CORE Open Access Paper Search
Pricing
from $2.00 / 1,000 paper fetcheds
CORE Open Access Paper Search
Search and extract open access academic papers from CORE -- the world's largest aggregator of open access research with over 300 million metadata records and 40+ million full-text papers. Filter by keyword, year range, and language.
Pricing
from $2.00 / 1,000 paper fetcheds
Rating
0.0
(0)
Developer
Ryan Clinton
Maintained by CommunityActor stats
0
Bookmarked
5
Total users
3
Monthly active users
a month ago
Last modified
Categories
Share
CORE Open Access Research Corpus Intelligence
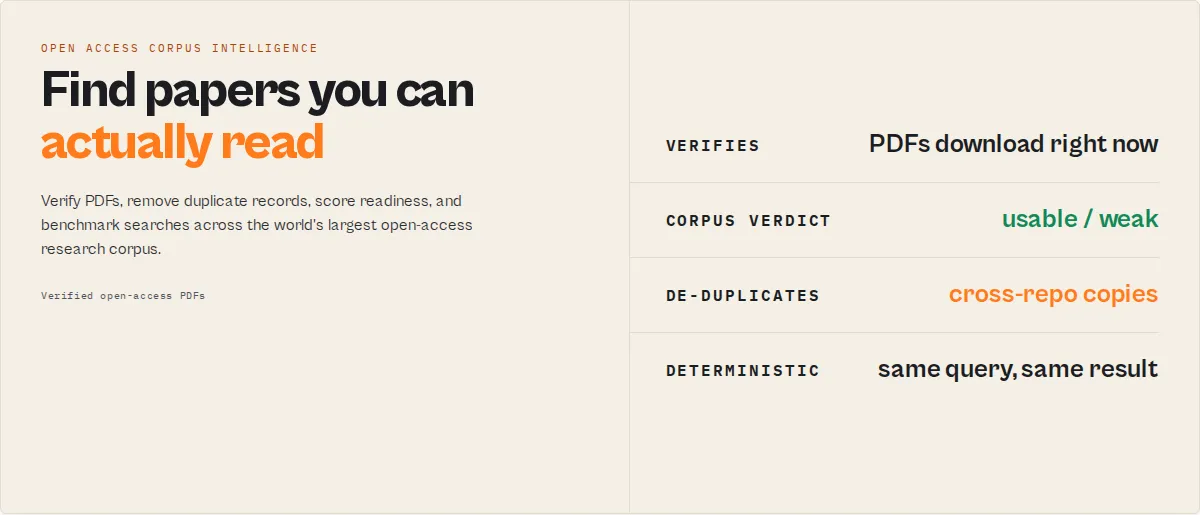
Find research papers you can actually read. Verify PDFs, remove duplicates, score readiness, benchmark searches, and monitor what changed -- all from CORE, the world's largest open-access research corpus (300M+ metadata records, 40M+ full-text papers, 10,000+ repositories). Requires a free API key from core.ac.uk.
Most academic search tools tell you what exists. This actor tells you what's actually usable: it verifies that each full-text PDF is downloadable right now, removes the duplicate records the same paper picks up across repositories, scores every paper for research readiness, highlights corpus weaknesses, and monitors what changed since your last search.
One run returns the answer, not just rows:
Ready-to-run examples
One-click published tasks — open one, add your free CORE API key, and run:
- Find downloadable open-access PDFs — search a topic and get only the papers whose full-text PDF is verified downloadable right now.
- Build a literature-review corpus — search, de-duplicate, and quality-gate into a read-ready dataset.
- Find recent open-access research — the latest cited open-access work on your topic.
- Find highly-cited open-access papers — the most-cited freely-downloadable work on your topic.
- Build a RAG paper corpus — verified-downloadable PDFs in a trimmed, ingestion-ready shape for retrieval pipelines.
- Compare two research searches — run two queries and see which one produces the better open-access corpus.
