliked parts, room info, date of stay, and more for each listing.
❓FAQ
What are the disadvantages of the Booking API?
The Booking.com API interface is quite user-friendly, but getting that data in machine-processable format is no easy task. Booking.com places a lot of restrictions on how data can be collected from its listings, one of them being that Booking.com will display a maximum of 1,000 results for any given search. Our Booking Scraper doesn't impose any limitations on your results, so you can scrape data from Booking.com at scale.
Is it legal to scrape listings on Booking.com?
Yes. However, you should note that personal data is protected by GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. We also recommend that you read our blog post: is web scraping legal?
Can I integrate Booking Scraper with other apps?
Yes. Fast Booking Scraper can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate with Zapier, Slack, Make, LangChain, Airbyte, GitHub, Google Sheets, Google Drive, and and with other Actors. Or you can use webhooks to carry out an action whenever an event occurs, e.g. get a notification whenever this scraper successfully finishes a run.
Can I use Booking Scraper with API?
Yes. You can use Apify API to get programmatic access to the Apify platform. The API is organized around RESTful HTTP endpoints that enable you to manage, schedule, and run Apify actors. The API also lets you access any datasets, monitor Actor performance, fetch results, create and update versions, and more.
To access the API using Node.js, use the apify-client NPM package. To access the API using Python, use the apify-client PyPI package.
Check out the Apify API reference docs for full details or click on the API tab for code examples. You can also follow this video guide.