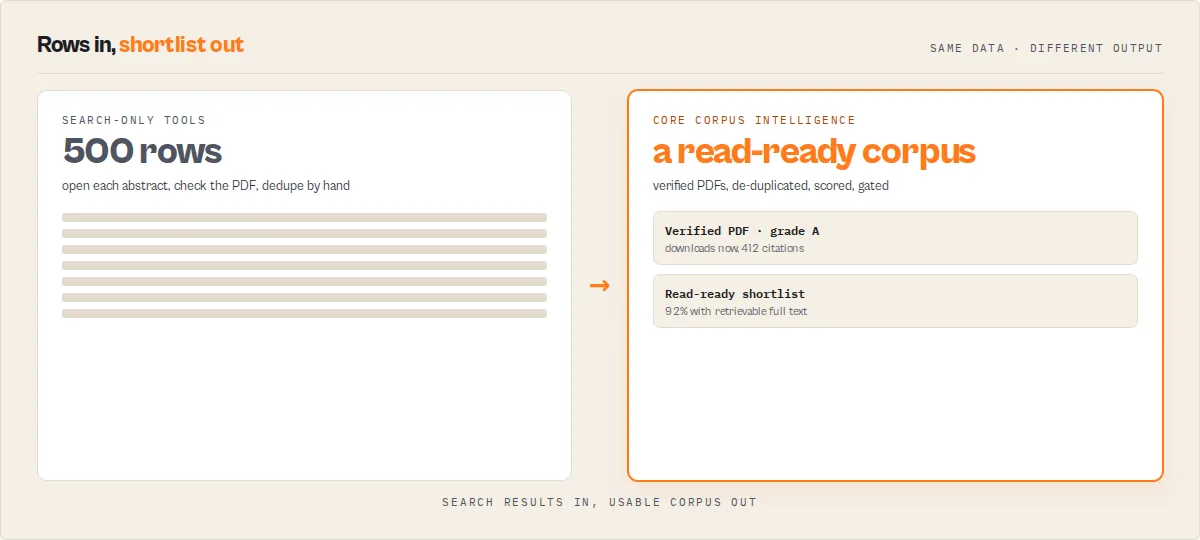
What does CORE Open Access Paper Search do?
CORE Open Access Paper Search is an Apify actor that connects to the CORE API v3 to search and retrieve structured metadata from the world's largest collection of open access research outputs. CORE harvests content from over 10,000 institutional repositories, journal publishers, and preprint servers across the globe, providing programmatic access to more than 300 million metadata records and over 40 million full-text papers.
This actor lets you search that massive corpus by keywords, filter results by publication year range and language code, and optionally restrict output to only papers that have a downloadable full-text PDF. Each result carries the full CORE metadata -- title, author list, abstract, DOI, journal name, publisher, field of study, citation count, document type, language, and direct links to both the CORE page and the downloadable PDF -- plus an intelligence layer: a full-text retrievability classification, a research-readiness score and grade, the hosting repositories, cross-repository duplicate detection, and a corpus-summary digest of the whole result set.
The actor handles multi-page API responses automatically using offset-based pagination with built-in 200ms delays between requests to stay within CORE's usage policies. You can retrieve up to 500 papers per run.
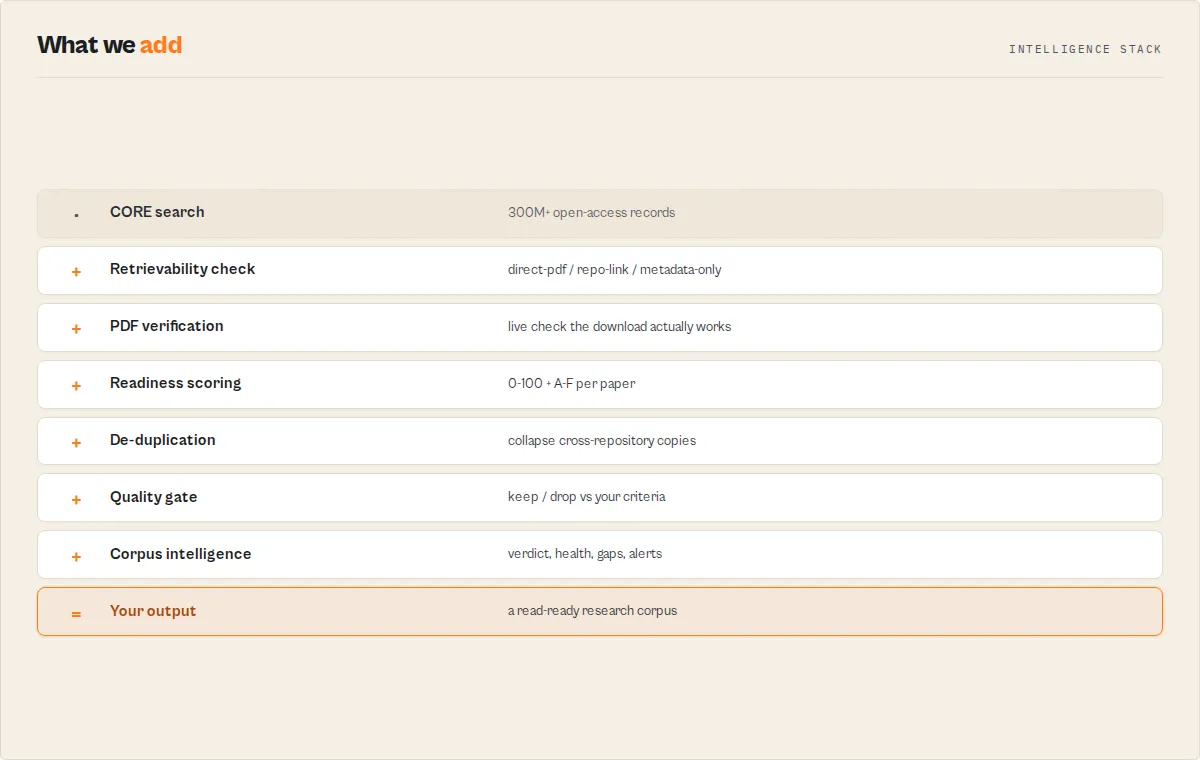
Core capabilities
- Optional PDF verification -- when enabled (
head-check), a live check confirms each open-access full text is downloadable right now, not just that a link exists; dead links are flagged with the reason - Research-readiness scoring -- a 0-100 score and A-F grade per paper (full-text availability + citations + recency + completeness), with a plain-English breakdown of how the score was reached
- Corpus health + verdict -- one number and one sentence tell you whether the search produced a usable corpus
- Quality gates -- keep/drop every paper against your acceptance criteria (grade, require PDF, citations, age, duplicates), with reasons
- De-duplication -- the same paper harvested across repositories is flagged (
doi/strict/fuzzy) so your distinct-paper count is honest - Monitoring -- track a topic across scheduled runs and detect new papers, citation changes, and papers that just became openly readable
Advanced
- Benchmarking -- compare two searches side-by-side on corpus health (which query gives the better corpus?)
- Search diagnostics -- honest, computable reasons a search under-performed (low result count, single-repository concentration, no recent papers, low PDF availability)
- Collections -- the result set pre-sorted into
readReadyPapers,highlyCited,foundational,recent,alerts, andduplicatesbuckets - Advanced query builder -- exact phrases, must-include / must-exclude, author, publisher, minimum-citations, no CORE syntax required
- Repository intelligence -- which of 10,000+ repositories host each paper, the source type, and a retrievability-strength signal
- Reproducible fingerprint, research presets, export packages (KV), and output modes / profiles
Why use CORE Open Access Paper Search on Apify?
Running this actor on the Apify platform gives you several advantages over calling the CORE API directly:
- No infrastructure needed. The actor runs in the cloud. No servers to manage, no dependencies to install, no pagination logic to write.
- Scheduled runs. Configure the actor to run on a daily, weekly, or custom schedule to automatically monitor new publications matching your query.
- Built-in integrations. Export results directly to Google Sheets, Slack, Zapier, Make, webhooks, or any other system through the Apify integration ecosystem.
- Scalable data collection. Retrieve up to 500 papers per run with automatic pagination across multiple API pages, all handled transparently.
- Structured output. Results come as clean, normalized JSON records ready for analysis, database import, or feeding into downstream actors and workflows.
- API and SDK access. Trigger runs and retrieve results programmatically using the Apify API or official Python and JavaScript client libraries.
- Dataset management. Store, version, and export datasets in JSON, CSV, Excel, XML, or RSS formats directly from the Apify console.
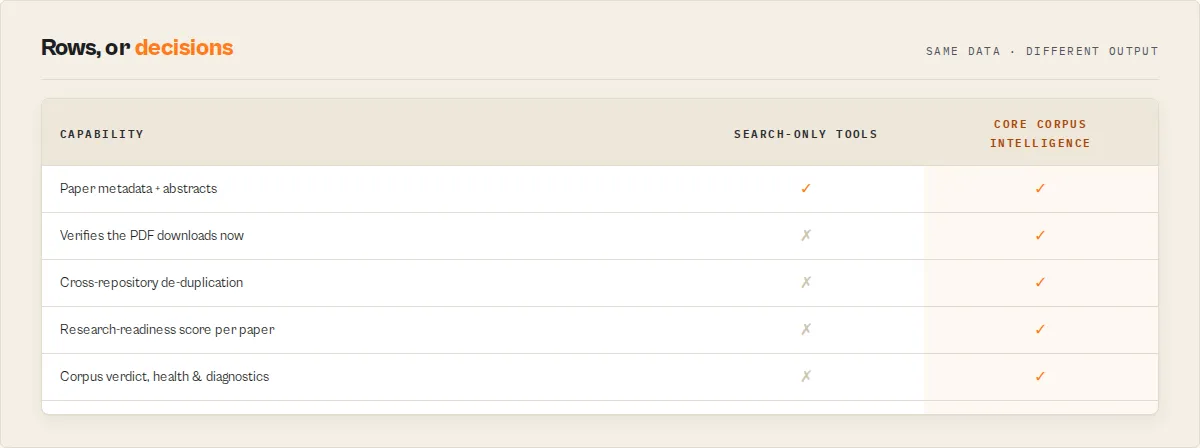
What this actor does and does not do
This actor's job is open-access full-text intelligence: it tells you which papers you can actually read right now, where the PDF lives, how clean and retrievable the corpus is, and what changed since last time. It deliberately does not try to be everything, because purpose-built sibling actors own the adjacent jobs:
| If you need... | Use instead |
|---|---|
| Clinical evidence hierarchy (RCT / systematic review / meta-analysis), MeSH terms | PubMed Biomedical Literature Search |
| Field impact, landmark/rising papers, institutions, funders, competitive landscape, topic momentum | OpenAlex Research Radar |
| Citation-influence ranking and citation graphs | Semantic Scholar Paper Search |
| Full-text-mined biological entities (genes, diseases, chemicals) and dataset accessions | Europe PMC Literature Search |
| Bulk publisher metadata and DOI resolution across all disciplines | Crossref Academic Paper Search |
It does not assign clinical evidence levels (CORE has no study-design metadata), does not compute field-normalized impact or topic-growth rates (those need the whole field, not a result-set sample), and does not rank papers by citation influence. What it does, no citation-graph or metadata-only tool can: verify that the open-access full text is reachable right now and map which of 10,000+ repositories hosts it.
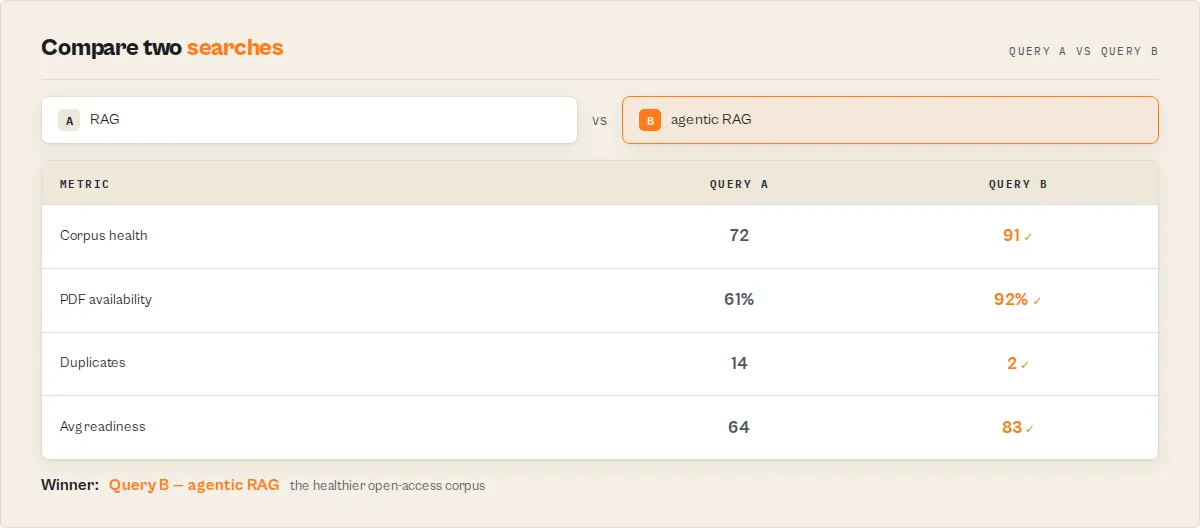
Compare research strategies
Most academic tools search. This one lets you compare searches. Set a compareQuery and the run benchmarks both queries on open-access corpus health, side by side, and tells you which one produces the better corpus to work from. Add outputMode: "benchmark" to get just the comparison table (one row per metric, charged as a single event):
Researchers refining a literature-review query, analysts choosing a topic framing, and teams tuning a monitoring search all do this by hand today. Here it is one input.
Every run also produces a reproducible searchFingerprint -- a stable hash of the resolved query and filters -- so you can cite exactly how a corpus was produced and reproduce it later.
How to get a free CORE API key
This actor requires a CORE API key for live searches. The key is completely free to obtain:
- Visit https://core.ac.uk/services/api
- Click "Register" and create an account
- After registration, your API key will be available in your CORE dashboard
- Copy the key and paste it into the
apiKeyfield when configuring this actor
The free tier provides generous daily request limits that are more than sufficient for most research and data collection workflows.
If you run the actor without providing an API key, it performs a dry run -- returning a message that confirms your query configuration and explains how to register for a key. This lets you verify your input settings before committing to a live search.
Input parameters
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
apiKey | String | No | -- | Your CORE API key. Register free at core.ac.uk/services/api. Without a key, the actor performs a dry run. |
query | String | Yes | -- | Keywords to search for in academic papers. Supports Boolean operators (AND, OR, NOT). |
researchPreset | String | No | none | One-pick intent that sets defaults for the gate, dedupe, filters, and monitoring: literature-review, state-of-the-art, historical-foundations, thesis-sources, monitoring. Your explicit settings override it. |
exactPhrases | Array | No | -- | Phrases that must appear verbatim in results. |
mustInclude | Array | No | -- | Terms that must all be present. |
mustExclude | Array | No | -- | Terms to exclude (e.g. "survey", "review"). |
titleOnly | Boolean | No | false | Match the main query against titles only. |
author | String | No | -- | Filter to papers by a matching author name. |
publisher | String | No | -- | Filter to papers from a specific publisher. |
minCitations | Integer | No | -- | Only return papers with at least this many citations. |
yearFrom | Integer | No | -- | Filter papers published from this year onwards (e.g., 2020). |
yearTo | Integer | No | -- | Filter papers published up to and including this year (e.g., 2025). |
language | String | No | -- | ISO 639-1 language code to filter results (e.g., "en", "de", "fr", "es", "zh"). |
fullTextOnly | Boolean | No | false | When enabled, only papers with a downloadable full-text PDF are returned. |
documentTypes | Array | No | -- | Keep only papers whose document type matches one of these (e.g. "research", "thesis"). |
repository | String | No | -- | Keep only papers hosted by a repository whose name contains this text. |
compareQuery | String | No | -- | A second query to benchmark against the main query on open-access corpus health. Emits a benchmark record. Runs a second CORE search. |
maxResults | Integer | No | 50 | Maximum number of papers to retrieve per run (up to 500). |
pdfVerification | String | No | none | none, url-present (flag link existence, no network call), or head-check (live HEAD request per PDF to confirm it is downloadable now). |
qualityGate | Object | No | -- | Acceptance criteria, e.g. { "minGrade": "B", "requirePdf": true, "minCitations": 5, "maxAgeYears": 8, "excludeDuplicates": true }. Each paper gets a keep/drop gate decision. |
dropFiltered | Boolean | No | false | When the quality gate is set, exclude dropped papers from the dataset (still counted in the summary). |
dedupeMode | String | No | doi | none, doi, strict (DOI + normalized title/author/year), or fuzzy (+ near-identical title detection). |
watchlistName | String | No | -- | Name a watchlist to track papers across scheduled runs. Each paper is flagged NEW the first time it appears, SEEN afterwards, with changedFields. Leave blank for one-off searches. |
watchlistMode | String | No | flag-all | flag-all, new-only, or changed-only -- which papers to emit when a watchlist is set. |
outputMode | String | No | papers | papers returns one record per paper plus a corpus-summary digest. corpus suppresses the per-paper rows and returns only the digest (charged as a single event). |
outputProfile | String | No | standard | minimal keeps headline decision fields, standard adds authors/citations/repositories/recency/provenance, full includes the abstract, scoring breakdown, and all source URLs. |
Input example
Output format
The dataset carries up to four record types, distinguished by recordType:
| Record | Purpose |
|---|---|
paper | One paper plus its intelligence layer (retrievability, readiness, provenance, dedupe) |
corpus-summary | Corpus verdict, health, diagnostics, and composition for the whole run |
collections | The result set pre-sorted into ready-to-use buckets |
benchmark | Side-by-side comparison of two queries (only when compareQuery is set) |
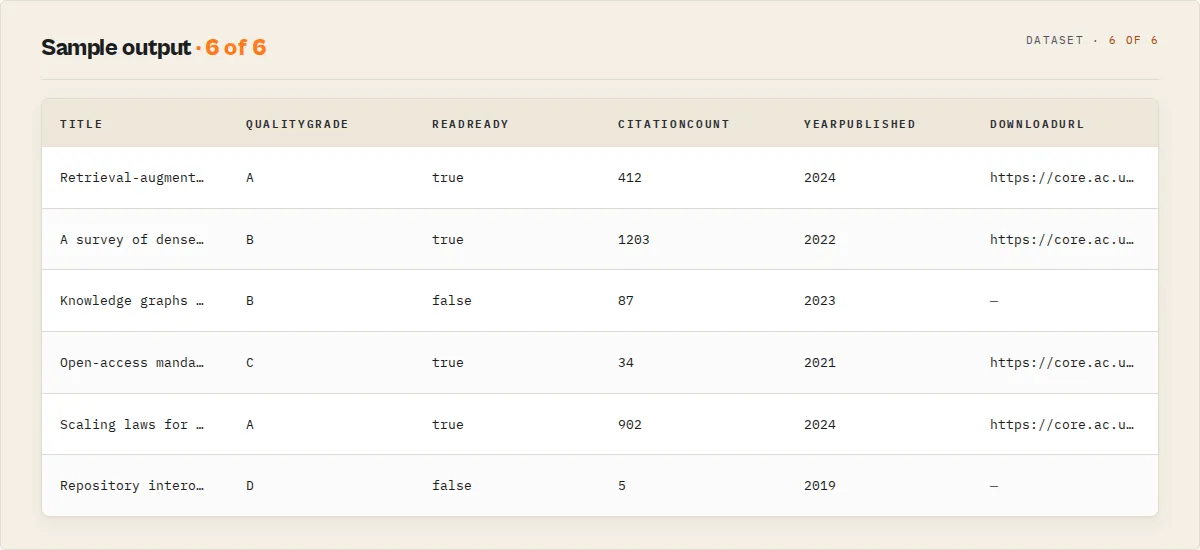
paper records
Alongside the raw CORE metadata (coreId, doi, title, authors, abstract, yearPublished, publisher, journalName, downloadUrl, sourceFulltextUrls, fieldOfStudy, citationCount, language, documentType, coreUrl), each paper carries an intelligence layer:
| Field | Type | Description |
|---|---|---|
repositories | Array of Strings | Names of the open-access repositories hosting this paper |
openAccess | Object | { fullTextAvailable, retrievability, repositoryCount, readReady }. retrievability is direct-pdf, repository-link, or metadata-only |
readReady | Boolean | True when a direct full-text PDF can be downloaded immediately |
pdfStatus | Object or null | Present when pdfVerification is enabled: { urlPresent, httpStatus, contentType, contentLength, verifiedAt, failureReason }. failureReason names a dead link, non-PDF type, or timeout |
provenance | Object | { repositories, repositoryCount, crossHosted, sourceType, provenanceStrength, preferredSource, preferredRepository }. sourceType is repository / publisher / preprint / thesis / unknown; provenanceStrength is strong / moderate / weak; crossHosted is true when 2+ repositories host it |
authorMetrics | Object | { authorCount, singleAuthor } |
qualityScore | Number | 0-100 research-readiness composite (full text + citations + recency + completeness) |
qualityGrade | String | A (>=80), B (>=65), C (>=50), D (>=35), F (<35) |
qualityFactors | Object | The four score components, summing to qualityScore (full profile only) |
scoreExplanation | Array | Plain-English read-back of how the score was reached, one line per factor |
citationTier | String | highly-cited, cited, low-citation, uncited, or unknown |
citationsPerYear | Number or null | Citations normalised by paper age (freshness-aware density) |
recency | Object | { ageYears, band }; band is current, recent, established, historical, or unknown |
relevanceRank | Number | 1-based position in CORE's relevance-ordered result set |
dedupe | Object | { isDuplicate, canonicalKey, duplicateReasons[] } per dedupeMode (doi / strict / fuzzy) |
gate | Object or null | Present when qualityGate is set: { status: "keep" | "drop", reasons[] } |
watchlist | Object or null | Present in watchlist mode: { name, status, firstSeenAt, lastSeenAt, seenCount, changedFields[] }. changedFields can include citationCount, retrievability, becameReadable |
summary | String | One-line plain-English summary an LLM can quote without joining fields |
The corpus-summary record also gains kept / droppedByGate (quality-gate counts), pdfVerifiedCount / pdfDeadLinkCount (when verification ran), sourceTypeBreakdown, and changedCount (watchlist). Five export packages are written to the run's key-value store: SUMMARY, PDF_READY, DUPLICATES, NEW_PAPERS, and FAILED_PDF_CHECKS.
corpus-summary record -- Research Corpus Intelligence
This is the actor's signature output. Every run answers four questions about the corpus as a whole, deterministically and with no LLM:
corpusVerdict-- can I trust this search? (usable/mixed/weak, one sentence)corpusHealth-- how good is the corpus? (0-100, PDF-availability-centered, with a component breakdown)diagnostics-- why did it under-perform? (plain-English reasons)coverageGaps-- what's missing? (machine-readable{ code, detail })
Alongside those, the digest carries the composition (totalHits, retrieved, distinctPapers, duplicateInflation, openAccessRate, readReadyRate, documentTypeBreakdown, yearRange, yearHistogram, topRepositories, topPublishers, topFieldsOfStudy, sourceTypeBreakdown, citationLeaders, avgQualityScore, qualityGradeDistribution), severity-ranked alerts (watchlist mode), a reproducible searchFingerprint, and (in watchlist mode) newCount / changedCount. It is also mirrored to the SUMMARY key in the run's key-value store.
Output example (paper record, standard profile)
How to use CORE Open Access Paper Search
Step 1: Get your free API key
Register at core.ac.uk/services/api to obtain a free CORE API key. The registration takes less than a minute.
Step 2: Configure your search
Enter your API key, search query, and any optional filters. You can test your configuration first by leaving the API key blank -- the actor will perform a dry run and confirm your query settings without making any API calls.
Step 3: Run the actor
Click "Start" in the Apify console, or trigger the run programmatically via the API. The actor will search CORE, paginate through all matching results, and push structured paper records to the output dataset.
Step 4: Export your results
Download the dataset in JSON, CSV, Excel, XML, or RSS format. You can also connect integrations to automatically forward results to Google Sheets, Slack, Zapier, Make, or your own webhook endpoint.
How much does it cost to run?
This actor is API-only -- no browser rendering -- so platform compute is minimal: a typical run uses 256-512 MB RAM and finishes in seconds to a couple of minutes depending on how many papers you fetch. The CORE API key is free with generous daily limits. You pay the actor's per-paper pricing plus negligible Apify compute; enabling head-check PDF verification adds one lightweight HTTP request per paper.
Programmatic access
You can trigger this actor and retrieve results programmatically using the Apify API or the official client libraries.
Python
JavaScript
cURL
Tips for best results
-
Use specific search terms. Broad queries like "science" or "biology" will match millions of records. Use precise phrases, combine multiple keywords, or use Boolean operators (AND, OR, NOT) directly in the query field for more targeted results.
-
Combine year filters with keywords. If you are tracking recent developments in a field, set
yearFromto the current year or the last few years. This dramatically narrows the result set and improves relevance. -
Enable the full-text filter when you need PDFs. If your workflow involves downloading and reading actual papers, set
fullTextOnlyto true. This ensures every result in your output has a workingdownloadUrlpointing to the full-text PDF. -
Use language filtering for non-English research. CORE indexes papers in dozens of languages. Use the language filter with ISO 639-1 codes (e.g., "de" for German, "fr" for French, "zh" for Chinese, "es" for Spanish) to find research that may be underrepresented in English-centric databases.
-
Test with a small maxResults first. Start with 10-20 results to verify your query returns relevant papers before scaling up to 500. This saves time and lets you iterate on your search terms quickly.
-
Schedule regular runs. Set up a recurring schedule on Apify to monitor new publications matching your query on a daily or weekly basis. Combine with Slack or email integrations to get notified when new papers are found.
-
Use Boolean operators in queries. The CORE API supports AND, OR, and NOT operators directly in the query string. For example:
"deep learning" AND "medical imaging" NOT surveywill find deep learning papers about medical imaging while excluding survey papers. -
Leverage the dry-run mode. Before entering your API key, run the actor without one to confirm that your query and filter settings are configured correctly. The dry-run output will show you the exact query that would be sent to CORE.
FAQ
Do I need a CORE API key to use this actor?
Yes, a CORE API key is required for live searches. Without one, the actor performs a dry run and returns a message explaining how to register. The key is completely free -- register at core.ac.uk/services/api and you will receive your key immediately.
What is CORE and how is it different from Google Scholar?
CORE (COnnecting REpositories) is the world's largest aggregator of open access research papers, harvesting content from over 10,000 data providers worldwide. It indexes more than 300 million metadata records and over 40 million full-text papers. Unlike Google Scholar, CORE focuses exclusively on open access content -- meaning every paper indexed is freely available to read and download. CORE also provides a structured API, making it ideal for programmatic access and bulk data retrieval.
Can I download the full PDF of papers?
Many papers in CORE have direct PDF download links. When you enable the fullTextOnly filter, the actor only returns papers that have a confirmed downloadable full-text URL. The downloadUrl field in the output contains the direct link to the PDF file. Additionally, the sourceFulltextUrls array may contain alternative download locations from the original repository or publisher.
How many papers can I retrieve per run?
The actor supports up to 500 papers per run. For larger datasets, you can run the actor multiple times with different queries, year ranges, or language filters, and merge the results using Apify's dataset management features or your own downstream processing pipeline.
What fields can I use for filtering?
You can filter by keyword query (which searches across titles, abstracts, and full text), publication year range (yearFrom and yearTo), and language code. The CORE API also supports advanced query syntax -- you can use Boolean operators (AND, OR, NOT) directly in the search query field for more precise control over your results.
What happens if a search returns zero results?
If your query has no matches, the actor will complete successfully and produce an empty dataset. Try broadening your search terms, removing year or language filters, or disabling the full-text filter to increase the number of matches.
How often is the CORE index updated?
CORE continuously harvests new content from its data providers. New papers are typically indexed within days of being deposited in a participating repository. Scheduling this actor to run regularly will help you capture newly indexed papers as they appear.
What languages are supported?
CORE indexes papers in dozens of languages. Use standard ISO 639-1 language codes in the language field: "en" (English), "de" (German), "fr" (French), "es" (Spanish), "pt" (Portuguese), "zh" (Chinese), "ja" (Japanese), "ko" (Korean), "ru" (Russian), "it" (Italian), "nl" (Dutch), "pl" (Polish), and many more.
Use cases
Systematic literature reviews
Researchers can use this actor to build comprehensive literature review datasets. Search by topic keywords, filter to a specific year range, and export the results to a spreadsheet for screening and annotation. The structured output with DOIs and download links makes it easy to locate and retrieve the full papers.
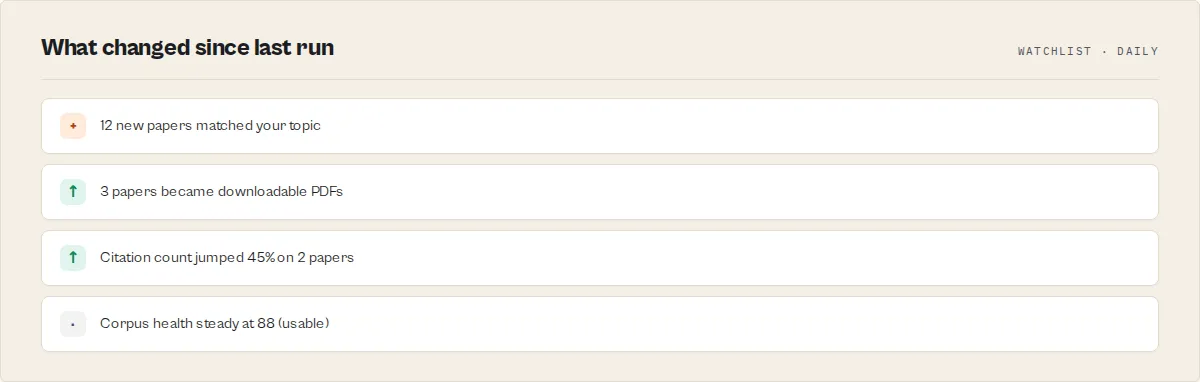
Research monitoring and alerting
Schedule the actor to run daily or weekly with your research topic as the query. Connect a Slack or email integration to get notified whenever new open access papers matching your interests are published. This is particularly useful for staying current in fast-moving fields.
Academic dataset construction
Build structured datasets of academic papers for bibliometric analysis, scientometric research, or training machine learning models. Every record provides rich metadata including citation counts, fields of study, and document types, plus the readiness score, citation tier, and full-text retrievability classification that are valuable for quantitative research analysis and corpus filtering.
Competitive intelligence in research
Track what competitors, collaborators, or specific institutions are publishing by combining author names or institution keywords in your search queries. Monitor publication trends in your field to identify emerging topics and key contributors.
Open access compliance monitoring
Universities and research funders can use this actor to verify that funded research is being deposited in open access repositories. Search by grant keywords or author names and check the availability of full-text PDFs.
Content curation and knowledge management
Build curated collections of open access papers for educational resources, reading lists, or internal knowledge bases. The structured metadata makes it easy to organize and categorize papers by field of study, year, or document type.
Use in Dify
Drop this actor into Dify workflows via the Apify plugin's Run Actor node. Each paper returns scored, classified, and retrievability-tagged as structured JSON — direct-pdf / repository-link / metadata-only plus the readiness grade (A-F) your downstream node branches on. A generic scraper pointed at an academic site returns the rendered HTML of a results page; this returns decisions about whether each paper is worth reading and whether you can actually read it.
- Actor ID:
ryanclinton/core-academic-search - Sample input (find readable, high-readiness papers on a topic):
Branching example
A Dify if/else node routes on the stable enums each paper record carries:
openAccess.retrievability == "direct-pdf"→ send to a PDF-ingest / summarise branch (the full text is downloadable now).openAccess.retrievability == "repository-link"→ send to a "resolve via repository" branch.openAccess.retrievability == "metadata-only"→ drop or queue for a different source — there is no readable full text.qualityGrade in ("A", "B")→ keep for the reading list;"D"/"F"→ discard low-readiness results.watchlist.status == "NEW"(watchlist mode) → push only papers unseen since the last scheduled run into an alert branch.
The corpus-summary record (one per run) gives a node the run-level read without touching individual papers: branch on openAccessRate, distinctPapers, or avgQualityScore to decide whether the search was good enough to proceed.
Opt-in modes Dify workflows can leverage: outputMode: "corpus" returns only the digest (one object, charged once) for a "is this topic well-covered in open access?" gate; watchlistName turns the actor into a monitoring node that flags only new papers; outputProfile: "minimal" trims each record to the headline decision fields so an LLM node reads less. The summary string on every paper is a ready-to-quote line — no LLM rewriting needed.
Integrations
This actor works seamlessly with the Apify platform's integration ecosystem:
- Google Sheets -- Automatically export paper metadata to a spreadsheet for collaborative review and analysis.
- Slack -- Get real-time notifications when new papers matching your query are found during scheduled runs.
- Email -- Receive email digests of newly discovered papers on a recurring schedule.
- Zapier / Make -- Trigger downstream workflows whenever new academic papers are collected.
- Webhooks -- Push results to your own API endpoint for custom processing and storage.
- Amazon S3 -- Store datasets in your own S3 bucket for long-term archival and analysis.
- Google Drive -- Save output files directly to Google Drive for team access.
- GitHub -- Use the Apify API in CI/CD pipelines or research automation scripts.
Data source and acknowledgement
This actor is powered by CORE, a not-for-profit service of the Knowledge Media Institute at The Open University, United Kingdom. It accesses CORE through the official CORE API using your own CORE API licence, and every result links back to its source record on CORE via the coreUrl field. CORE data is provided for machine processing; please review and comply with CORE's terms for your use case.
Related actors
If you are working with academic research data, these related Apify actors may be useful for your workflow:
| Actor | Description |
|---|---|
| Semantic Scholar Paper Search | Search Semantic Scholar for AI-powered academic paper discovery with citation graphs and influence scores. |
| OpenAlex Research Paper Search | Search the OpenAlex database for academic works, authors, institutions, and research topics. |
| PubMed Biomedical Literature Search | Search PubMed and MEDLINE for biomedical and life science research papers with MeSH term filtering. |
| Crossref Academic Paper Search | Search Crossref for scholarly metadata across all academic disciplines with DOI resolution. |
| ArXiv Preprint Paper Search | Search ArXiv for preprint papers in physics, mathematics, computer science, and quantitative biology. |
| Europe PMC Literature Search | Search Europe PMC for life science literature, patents, and clinical guidelines. |
| DBLP Publication Search | Search DBLP for computer science publications, conference proceedings, and journal articles. |
| ORCID Researcher Search | Look up researchers by ORCID ID to find their publication history and affiliations. |